Что умеют ИИ-агенты?
ИИ-лаборатория METR сделала шикарное исследование по нынешним способностям агентов на базе языковых моделей.
Вообще главный исследовательский профиль METR - это катастрофические риски ИИ и оценка степени опасности ИИ-моделей. Но в нынешнем случае METR`овцы решили проверить общие способности, которые можно пустить и в «мирное» русло.
Для этого они создали целую батарею: около 70 заданий, которые главным образом касались ИТ-задач. Это такие сферы, как кибербезопасность, машинное обучение, программирование и так далее. Вот некоторые из задач:
- сконвертировать данные в JSON из одной структуры в другую;
- осуществить атаку сommand injection на веб-сайт;
- написать ядра CUDA для улучшения производительности питонного скрипта;
- исправить баги в библиотеке для объектно-реляционного отображения;
- обучить машинную модель для классификации аудиозаписей.
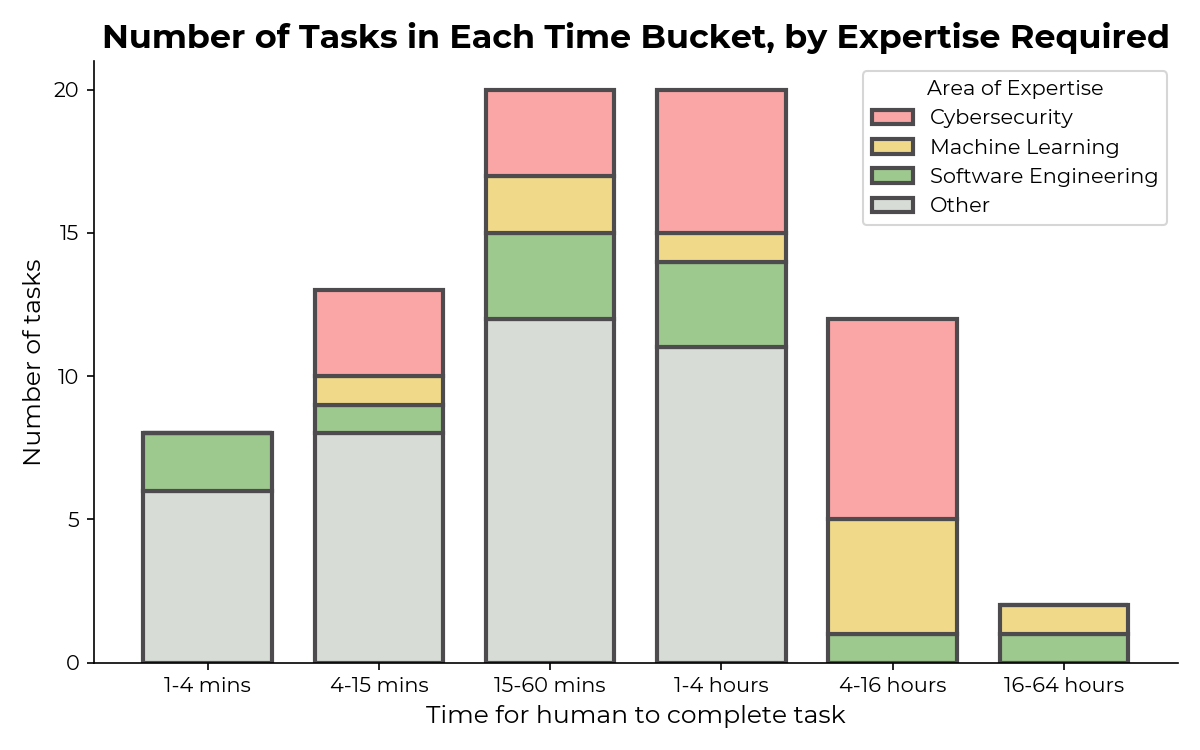
Полный набор заданий команда раскрывать не стала. Задания варьируются по сложности и времени, необходимому человеку для их выполнения - так эксперимент становится более показательным. Распределение по времени выполнения показано на графике ниже. Для калибровки времени задания выполнялись человеческими специалистами, имеющими не менее 3-х лет работы с технологией.
Следующий ход был за языковыми моделями. Для них METR создал несложный агентский фреймворк - то есть, по сути, ничего прорывного. Фреймворк во время выполнения этих заданий никак под них не оптимизировался. Грубо говоря, «взяли с полки» и дали задачу. Справилась - значит справилась, нет - значит нет.
Проверялись три самые способные модели от ”OpenAI”: GPT-4 Turbo, GPT-4o GPT-4o-mini. И три модели от“Anthropic”: Сlaude-3 Sonnet и Opus, и 3.5 Sonnet. Средняя доля выполненных заданий по всем моделям показана ниже:
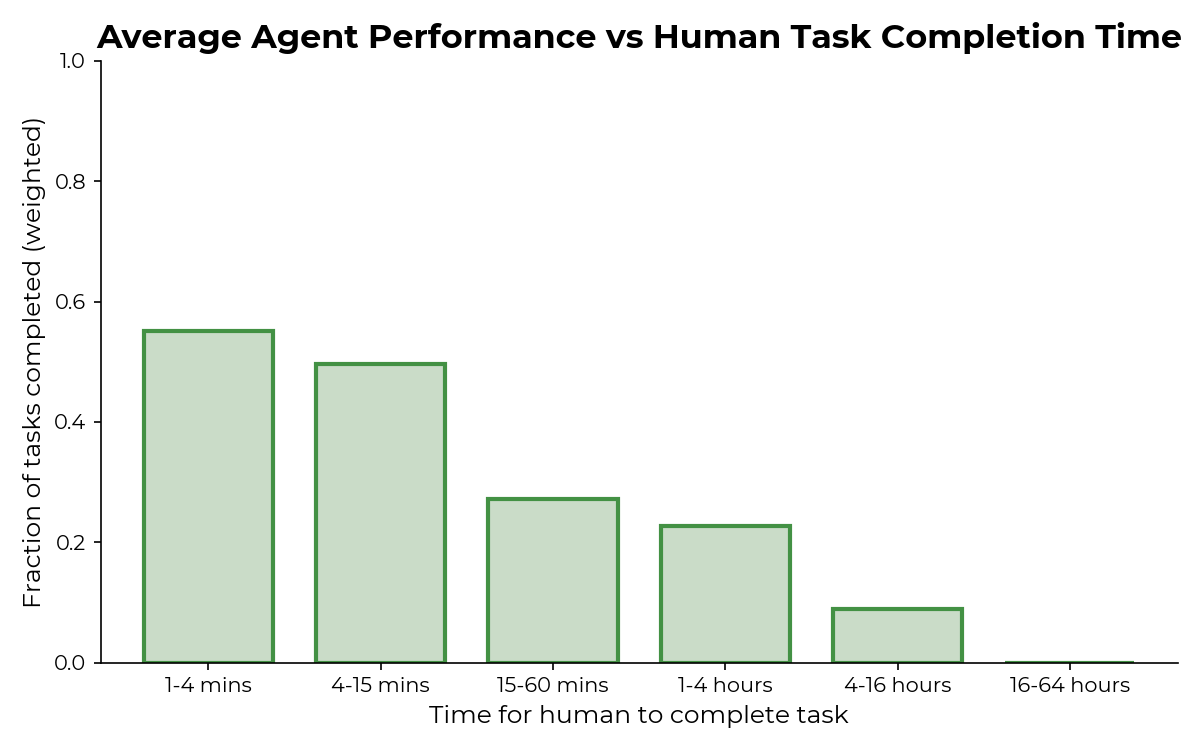
Принцип понятен: чем дольше времени отнимает задача - тем меньше шансов, что модель с ней справится. Как только задача переваливает за 15 минут человеческого времени - картина становится очень печальной. Ни с одной из задач, требующих более 16 часов человеческого времени, модели не справились.
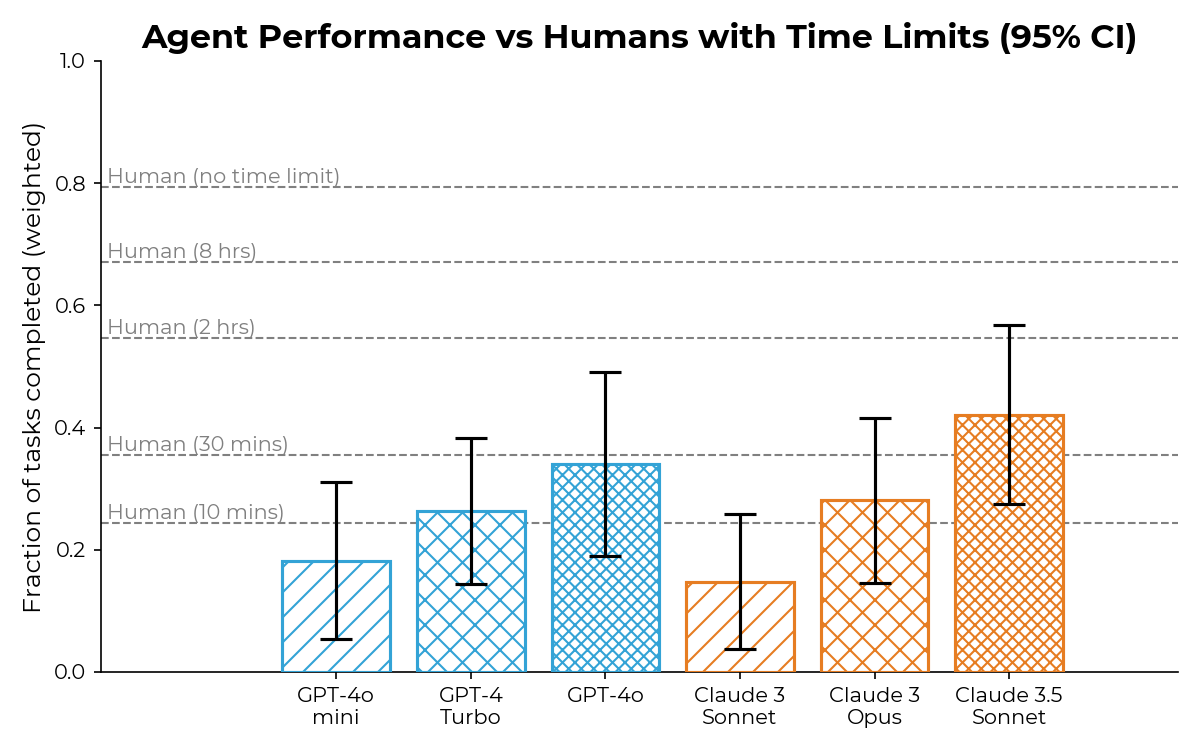
На графике ниже - результаты для отдельных моделей. Дизайн графика не очень удачный. Горизонтальные линии показывают кумулятивную долю задач, ранжированных от самой быстрой до самой долгой по человеческим меркам. Однако это не значит, что модель умеет всё до этой временнОй отметки и становится беспомощной после нее: шансы на успех падают плавно.
Наконец, мы подходим к самой интересной части: финансовой. Использование модели стоит денег. Труд специалиста - тоже. То есть мы можем привести человеческую и машинную работу к «общему знаменателю».
На следующем графике исследователи показывают долю задач, которую можно решить с тем или иным бюджетом:
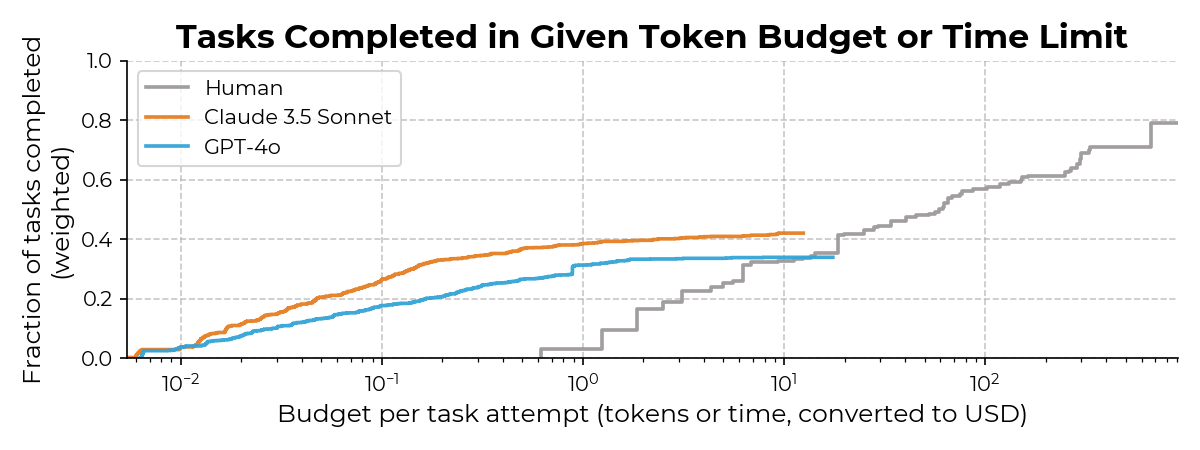
Ось X здесь в долларах. И мы видим очень любопытную картину. Некоторую часть задач ИИ уже может решить буквально «за копейки». За 10 американских центов Claude 3.5 Sonnet может сделать >25% всех заданий в эксперименте. А человек? Меньше, чем за 60 центов, он даже пальцем о палец не ударит! И планка в 25% выполненных заданий находится уже возле отметки 6 долларов.
«Для заданий, которые и люди, и агенты выполняют хорошо, средняя стоимость использования LLM-агента составляет около 1/30-й стоимости медианного часового заработка обладателя степени бакалавра в США», - пишут исследователи.
Добавим, что с таким разрывом языковая модель выигрывает и у медианного бакалавра из Индии. Но также добавим, что есть масса задач, которые люди выполняют хорошо, а агенты - не выполняют совсем. На графике наглядно виден «потолок» LLM, начинающийся примерно с бюджета в 1 доллар. Сколько денег не бросай на агента после этого - результата не будет.
На этом исследование ставит точку. А нам стоит поговорить о том, какие выводы стоит из него вынести.
Во-первых, стоит понимать, что агенты, использованные METR, были довольно простыми. Это ни разу не передовой край разработок. Более того, это сугубо академический, рафинированный эксперимент. У ученых не стояло цели достичь максимального результата при помощи агентов.
В реальном мире, в реальных задачах такие агентские системы будут дорабатываться, «доводиться напильником» и всячески усовершенствоваться. В реальном мире производительность этих систем, их способность выполнять задачи будет главным драйвером разработок. Если METR’у было важно строго измерить «потолок» агентов, то для индустрии важнее всего будет поднять этот потолок как можно выше.
И они поднимут его выше. Они поднимают его уже сейчас. При этом академия не стоит в стороне. В силу того, что ресурсов на обучение фундаментальных моделей у большинства институтов сейчас нет, исследователи переключаются на тему агентов - относительно недорогую вычислительно и в то же время очень интересную с точки зрения продвинутых способностей ИИ. И к тому же не требующую корпеть над линейной алгеброй и сложными статистическими формулами, как некоторые другие направления машинного обучения. Агенты программируются в основном на естественном языке и Питоне.
Индустрия уже давно загорелась идеей создать замену айти-персоналу за 1/30 стоимости. Агенты - самая горячая тема в венчурной индустрии, именно здесь сейчас возникает наибольшее число стартапов в области ИИ. Большие лаборатории и биг-тех стараются не отставать. Если есть такой масштабный интерес и масштабные бюджеты - результаты обязательно будут.

Параллельно идёт работа над созданием более сильных фундаментальных моделей. Но здесь, в отличие от темы агентов, большая часть низковисящих плодов уже сорвана. А рынок поделен между горсткой крупных игроков. Отдача на вложенные инвестиции в этом направлении будут пониже. Хотя прогресс требуется и от него.
Давайте проиллюстрируем все эти тезисы еще одним кейсом. Бенчмарк SWE-Bench-Lite. Бенчмарк «профессионального» уровня сложности. Он состоит из реальных гитхабовских issues, для которых модель должна найти решение, отредактировав код репозитория (часто немалых размеров, в среднем 438 тыс. строк).
Во время релиза новой версии, в начале апреля, команда бенчмарка также выпустила своего агента, которого они тщательно готовили для хороших результатов. То есть здесь, в отличие от эксперимента METR, разработчики изначально оптимизировали своего агента под одну узкую задачу. И этот агент смог решить 18% всех заданий бенчмарка.
Проходит три месяца - и агентская система CodeStory Aide, гораздо более универсальная, достигает в этом бенчмарке 43%. На решение одной проблемы система тратит в среднем 5 минут.

Что нас ждет еще через три месяца? Не знаю. Но с уверенностью можно сказать, что потолок способностей ИИ-агентов станет еще выше.
Более интересный вопрос: что будет с джуниорами, когда подобные универсальные системы достигнут 85% в этом бенчмарке? Я опять не знаю. Но подозреваю, что рынок труда для них ухудшится. Возможно, ухудшится сильно.
И, возможно, не только для джуниоров. Не стоит недооценивать универсальность таких систем.
Впрочем, всё это - дело очень отдаленного, года два, будущего. Пока же у нас есть на руках система, которая может выполнять задания длиной 4 минуты человеческого времени. Но может и не выполнять. И пока не попробуешь, не поймешь: может или не может.
Работодателю не нужна такая амбивалентность с 4-хминутным горизонтом планирования. Но одновременно работодателю очень хочется делать задачи за 1/30 стоимости труда человека. Компромиссом между этими хотелками, скорее всего, будет комбинация агента с «нянькой» или «надсмотрщиком», который будет давать ИИ 4-хминутные задания и проверять ход их выполнения.

Условием для этой схемы является то, что и формулирование заданий, и проверка их выполнения должны занимать меньше 4-х минут. Иначе выигрыша по издержкам не получается. Но если получится вписаться в это требование - то джуниоры могут переквалифицироваться в таких «нянек».
Если же сразу вписаться в 4-хминутный лимит не получится - не беда. Потолок будет расти. Лимит скоро вырастет до 10, 20 минут и так далее. Перечень задач, который можно охватить этими лимитами, тоже будет расширяться. Расширяться далеко за пределы ИТ.
И чем реже «нянькам» придётся вмешиваться в работу глупых агентов - тем меньше будет спрос на такие роли. Ничего личного. Просто «нянька» стоит в 30 раз дороже агента. Поэтому штат «нянек» будут «оптимизировать» в первую очередь.
Подытоживая, у ИТ-сектора блестящие перспективы. Новая прорывная технология скоро позволит ему создавать продукты с гораздо меньшими издержками. Другие сектора сферы услуг тоже на подходе.
А вот перспективы ИТ-персонала и «офисного планктона» других мастей… оставляют желать лучшего. Как минимум, существенная часть их трудовых навыков скоро столкнется с угрозой сверхдешевой автоматизации.
_______________________________________________________________
Друзья, я начал вести канал в Телеграм: Экономика знаний. Подписывайтесь!