Восемь экспонент искусственного интеллекта (2)
<< Начало: 1. Вычислительная сложность ИИ
2. Вычислительный бюджет на обучение ИИ
Концепция машинного обучения, в рамках которой сейчас создаются практически все алгоритмы ИИ, отдаленно похожа на принципы человеческого обучения. Модели даётся пример какой-то задачи, она пытается ее решить и учится на своих ошибках.
Если же мы преследуем цель создать общий искусственный интеллект, круг задач, которые он должен уметь решать, расширяется кардинально. Машине нужно уметь очень и очень много. А раз ей нужно уметь очень и очень много, ей нужно очень много учиться.
И здесь мы упираемся в специфическое ограничение: нынешние алгоритмы учатся весьма и весьма неэффективно. Обучение даётся им тяжело. Чтобы освоить любую задачу, им надо переработать большое количество обучающих примеров. А если таких задач много - объем информации, который требуется поглотить машине, приобретает гигантские масштабы.
К концу 2010-ых годов «ручное» создание обучающих материалов для машинных моделей уперлось в свои пределы: крупнейшие наборы таких данных включали миллионы обучающих примеров, каждый из которых требовал затрат человеческого труда. И при всей трудоёмкости создания такого набора, он мог обучить алгоритм лишь одному узкому навыку.
Выходом из ситуации стало использование для обучения любых доступных данных в изначальном виде, без какой-либо обработки - например, гигантского массива скачанных из интернета веб-страниц, или взятых оттуда же изображений. Конечно, такой «образовательный материал» не мог сравниться в качестве со специально созданными обучающими датасетами.
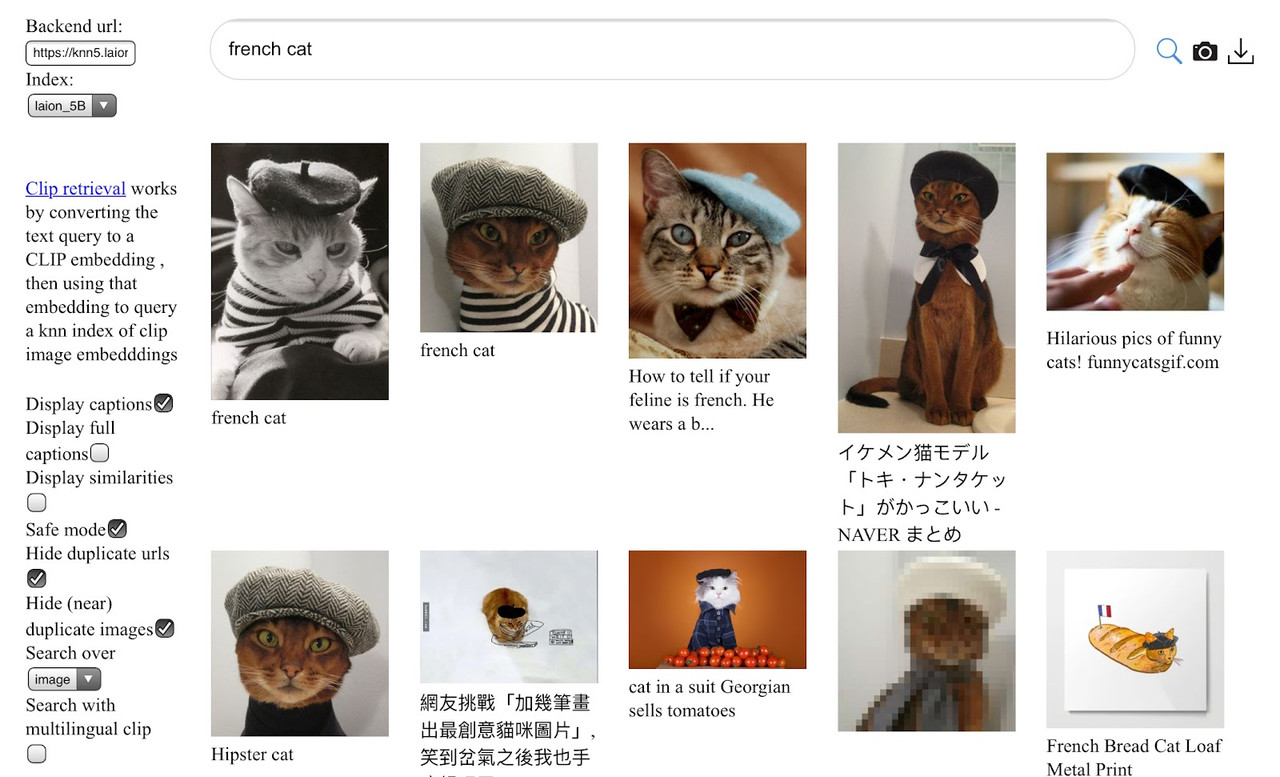
"Французские котики" из гигантского датасета LAION-5B. Проблемы с качеством видны уже во втором ряду изображений
Но то, что он терял в качестве, он с лихвой компенсировал в количестве. Оказалось, что такой упор на количество был как раз тем, что нужно неэффективным в плане учебы алгоритмам. Более того, отказавшись от какой-либо обработки данных, в том числе тематической фильтрации, и скармливая машине всё подряд, исследователи преодолевали и проблему узости навыков ИИ.
Как говорил Пушкин, мы все учились понемногу, чему-нибудь и как-нибудь. Машины же учатся чему-нибудь и как-нибудь помногу. Очень помногу. И чем более «помногу» они учатся - тем более сильные интеллектуальные навыки они демонстрируют. Таким образом, возникает еще одно «количественное» направление масштабирования способностей ИИ: объем данных, использованных для его обучения.
Здесь, как и в теме масштабирования размера модели, уже появилось множество научных работ, исследующих зависимость интеллектуальных способностей модели от количества освоенных ею данных. Одна из влиятельных таких работ была выпущена ”OpenAI” в 2020. Работа постулировала:
«...при вычислительно-оптимальном обучении размер датасета не должен расти быстрее, чем D ∝ N^2/3, с более разумной медианной оценкой D ∝ N^0.4»,
где D - количество обучающих данных и N - число параметров модели.
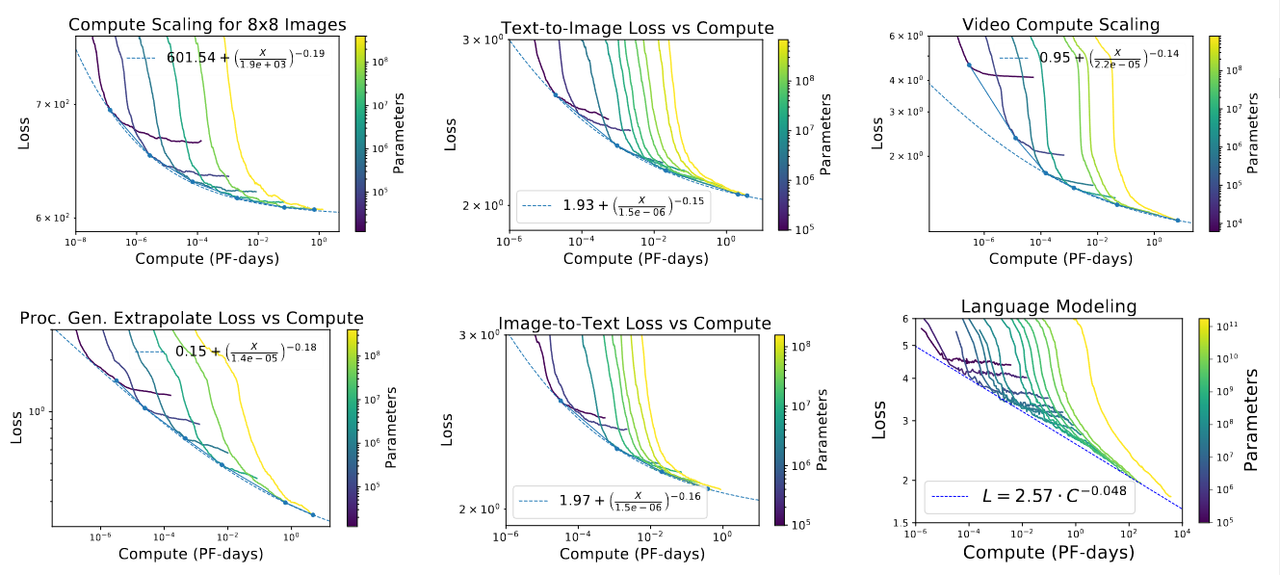
А это графическое представление проведенных "OpenAI" экспериментов
Найденная закономерность означала, что при 10-кратном росте числа параметров необходимо увеличивать объем обучающих данных в 10^0,4=2,5 раза. Это «задним числом» оправдывало сногсшибательный темп роста размеров моделей с 2016 года: получалось, что отдача от этого роста была гораздо выше при тех же вычислительных затратах на обучение.
При этом получалось, что вычислительный бюджет на обучение должен расти геометрически, со скоростью N * N^0,4 = N^1,4. При росте параметров в 10 раз бюджет вырастает в 25 раз.
Но вскоре эта закономерность была существенно пересмотрена. Работа от исследователей из «Дипмайнд», вышедшая в 2022, доказывала, что для улучшения модели необходимо наращивать параметры и обучающие данные примерно в одной и той же пропорции. Более того, авторы рассчитали, что предыдущие языковые модели были обучены на слишком малом объеме данных. И гнаться за ростом числа параметров сейчас нет смысла: надо эффективнее осваивать потенциал моделей меньшего размера.
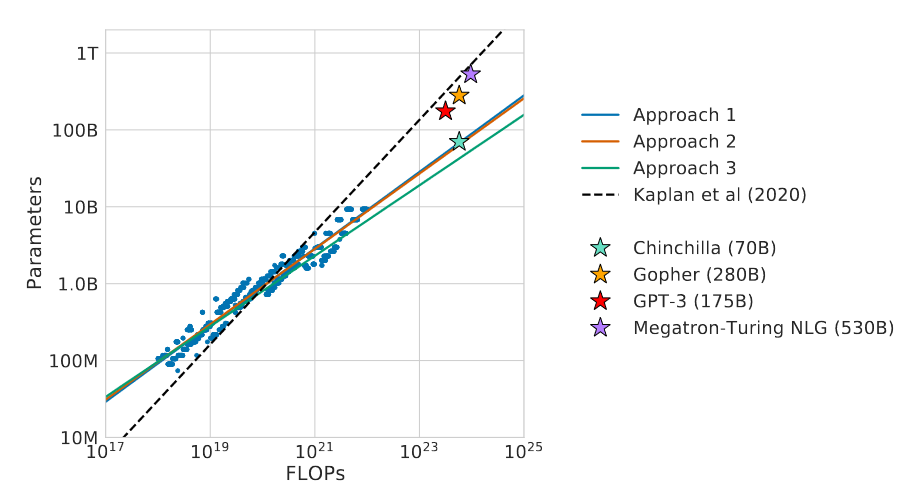
Черный штрих-пунктир - оптимальное масштабирование, получившееся у "OpenAI" в 2020. Цветные прямые - уточненные результаты от "Дипмайнд". Обратите внимание, что они более пологие. Это означает, что объем вычислений на обучение должен расти больше, чем предполагалось ранее.
Новая закономерность стала широко известна как «масштабирование по Шиншилле» (Шиншиллой назвали модель, которую «Дипмайнд» обучил по этому правилу). И эта закономерность означает, что вычислительный бюджет при росте числа параметров должен расти квадратически. То есть рост параметров в 10 раз требует роста бюджета в 100 раз.
Более поздние исследования по этой теме незначительно уточнили эту закономерность и подтвердили фундаментальный принцип квадратического роста вычислительного бюджета.
Уточненные правила масштабирования стали важной причиной, по которой размер моделей затормозил свой рост с 2022 года. Поскольку оказалось, что и размер модели, и количество обучающих данных одинаково важны, в дальнейшем анализе мы можем опираться на интегральный показатель масштабирования ИИ-алгоритмов: объем вычислений, затраченный для обучения моделей.
В этом анализе нам поможет работа Дж. Севильи «Compute Trends Across Three Eras of Machine Learning». Её обобщенные результаты представлены на этом графике:
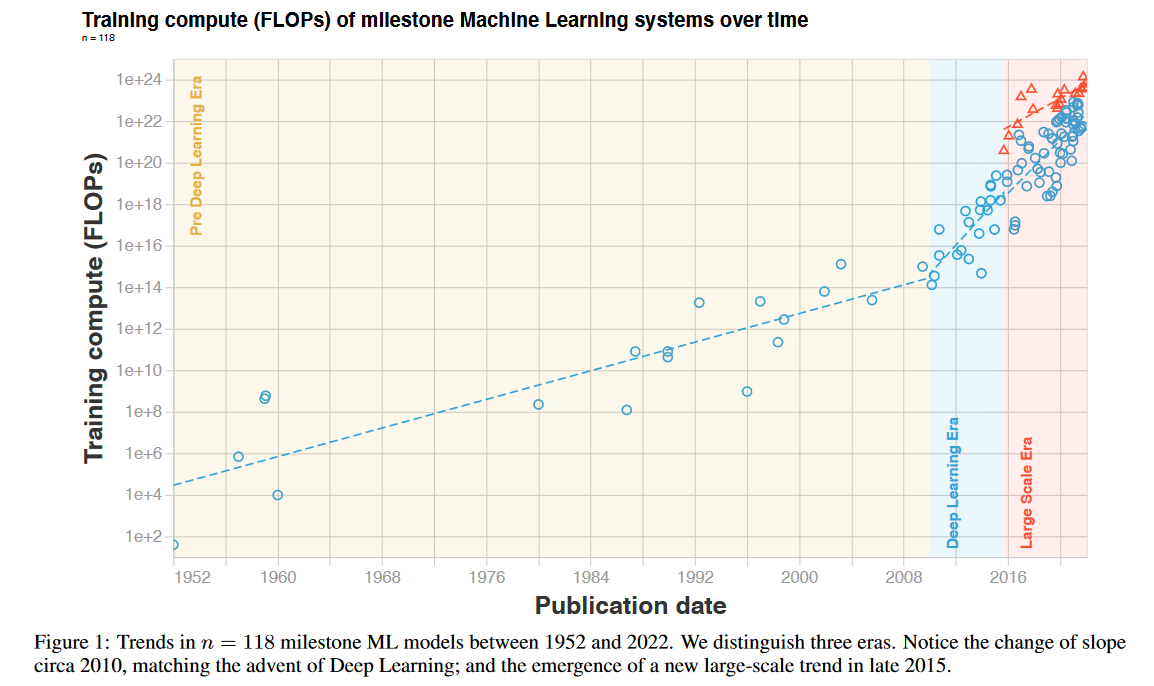
Исследователи выделяют три «эры», три режима роста вычислительных бюджетов. Первая эра продолжалась до революции глубокого обучения, примерно до 2010. Для нее было характерно удвоение бюджетов каждый 21 месяц. Что примерно соответствует темпу закона Мура.
Вторая эра - эра глубокого обучения, 2010-2015 (либо, в альтернативной трактовке, вплоть до сегодняшнего времени). Вычислительные бюджеты здесь удваивались очень быстро - примерно раз в полгода.
Наконец, третья эра, на которую мы обратим самое пристальное внимание - эра больших масштабов. Посмотрим на эту часть графика в деталях:
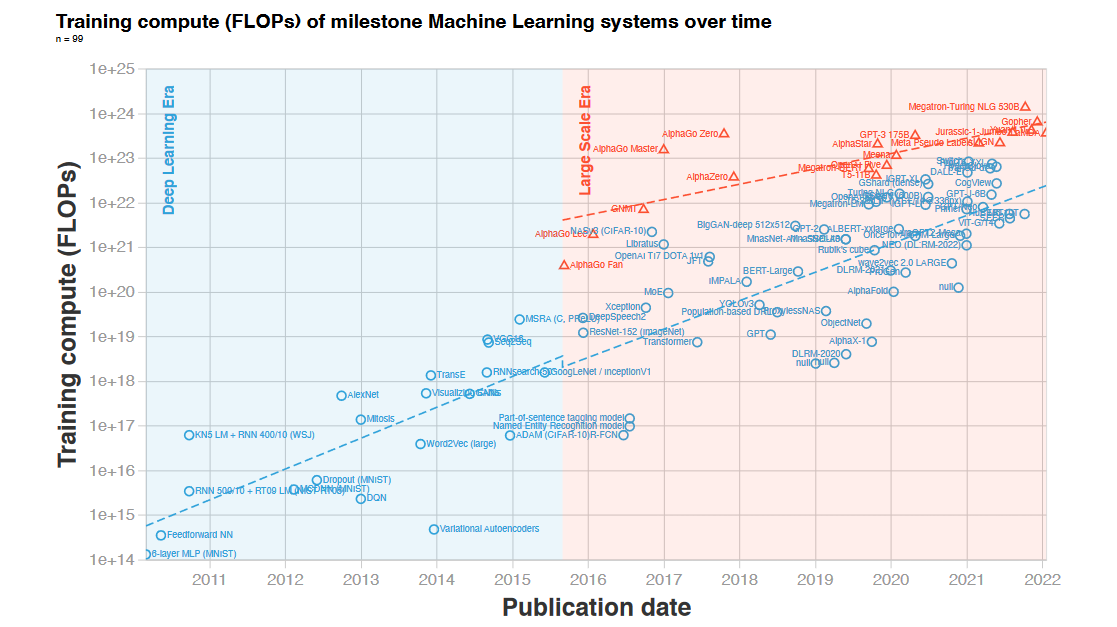
Здесь время удвоения составило, в зависимости от методологии, 10-11 месяцев. Любопытно, что Севилья с коллегами не видят здесь эффектов от бурного роста числа параметров языковых моделей в 2016-20 гг.
Теперь попытаемся актуализировать этот тренд. Вычислительные затраты на обучение GPT-4, выпущенной в марте 2023, составили 2,15 * 10^25 флоп. По сравнению с GPT-3, это рост в 68 раз за 33 месяца. Тренд «эры больших масштабов», вычисленный Севильей и др., даёт на этом отрезке лишь 8-кратный рост. Зато масштабирование GPT-4 хорошо соответствует темпу «эры глубокого обучения» с удвоением каждые 5,4 месяца.
Стоит ли ожидать в ближайшее время такого же агрессивного роста бюджетов? Бум вокруг темы ИИ, проявляющийся в том числе и в очень крупных инвестициях в ИИ-датацентры, а также планы, озвученные рядом конкурентов ”OpenAI”, делают такой сценарий очень вероятным.
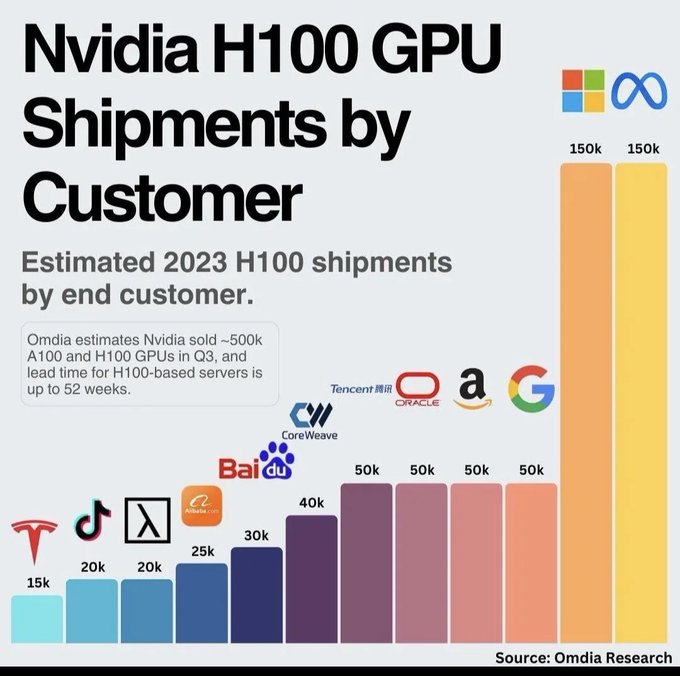
При этом стоит помнить о потенциальной неустойчивости такого быстрого роста на долгосрочных отрезках, что мы увидели при анализе экспоненты числа параметров в модели.
Но что именно может помешать бесконечному росту по экспоненте в данном случае? Начнем с того, что после того, как модели стали обучаться на гигантских датасетах, собранных со всего интернета, стали появляться тревожные предупреждения о том, что данные скоро могут попросту закончиться. Опасения только усилились после того, как «масштабирование по Шиншилле» показало, что моделям будет нужно гораздо больше данных, чем считали ранее.
Одним из самых качественных исследований пределов экстенсивного роста обучающих данных является работа «Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning», выпущенная в конце 2022 сотрудниками “Epoch AI”.
Авторы скрупулезно подсчитывают объем имеющихся данных в двух категориях: текст и изображения, а также прогнозируют их рост в будущем. Рассчитывается и приблизительная траектория роста аппетитов машинных моделей. В результате исследователи получают приблизительное время до момента, когда требование дальнейшего масштабирования моделей упрётся в объективный «потолок».
И это время невелико. Особенно невелико оно для так называемого высококачественного текста. Под высококачественным текстом авторы понимают новостной контент, книги, научные статьи, онлайн-энциклопедии, а также одобренные пользователями записи в соцсетях (например, с большим количеством лайков в «Фейсбук» или с высоким пользовательским рейтингом в «Реддит»). Низкокачественный текст - это все остальные текстовые коммуникации. Включая, например, прочие сообщения в социальных сетях, переписку в мессенджерах и, в пределе, всю звучащую человеческую речь, которая будет записываться, расшифровываться и пополнять базу обучающих данных.
Итак, для высококачественного текста все доступные данные будут исчерпаны, в зависимости от выбранного для экстраполяции тренда… в январе-июне 2024. То есть буквально через 1-6 месяцев. (Препринт с расчетами был опубликован в октябре 2022). Потолок близко, очень близко.
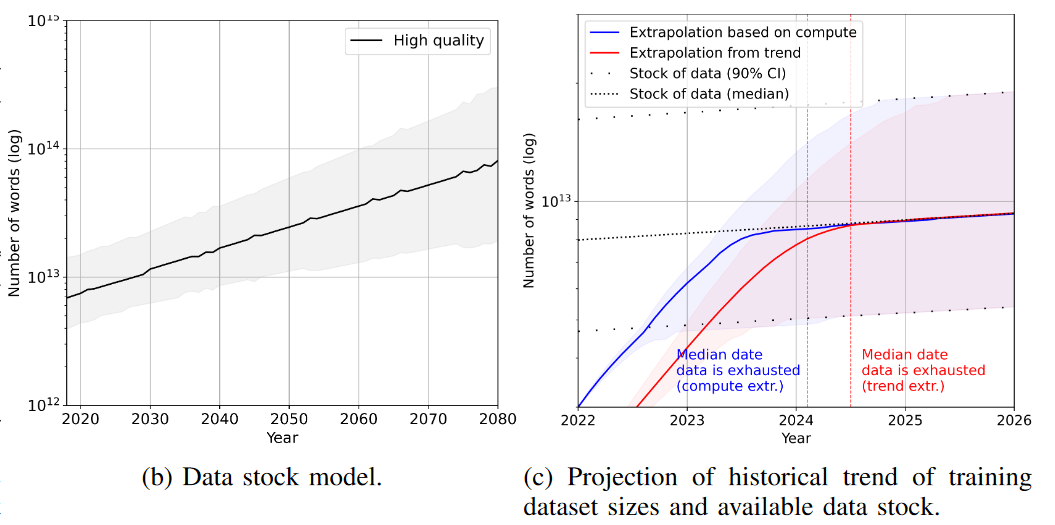
Нет ли здесь ошибки? Увы, расчеты очень похожи на правду. Свериться с реальностью мы можем по GPT-4. Модель была обучена весной-летом на 6-13 трлн. (в зависимости от интерпретации имеющейся скудной информации) токенах текста. Это соответствует 4,5-10 трлн. слов. А по расчетам исследователей, общий объем теоретически доступного для обучения высококачественного текста в 2022 составлял 9 трлн. слов. Таким образом, GPT-4 уже могла упереться в предсказанный учеными потолок.
Да, буквально недавно был подготовлен и более массивный набор обучающих данных, состоящий примерно из 23 трлн. слов. Но мы недаром акцентировали внимание на качестве текста. Качество имеет значение. 23 трлн. слов - это практический максимум, который можно наскрести со всех уголков интернета, без оглядки на содержимое и с минимальными требованиями к степени уникальности документов.
Проблема в том, что попытка «перехитрить самих себя», пытаясь всеми правдами и неправдами раздуть объемы обучающих данных, вряд ли даст достойный результат. И здесь мы можем вернуться к расчетам по низкокачественному тексту, выполненным “Epoch AI”. Да, потолок здесь выше: 1 квадриллион слов, плюс-минус порядок в зависимости от усилий, которые мы можем вложить в сбор и организацию такого обучающего корпуса. Но сколько в таком корпусе будет полезных данных, и сколько - информационного шума? Вероятно, здесь отдача от увеличения объема будет убывать очень быстро.
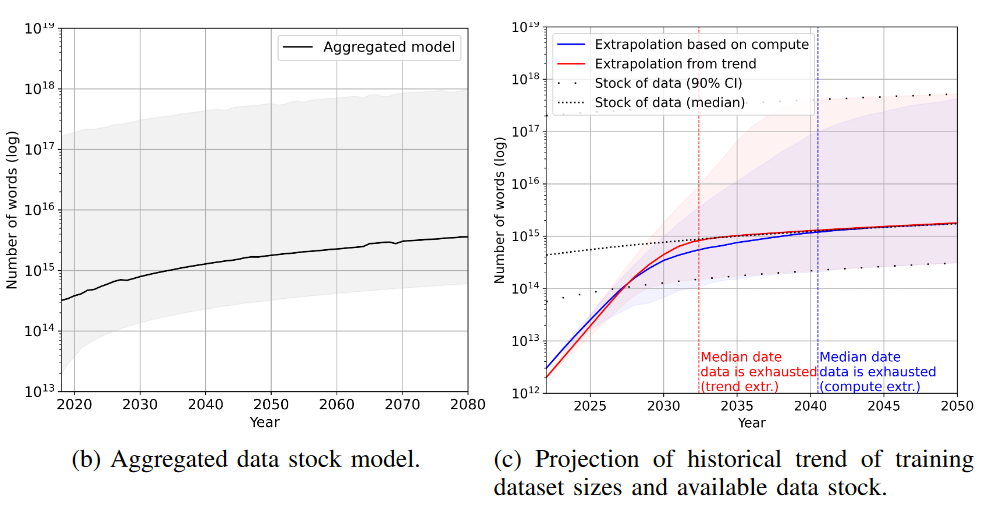
Как бы там ни было, даже такой гигантский объем текста при сохранении нынешних трендов будет освоен моделями в 2032-2040 гг., в зависимости от методики. За скобками остаётся вопрос, насколько быстро смогут измениться наши нормы приватности, чтобы мы безболезненно воспринимали такой тотальный сбор любой генерируемой информации.
Наконец, у нас остался такой вид данных, как изображения. Здесь выводы исследователей наиболее оптимистичны: визуальных данных нам хватит вплоть до 2038-2046 гг.
Но эта толика оптимизма вряд ли перевесит тот факт, что именно с языковыми моделями, оперирующими с текстом, связан тот колоссальный прогресс в области искусственного интеллекта, который мы наблюдали в последние несколько лет. Что же случится, когда ИИ действительно упрется в потолок качественных текстовых данных? Ждёт ли нас близкая стагнация?
Во-первых, уже сейчас мы видим в исследованиях разворот от чисто текстовых моделей в сторону систем, умеющих работать с «менее дефицитными» визуальными данными. Это направление называется «мультимодальность». Подобные модели потенциально могут добавить к своим способностям работу со звуком и видео, управление роботизированным манипулятором и другие разнообразные умения.
Мультимодальность сейчас считается очень перспективной концепцией с точки зрения развития интеллектуальных навыков, аналогичных человеческим. Самые сильные на сегодня ИИ-модели - GPT-4 и Gemini Ultra - обучены работать как с текстовыми, так и с визуальными данными. Выше мы оценили, что GPT-4 уже могла упереться в "потолок" доступных данных для обучения. Но если мы учтем, что модель обучалась еще и на изображениях, некоторый запас до "потолка" в текстовых данных еще мог остаться. Запас небольшой: доля изображений в обучающем датасете GPT-4 могла составлять около 15%.
Добавим, что ИИ-модели, способные видеть и понимать окружающий мир, имеют гораздо более сильный коммерческий потенциал, нежели чисто языковые системы.
Во-вторых, исследуются и способы синтетической генерации обучающих данных самими языковыми моделями. Здесь тоже ключевой характеристикой является качество, и пока данное направление не может гарантировать безусловную полезность. Но потенциально оно позволяет перевести задачу получения обучающих данных в инженерную плоскость: мы сможем с исключительной точностью контролировать, чему и как именно мы хотим научить систему.
В-третьих, недостаток текстовых данных пока не видится достаточной преградой, чтобы остановить количественный рост обучающих бюджетов. Бюджеты будут расти. Потому что иначе продвигаться в ИИ будет трудно. Да, это будет неоптимальный рост. Да, отдача будет ниже. То, чего будет недоставать в данных, придётся компенсировать, например, за счет нашей первой экспоненты - роста числа параметров в модели.
Для понимания того, насколько это может быть неэффективно, посмотрим на еще один график из исследования "Дипмайнд":
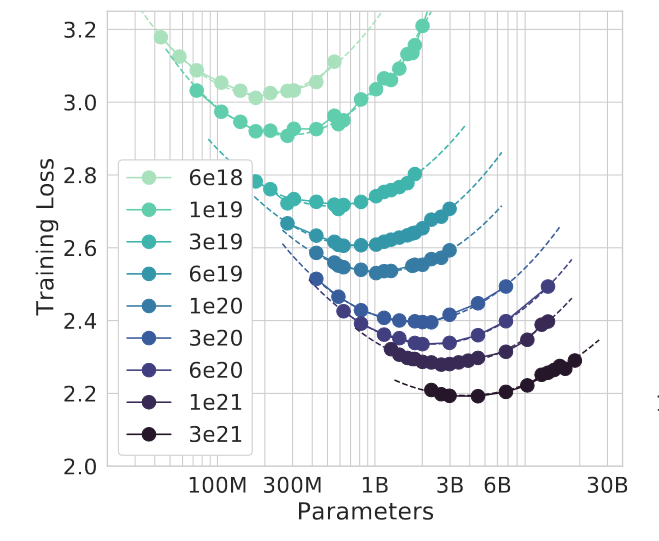
Расшифруем его. По вертикали отложены значения потерь: чем сильнее модель, тем меньше потери. По горизонтали - число параметров в модели. Точки разных цветов соответствуют изофлопсам - то есть одинаковому объему вычислений, затраченному на обучение.
Оптимальный размер модели для заданного объема вычислений соответствует минимуму кривой изофлопсов. Обратим внимание на правый нижний угол - где модели показывают самый сильный результат. Самая правая точка на кривой 3e^21, соответствующая модели с 10 млрд. параметров, проигрывает модели меньшего размера - 2,7 млрд. параметров - на обучение которой было потрачено в три раза меньше вычислений (кривая 1e^21)!
Другими словами, дело не только в размере, но и в том, как его использовать. И в условиях нехватки данных использовать его становится затруднительно. Нехватка данных означает, что нам становятся недоступными точки в левой части кривых изофлопсов. Мы вынуждены уходить по этой кривой всё правее и правее, всё дальше от минимума. И компенсировать это увеличением вычислений - новыми, всё более низкими кривыми изофлопсов. Но с каждым таким увеличением отдача будет падать всё больше и больше.
Что же делать? Ответ, подсказывают исследователи, заключается в том, чтобы выйти за пределы этого графика. В частности, одним из таких ответов является специализация внутри модели. Мы уже упоминали про нее в первой экспоненте, говоря о разреженной архитектуре. Эта архитектура подразумевает, что внутри модели имеются отдельные блоки, специализирующиеся на тех или иных задачах в рамках обработки текста.
Представим, что мы "прикрутили" к этому графику с изофлопсами третье измерение. Это измерение показывает, как потери зависят от тех или иных особенностей текста. В зависимости от особенностей, потери могут быть как выше, так и ниже среднего, которое отражено на "двухмерном" графике выше. И наша модель старается выбрать самые низкие значения, используя специализированные блоки для соответствующих фрагментов текста. В совокупности это даёт существенно более низкие потери, чем неспециализированный подход.
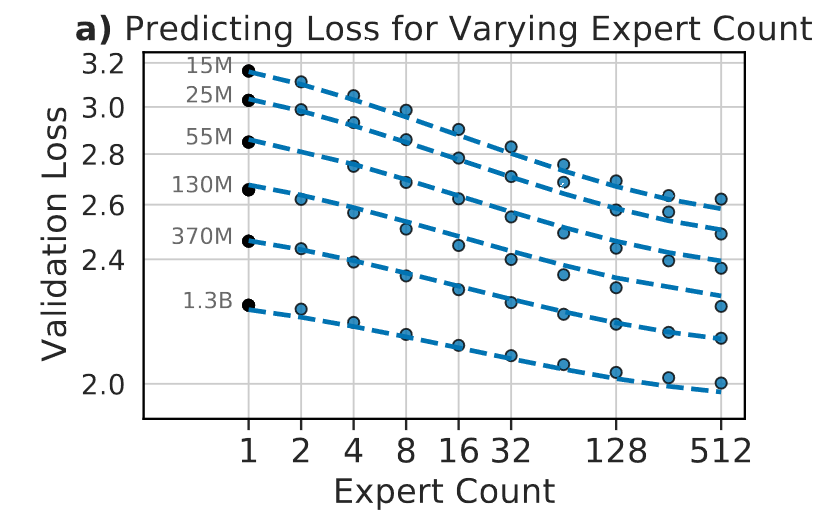
На этом графике мы видим эффективность углубления специализации вплоть до 512 "экспертов" на каждый блок модели. Поскольку такое экстремальное расширение увеличивает размеры модели, наша первая экспонента становится как нельзя актуальной.
Другое направление роста, которое академия исследует уже сейчас - это более интенсивное использование уже имеющихся данных. В том числе более затратное с вычислительной точки зрения. Хорошим примером является эта работа, в которой оценивается выигрыш от увеличения вычислительного бюджета в 2х-16х раз при неизменных размере модели и данных для обучения.
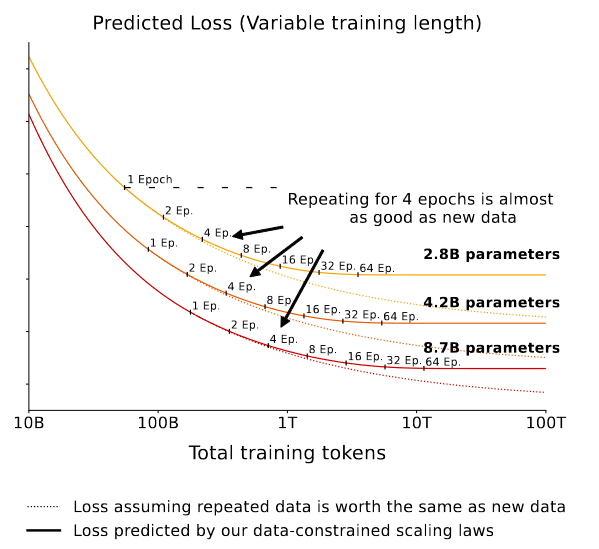
Повторение - мать учения. Да, и для нейросеточек тоже.
Наконец, обратимся, пожалуй, к самому перспективному направлению усовершенстования результатов ИИ-моделей. До сих пор мы рассматривали их как некую "вещь в себе", единую и неделимую. Но использовать эту "вещь в себе" можно бесчисленным количеством способов - и выбранный способ будет влиять на способности модели не меньше, чем ее "внутренние" характеристики.
Это направление можно назвать красивым словом "мета-моделирование" - то есть модель использования модели. И большинство техник, созданных в рамках этого направления, согласуются с нашим количественным принципом: больше = лучше. В качестве примеров можно привести ансамблинг (объединение нескольких однотипных самостоятельных моделей в одну систему), агентские подходы с разделением ролей, итеративную оптимизацию и так далее. Многие такие подходы подразумевают гигантские объемы вычислений - скажем, сотни тысяч попыток для решения одной задачи.
Итак, ограниченность данных пока не сможет помешать бескомпромиссной экспансии вычислительных бюджетов. Но тогда что сможет? Здесь нам пора вспомнить сакраментальную фразу: в этом мире всё стоит денег.
И бюджет на обучение не является исключением. На одном из предыдущих графиков мы увидели, что объем вычислительных бюджетов с начала «революции глубокого обучения» увеличился на 10 порядков. Это означает, что долларовые затраты на них выросли в сопоставимом - хоть и немного отстающем - масштабе.
Для иллюстрации мы вновь обратимся к графику от коллектива ”Epoch AI”:
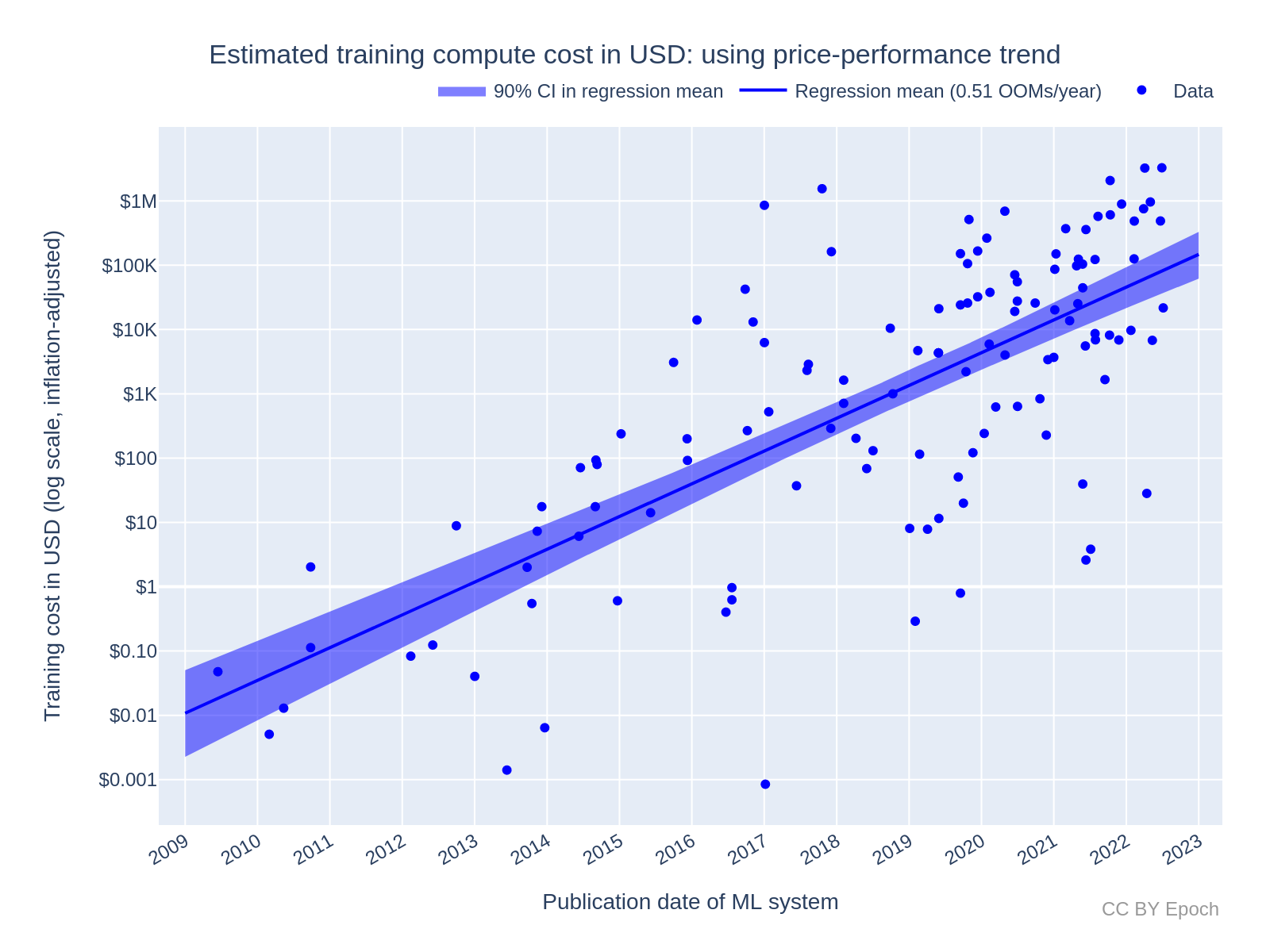
На основании собранных данных исследователь Бен Коттиер делает вывод, что темп роста бюджетов на обучение составляет примерно пол-порядка в год (т. е. в 3,3 раза). Что соответствует удвоению раз в 7 месяцев.
Как всегда, самое интересное на график попасть еще не успело. И не факт, что попадет вообще. Как мы уже говорили выше, ИИ-разработки перешли из академической сферы в коммерческую. А там всегда действовал принцип: «деньги любят тишину». То есть никто не торопится раскрывать свои затраты на создание больших ИИ-моделей.
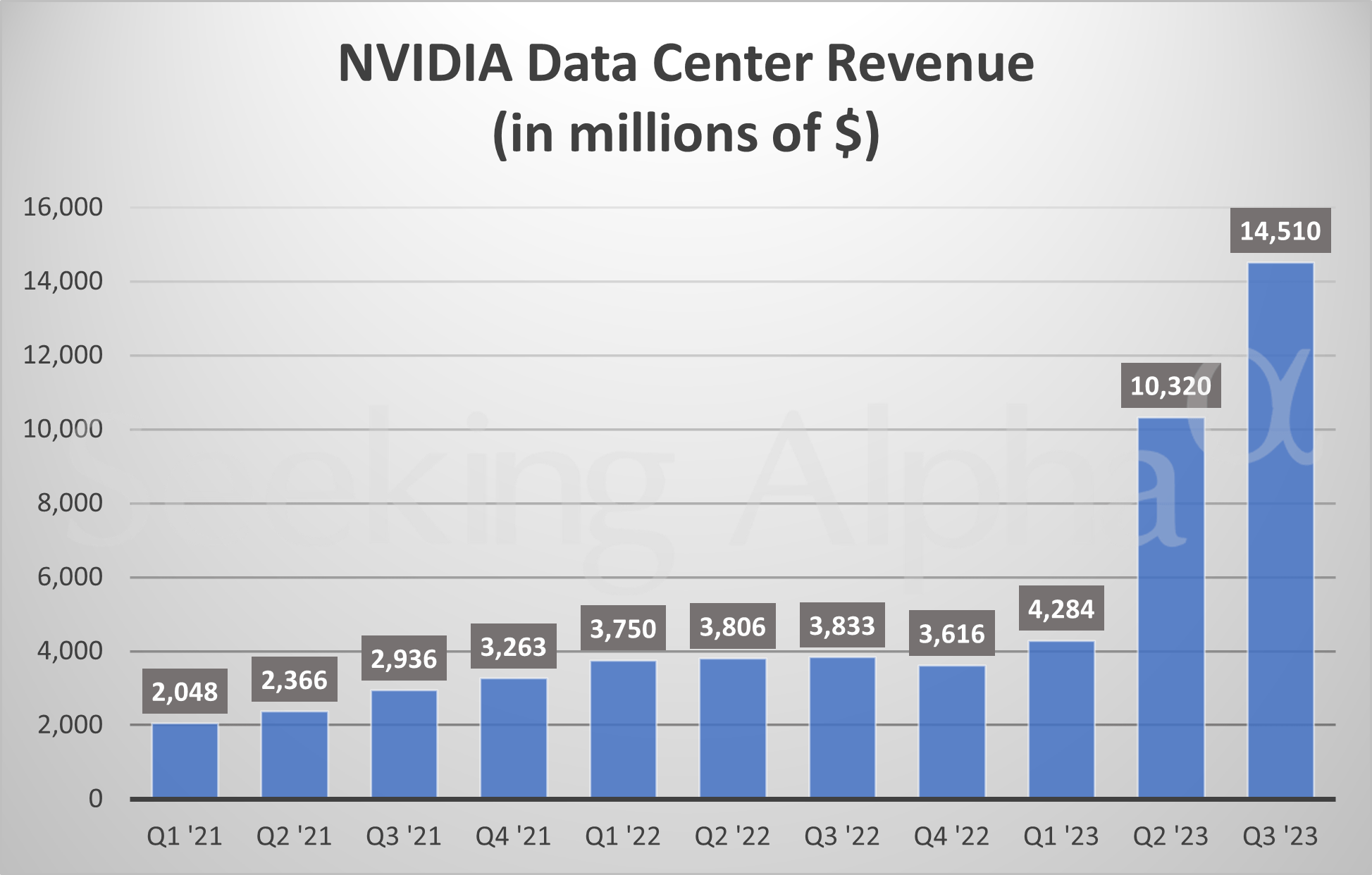
Но, исходя из косвенных данных, эти затраты уже могут обгонять вычисленный Коттиером тренд. Достаточно посмотреть на массивнейший рост спроса на ускорители компании Nvidia. Продажи уже составляют 14 млрд. долларов в квартал; компания прогнозирует дальнейший рост.
Единственная утёкшая на публику сумма - это 63 млн. долларов, потраченные на обучение передовой модели GPT-4. Впрочем, это скорее оценка «по минимуму», считающая лишь стоимость аренды ускорителей в «облаке» и не включающая затраты на персонал. А последняя статья расходов для ИИ-компаний весьма велика. Специалисты топового уровня могут получать 1 млн. долларов в год.
Оценки, включающие все фактические денежные затраты разработчиков ИИ-моделей, дают куда более высокие суммы. Так, один из самых подробных имеющихся расчетов исходит из того, что ускорители вместе с прочим вычислительным оборудованием не арендуются, а покупаются, и получает, что создание GPT-4 обошлось в 500 млн. долларов.
Это солидные деньги. Это деньги, которые заставляют задуматься об устойчивости тренда на удвоение бюджета каждые семь месяцев. Но где же тогда будет порог, на котором «солидные» деньги превращаются в «нереальные» деньги?
В середине 2023 практически вся ИИ-индустрия сошлась во мнении, что 1 млрд. долларов на обучение - это вполне достижимый масштаб. Более того, обучение моделей с таким ценником, уже могло начаться. И они будут представлены публике в самом скором времени, не позднее середины 2024.
Что дальше? Мы можем косвенно оценить предел инвестиционной щедрости корпораций по масштабам финансирования других крупных революционных проектов. Здесь, конечно, первой на ум приходит «Мета» со своей мета-вселенной. Вот уже второй год проект жжёт деньги со скоростью 13-14 млрд. долларов в год.

“SpaceX” может дать нам сразу два ориентира. Стоимость разработки космического корабля «Старшип» может составить от 5 до 10 млрд. долларов. Проект группировки для спутникового интернета «Старлинк» обойдется еще в 10 млрд. долларов. Аналогичную сумму собирался вложить конкурирующий проект от «Амазон», ”Project Kuiper”.
Совокупные затраты на разработку беспилотного автомобиля компанией “Waymo” составляют порядка 9 млрд. долларов. В беспилотные разработки компании “Cruise” были вложены сопоставимые деньги.
Итак, если мы учтем, что нас интересуют затраты на обучение одной-единственной модели, а не суммарные затраты корпорации на разработки в области ИИ, 5 млрд. долларов видятся абсолютно достижимой, консервативной оценкой. Реалистичный верхний предел обучающего бюджета будет где-то в районе 15 млрд. долларов.
Если тренд удвоения бюджетов останется неизменным, 5-миллиардная отметка должна быть «освоена» в начале 2025. 15-миллиардная - в начале 2026. Таким образом, потолок здесь немного выше, чем в случае с доступностью данных для обучения, но тоже довольно близок.
Дальнейшее масштабирование обучающих затрат требует гораздо более фундаментальной экономической базы, нежели простая вера ИТ-компаний в светлое будущее ИИ. Более того, такой рост может затронуть очень широкий спектр экономических отраслей. Всё это уже выходит за рамки собственного обучающего бюджета. Поэтому мы посвятим этим вещам отдельные экспоненты. Но сперва нам надо обсудить еще пару экспоненциальных процессов, без которых трудно представить прогресс в области искусственного интеллекта...
>> Продолжение: 3. Эффективность микроэлектроники >>
_______________________________________________________________
Друзья, я начал вести канал в Телеграм: Экономика знаний. Подписывайтесь!
2. Вычислительный бюджет на обучение ИИ
Концепция машинного обучения, в рамках которой сейчас создаются практически все алгоритмы ИИ, отдаленно похожа на принципы человеческого обучения. Модели даётся пример какой-то задачи, она пытается ее решить и учится на своих ошибках.
Если же мы преследуем цель создать общий искусственный интеллект, круг задач, которые он должен уметь решать, расширяется кардинально. Машине нужно уметь очень и очень много. А раз ей нужно уметь очень и очень много, ей нужно очень много учиться.
И здесь мы упираемся в специфическое ограничение: нынешние алгоритмы учатся весьма и весьма неэффективно. Обучение даётся им тяжело. Чтобы освоить любую задачу, им надо переработать большое количество обучающих примеров. А если таких задач много - объем информации, который требуется поглотить машине, приобретает гигантские масштабы.
К концу 2010-ых годов «ручное» создание обучающих материалов для машинных моделей уперлось в свои пределы: крупнейшие наборы таких данных включали миллионы обучающих примеров, каждый из которых требовал затрат человеческого труда. И при всей трудоёмкости создания такого набора, он мог обучить алгоритм лишь одному узкому навыку.
Выходом из ситуации стало использование для обучения любых доступных данных в изначальном виде, без какой-либо обработки - например, гигантского массива скачанных из интернета веб-страниц, или взятых оттуда же изображений. Конечно, такой «образовательный материал» не мог сравниться в качестве со специально созданными обучающими датасетами.
"Французские котики" из гигантского датасета LAION-5B. Проблемы с качеством видны уже во втором ряду изображений
Но то, что он терял в качестве, он с лихвой компенсировал в количестве. Оказалось, что такой упор на количество был как раз тем, что нужно неэффективным в плане учебы алгоритмам. Более того, отказавшись от какой-либо обработки данных, в том числе тематической фильтрации, и скармливая машине всё подряд, исследователи преодолевали и проблему узости навыков ИИ.
Как говорил Пушкин, мы все учились понемногу, чему-нибудь и как-нибудь. Машины же учатся чему-нибудь и как-нибудь помногу. Очень помногу. И чем более «помногу» они учатся - тем более сильные интеллектуальные навыки они демонстрируют. Таким образом, возникает еще одно «количественное» направление масштабирования способностей ИИ: объем данных, использованных для его обучения.
Здесь, как и в теме масштабирования размера модели, уже появилось множество научных работ, исследующих зависимость интеллектуальных способностей модели от количества освоенных ею данных. Одна из влиятельных таких работ была выпущена ”OpenAI” в 2020. Работа постулировала:
«...при вычислительно-оптимальном обучении размер датасета не должен расти быстрее, чем D ∝ N^2/3, с более разумной медианной оценкой D ∝ N^0.4»,
где D - количество обучающих данных и N - число параметров модели.
А это графическое представление проведенных "OpenAI" экспериментов
Найденная закономерность означала, что при 10-кратном росте числа параметров необходимо увеличивать объем обучающих данных в 10^0,4=2,5 раза. Это «задним числом» оправдывало сногсшибательный темп роста размеров моделей с 2016 года: получалось, что отдача от этого роста была гораздо выше при тех же вычислительных затратах на обучение.
При этом получалось, что вычислительный бюджет на обучение должен расти геометрически, со скоростью N * N^0,4 = N^1,4. При росте параметров в 10 раз бюджет вырастает в 25 раз.
Но вскоре эта закономерность была существенно пересмотрена. Работа от исследователей из «Дипмайнд», вышедшая в 2022, доказывала, что для улучшения модели необходимо наращивать параметры и обучающие данные примерно в одной и той же пропорции. Более того, авторы рассчитали, что предыдущие языковые модели были обучены на слишком малом объеме данных. И гнаться за ростом числа параметров сейчас нет смысла: надо эффективнее осваивать потенциал моделей меньшего размера.
Черный штрих-пунктир - оптимальное масштабирование, получившееся у "OpenAI" в 2020. Цветные прямые - уточненные результаты от "Дипмайнд". Обратите внимание, что они более пологие. Это означает, что объем вычислений на обучение должен расти больше, чем предполагалось ранее.
Новая закономерность стала широко известна как «масштабирование по Шиншилле» (Шиншиллой назвали модель, которую «Дипмайнд» обучил по этому правилу). И эта закономерность означает, что вычислительный бюджет при росте числа параметров должен расти квадратически. То есть рост параметров в 10 раз требует роста бюджета в 100 раз.
Более поздние исследования по этой теме незначительно уточнили эту закономерность и подтвердили фундаментальный принцип квадратического роста вычислительного бюджета.
Уточненные правила масштабирования стали важной причиной, по которой размер моделей затормозил свой рост с 2022 года. Поскольку оказалось, что и размер модели, и количество обучающих данных одинаково важны, в дальнейшем анализе мы можем опираться на интегральный показатель масштабирования ИИ-алгоритмов: объем вычислений, затраченный для обучения моделей.
В этом анализе нам поможет работа Дж. Севильи «Compute Trends Across Three Eras of Machine Learning». Её обобщенные результаты представлены на этом графике:
Исследователи выделяют три «эры», три режима роста вычислительных бюджетов. Первая эра продолжалась до революции глубокого обучения, примерно до 2010. Для нее было характерно удвоение бюджетов каждый 21 месяц. Что примерно соответствует темпу закона Мура.
Вторая эра - эра глубокого обучения, 2010-2015 (либо, в альтернативной трактовке, вплоть до сегодняшнего времени). Вычислительные бюджеты здесь удваивались очень быстро - примерно раз в полгода.
Наконец, третья эра, на которую мы обратим самое пристальное внимание - эра больших масштабов. Посмотрим на эту часть графика в деталях:
Здесь время удвоения составило, в зависимости от методологии, 10-11 месяцев. Любопытно, что Севилья с коллегами не видят здесь эффектов от бурного роста числа параметров языковых моделей в 2016-20 гг.
Теперь попытаемся актуализировать этот тренд. Вычислительные затраты на обучение GPT-4, выпущенной в марте 2023, составили 2,15 * 10^25 флоп. По сравнению с GPT-3, это рост в 68 раз за 33 месяца. Тренд «эры больших масштабов», вычисленный Севильей и др., даёт на этом отрезке лишь 8-кратный рост. Зато масштабирование GPT-4 хорошо соответствует темпу «эры глубокого обучения» с удвоением каждые 5,4 месяца.
Стоит ли ожидать в ближайшее время такого же агрессивного роста бюджетов? Бум вокруг темы ИИ, проявляющийся в том числе и в очень крупных инвестициях в ИИ-датацентры, а также планы, озвученные рядом конкурентов ”OpenAI”, делают такой сценарий очень вероятным.
При этом стоит помнить о потенциальной неустойчивости такого быстрого роста на долгосрочных отрезках, что мы увидели при анализе экспоненты числа параметров в модели.
Но что именно может помешать бесконечному росту по экспоненте в данном случае? Начнем с того, что после того, как модели стали обучаться на гигантских датасетах, собранных со всего интернета, стали появляться тревожные предупреждения о том, что данные скоро могут попросту закончиться. Опасения только усилились после того, как «масштабирование по Шиншилле» показало, что моделям будет нужно гораздо больше данных, чем считали ранее.
Одним из самых качественных исследований пределов экстенсивного роста обучающих данных является работа «Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning», выпущенная в конце 2022 сотрудниками “Epoch AI”.
Авторы скрупулезно подсчитывают объем имеющихся данных в двух категориях: текст и изображения, а также прогнозируют их рост в будущем. Рассчитывается и приблизительная траектория роста аппетитов машинных моделей. В результате исследователи получают приблизительное время до момента, когда требование дальнейшего масштабирования моделей упрётся в объективный «потолок».
И это время невелико. Особенно невелико оно для так называемого высококачественного текста. Под высококачественным текстом авторы понимают новостной контент, книги, научные статьи, онлайн-энциклопедии, а также одобренные пользователями записи в соцсетях (например, с большим количеством лайков в «Фейсбук» или с высоким пользовательским рейтингом в «Реддит»). Низкокачественный текст - это все остальные текстовые коммуникации. Включая, например, прочие сообщения в социальных сетях, переписку в мессенджерах и, в пределе, всю звучащую человеческую речь, которая будет записываться, расшифровываться и пополнять базу обучающих данных.
Итак, для высококачественного текста все доступные данные будут исчерпаны, в зависимости от выбранного для экстраполяции тренда… в январе-июне 2024. То есть буквально через 1-6 месяцев. (Препринт с расчетами был опубликован в октябре 2022). Потолок близко, очень близко.
Нет ли здесь ошибки? Увы, расчеты очень похожи на правду. Свериться с реальностью мы можем по GPT-4. Модель была обучена весной-летом на 6-13 трлн. (в зависимости от интерпретации имеющейся скудной информации) токенах текста. Это соответствует 4,5-10 трлн. слов. А по расчетам исследователей, общий объем теоретически доступного для обучения высококачественного текста в 2022 составлял 9 трлн. слов. Таким образом, GPT-4 уже могла упереться в предсказанный учеными потолок.
Да, буквально недавно был подготовлен и более массивный набор обучающих данных, состоящий примерно из 23 трлн. слов. Но мы недаром акцентировали внимание на качестве текста. Качество имеет значение. 23 трлн. слов - это практический максимум, который можно наскрести со всех уголков интернета, без оглядки на содержимое и с минимальными требованиями к степени уникальности документов.
Проблема в том, что попытка «перехитрить самих себя», пытаясь всеми правдами и неправдами раздуть объемы обучающих данных, вряд ли даст достойный результат. И здесь мы можем вернуться к расчетам по низкокачественному тексту, выполненным “Epoch AI”. Да, потолок здесь выше: 1 квадриллион слов, плюс-минус порядок в зависимости от усилий, которые мы можем вложить в сбор и организацию такого обучающего корпуса. Но сколько в таком корпусе будет полезных данных, и сколько - информационного шума? Вероятно, здесь отдача от увеличения объема будет убывать очень быстро.
Как бы там ни было, даже такой гигантский объем текста при сохранении нынешних трендов будет освоен моделями в 2032-2040 гг., в зависимости от методики. За скобками остаётся вопрос, насколько быстро смогут измениться наши нормы приватности, чтобы мы безболезненно воспринимали такой тотальный сбор любой генерируемой информации.
Наконец, у нас остался такой вид данных, как изображения. Здесь выводы исследователей наиболее оптимистичны: визуальных данных нам хватит вплоть до 2038-2046 гг.
Но эта толика оптимизма вряд ли перевесит тот факт, что именно с языковыми моделями, оперирующими с текстом, связан тот колоссальный прогресс в области искусственного интеллекта, который мы наблюдали в последние несколько лет. Что же случится, когда ИИ действительно упрется в потолок качественных текстовых данных? Ждёт ли нас близкая стагнация?
Во-первых, уже сейчас мы видим в исследованиях разворот от чисто текстовых моделей в сторону систем, умеющих работать с «менее дефицитными» визуальными данными. Это направление называется «мультимодальность». Подобные модели потенциально могут добавить к своим способностям работу со звуком и видео, управление роботизированным манипулятором и другие разнообразные умения.
Мультимодальность сейчас считается очень перспективной концепцией с точки зрения развития интеллектуальных навыков, аналогичных человеческим. Самые сильные на сегодня ИИ-модели - GPT-4 и Gemini Ultra - обучены работать как с текстовыми, так и с визуальными данными. Выше мы оценили, что GPT-4 уже могла упереться в "потолок" доступных данных для обучения. Но если мы учтем, что модель обучалась еще и на изображениях, некоторый запас до "потолка" в текстовых данных еще мог остаться. Запас небольшой: доля изображений в обучающем датасете GPT-4 могла составлять около 15%.
Добавим, что ИИ-модели, способные видеть и понимать окружающий мир, имеют гораздо более сильный коммерческий потенциал, нежели чисто языковые системы.
Во-вторых, исследуются и способы синтетической генерации обучающих данных самими языковыми моделями. Здесь тоже ключевой характеристикой является качество, и пока данное направление не может гарантировать безусловную полезность. Но потенциально оно позволяет перевести задачу получения обучающих данных в инженерную плоскость: мы сможем с исключительной точностью контролировать, чему и как именно мы хотим научить систему.
В-третьих, недостаток текстовых данных пока не видится достаточной преградой, чтобы остановить количественный рост обучающих бюджетов. Бюджеты будут расти. Потому что иначе продвигаться в ИИ будет трудно. Да, это будет неоптимальный рост. Да, отдача будет ниже. То, чего будет недоставать в данных, придётся компенсировать, например, за счет нашей первой экспоненты - роста числа параметров в модели.
Для понимания того, насколько это может быть неэффективно, посмотрим на еще один график из исследования "Дипмайнд":
Расшифруем его. По вертикали отложены значения потерь: чем сильнее модель, тем меньше потери. По горизонтали - число параметров в модели. Точки разных цветов соответствуют изофлопсам - то есть одинаковому объему вычислений, затраченному на обучение.
Оптимальный размер модели для заданного объема вычислений соответствует минимуму кривой изофлопсов. Обратим внимание на правый нижний угол - где модели показывают самый сильный результат. Самая правая точка на кривой 3e^21, соответствующая модели с 10 млрд. параметров, проигрывает модели меньшего размера - 2,7 млрд. параметров - на обучение которой было потрачено в три раза меньше вычислений (кривая 1e^21)!
Другими словами, дело не только в размере, но и в том, как его использовать. И в условиях нехватки данных использовать его становится затруднительно. Нехватка данных означает, что нам становятся недоступными точки в левой части кривых изофлопсов. Мы вынуждены уходить по этой кривой всё правее и правее, всё дальше от минимума. И компенсировать это увеличением вычислений - новыми, всё более низкими кривыми изофлопсов. Но с каждым таким увеличением отдача будет падать всё больше и больше.
Что же делать? Ответ, подсказывают исследователи, заключается в том, чтобы выйти за пределы этого графика. В частности, одним из таких ответов является специализация внутри модели. Мы уже упоминали про нее в первой экспоненте, говоря о разреженной архитектуре. Эта архитектура подразумевает, что внутри модели имеются отдельные блоки, специализирующиеся на тех или иных задачах в рамках обработки текста.
Представим, что мы "прикрутили" к этому графику с изофлопсами третье измерение. Это измерение показывает, как потери зависят от тех или иных особенностей текста. В зависимости от особенностей, потери могут быть как выше, так и ниже среднего, которое отражено на "двухмерном" графике выше. И наша модель старается выбрать самые низкие значения, используя специализированные блоки для соответствующих фрагментов текста. В совокупности это даёт существенно более низкие потери, чем неспециализированный подход.
На этом графике мы видим эффективность углубления специализации вплоть до 512 "экспертов" на каждый блок модели. Поскольку такое экстремальное расширение увеличивает размеры модели, наша первая экспонента становится как нельзя актуальной.
Другое направление роста, которое академия исследует уже сейчас - это более интенсивное использование уже имеющихся данных. В том числе более затратное с вычислительной точки зрения. Хорошим примером является эта работа, в которой оценивается выигрыш от увеличения вычислительного бюджета в 2х-16х раз при неизменных размере модели и данных для обучения.
Повторение - мать учения. Да, и для нейросеточек тоже.
Наконец, обратимся, пожалуй, к самому перспективному направлению усовершенстования результатов ИИ-моделей. До сих пор мы рассматривали их как некую "вещь в себе", единую и неделимую. Но использовать эту "вещь в себе" можно бесчисленным количеством способов - и выбранный способ будет влиять на способности модели не меньше, чем ее "внутренние" характеристики.
Это направление можно назвать красивым словом "мета-моделирование" - то есть модель использования модели. И большинство техник, созданных в рамках этого направления, согласуются с нашим количественным принципом: больше = лучше. В качестве примеров можно привести ансамблинг (объединение нескольких однотипных самостоятельных моделей в одну систему), агентские подходы с разделением ролей, итеративную оптимизацию и так далее. Многие такие подходы подразумевают гигантские объемы вычислений - скажем, сотни тысяч попыток для решения одной задачи.
Итак, ограниченность данных пока не сможет помешать бескомпромиссной экспансии вычислительных бюджетов. Но тогда что сможет? Здесь нам пора вспомнить сакраментальную фразу: в этом мире всё стоит денег.
И бюджет на обучение не является исключением. На одном из предыдущих графиков мы увидели, что объем вычислительных бюджетов с начала «революции глубокого обучения» увеличился на 10 порядков. Это означает, что долларовые затраты на них выросли в сопоставимом - хоть и немного отстающем - масштабе.
Для иллюстрации мы вновь обратимся к графику от коллектива ”Epoch AI”:
На основании собранных данных исследователь Бен Коттиер делает вывод, что темп роста бюджетов на обучение составляет примерно пол-порядка в год (т. е. в 3,3 раза). Что соответствует удвоению раз в 7 месяцев.
Как всегда, самое интересное на график попасть еще не успело. И не факт, что попадет вообще. Как мы уже говорили выше, ИИ-разработки перешли из академической сферы в коммерческую. А там всегда действовал принцип: «деньги любят тишину». То есть никто не торопится раскрывать свои затраты на создание больших ИИ-моделей.
Но, исходя из косвенных данных, эти затраты уже могут обгонять вычисленный Коттиером тренд. Достаточно посмотреть на массивнейший рост спроса на ускорители компании Nvidia. Продажи уже составляют 14 млрд. долларов в квартал; компания прогнозирует дальнейший рост.
Единственная утёкшая на публику сумма - это 63 млн. долларов, потраченные на обучение передовой модели GPT-4. Впрочем, это скорее оценка «по минимуму», считающая лишь стоимость аренды ускорителей в «облаке» и не включающая затраты на персонал. А последняя статья расходов для ИИ-компаний весьма велика. Специалисты топового уровня могут получать 1 млн. долларов в год.
Оценки, включающие все фактические денежные затраты разработчиков ИИ-моделей, дают куда более высокие суммы. Так, один из самых подробных имеющихся расчетов исходит из того, что ускорители вместе с прочим вычислительным оборудованием не арендуются, а покупаются, и получает, что создание GPT-4 обошлось в 500 млн. долларов.
Это солидные деньги. Это деньги, которые заставляют задуматься об устойчивости тренда на удвоение бюджета каждые семь месяцев. Но где же тогда будет порог, на котором «солидные» деньги превращаются в «нереальные» деньги?
В середине 2023 практически вся ИИ-индустрия сошлась во мнении, что 1 млрд. долларов на обучение - это вполне достижимый масштаб. Более того, обучение моделей с таким ценником, уже могло начаться. И они будут представлены публике в самом скором времени, не позднее середины 2024.
Что дальше? Мы можем косвенно оценить предел инвестиционной щедрости корпораций по масштабам финансирования других крупных революционных проектов. Здесь, конечно, первой на ум приходит «Мета» со своей мета-вселенной. Вот уже второй год проект жжёт деньги со скоростью 13-14 млрд. долларов в год.
“SpaceX” может дать нам сразу два ориентира. Стоимость разработки космического корабля «Старшип» может составить от 5 до 10 млрд. долларов. Проект группировки для спутникового интернета «Старлинк» обойдется еще в 10 млрд. долларов. Аналогичную сумму собирался вложить конкурирующий проект от «Амазон», ”Project Kuiper”.
Совокупные затраты на разработку беспилотного автомобиля компанией “Waymo” составляют порядка 9 млрд. долларов. В беспилотные разработки компании “Cruise” были вложены сопоставимые деньги.
Итак, если мы учтем, что нас интересуют затраты на обучение одной-единственной модели, а не суммарные затраты корпорации на разработки в области ИИ, 5 млрд. долларов видятся абсолютно достижимой, консервативной оценкой. Реалистичный верхний предел обучающего бюджета будет где-то в районе 15 млрд. долларов.
Если тренд удвоения бюджетов останется неизменным, 5-миллиардная отметка должна быть «освоена» в начале 2025. 15-миллиардная - в начале 2026. Таким образом, потолок здесь немного выше, чем в случае с доступностью данных для обучения, но тоже довольно близок.
Дальнейшее масштабирование обучающих затрат требует гораздо более фундаментальной экономической базы, нежели простая вера ИТ-компаний в светлое будущее ИИ. Более того, такой рост может затронуть очень широкий спектр экономических отраслей. Всё это уже выходит за рамки собственного обучающего бюджета. Поэтому мы посвятим этим вещам отдельные экспоненты. Но сперва нам надо обсудить еще пару экспоненциальных процессов, без которых трудно представить прогресс в области искусственного интеллекта...
>> Продолжение: 3. Эффективность микроэлектроники >>
_______________________________________________________________
Друзья, я начал вести канал в Телеграм: Экономика знаний. Подписывайтесь!