Не миллионы людей потеряют работу - десятки миллионов
Не миллионы людей потеряют работу - десятки миллионов
Автоматизация помогла наступить эпохе Трампа. Что нам готовит ИИ
В ближайшие 40 лет роботы займут ваши рабочие места.
Неважно, кем вы работаете. Копаете траншеи? Робот будет копать их лучше. Пишете статьи для журнала? Робот будет писать лучше вас. Если вы врач, Watson от IBM больше не будет помогать вам с поиском правильного диагноза в его базе данных с миллионами описаний клинических случаев и журнальных статей. Он просто будет лечить лучше, чем вы.

Вы генеральный директор компании? Мне жаль, но роботы будут управлять компаниями лучше, чем вы. Люди творческих профессий? Роботы будут рисовать, писать и лепить лучше вас. Думаете, что ваши социальные навыки недоступны роботам? Очень даже доступны. В течение 20 лет примерно половина из вас лишится работы. Ещё через пару десятилетий та же участь ждёт большинство оставшихся.
В каком-то смысле звучит здорово. Пусть роботы работают! Не придётся больше вытаскивать себя из постели в шесть утра или проводить весь день на ногах. Мы сможем спокойно читать, писать стихи, играть в видеоигры и вообще делать что угодно. И через столетие, скорее всего, так и будет. Человечество вступит в золотой век.
Но что случится через 20 лет? Или 30? Многие к тому времени потеряют работу. Поверьте, это не будет похоже на золотой век. Пока мы не выясним, как справедливо распределить плоды труда роботов, нас ожидает эпоха массовой безработицы и нищеты. Безработица среди рабочего класса сыграла большую роль в выборах 2016 года в США.
Если мы не хотим стать свидетелями того, как демагоги сменяют друг друга у власти из-за того, что машины отнимают у людей средства к существованию, этому нужно положить конец как можно скорее. Наряду с глобальным потеплением, будущее без работы - главная проблема, которая стоит перед прогрессивными политиками, не говоря уже про человечество в целом. Но сейчас эта проблема едва попадает в поле нашего зрения.
Вот занудство, да? К счастью, статьи на сложную или узкоспециальную тему традиционно начинаются с какого-нибудь забавного или необычного случая. Это помогает читателю медленно погрузиться в пугающий своей сложностью материал. Я тоже расскажу вам об одном таком случае.
На прошлое Рождество я был в доме своей матери. Там я упомянул, что недавно прочёл статью про Google Translate. Оказалось, что за несколько недель до этого, никому не сообщив, Google перешла на новый алгоритм машинного обучения. Качество переводов резко подскочило. Я и сам заметил улучшения, но списал их на обычный поступательный прогресс. Я не понял, что это произошло благодаря скачку в работе алгоритмов.
Но если алгоритм переводов Google стал лучше, значит ли это, что распознавание голоса тоже стало лучше? И способность отвечать на вопросы? Как бы нам это проверить? Мы решили распаковать подарки вместо того, чтобы размышлять об этом.
Потом мы непонятно как перешли на тему ластиков. Какие ластики лучше? Светлые? Чёрные? Традиционные розовые? Если подумать, почему они вообще обычно розовые? «Спрошу Google!» - сказал я. После чего достал телефон и задал вопрос: «Почему ластики розовые?» Через полсекунды Google мне ответил.

Художник Роберто Парада
Не впечатлены? А должны быть. Все мы знаем, что телефоны неплохо умеют распознавать голос. И мы знаем, что они могут найти ближайшее кафе или популярный рецепт курицы в вине. Но как насчёт совершенно случайного вопроса? И не лёгкого «кто», «где» или «когда»?
Я задал вопрос «почему», и он был не о том, например, почему певица Pink использует ластики. Google должен сообразить, что я сказал «розовые», что я интересуюсь историческими причинами цвета резинок, а не их состоянием или формой. И он это сделал. Меньше, чем за секунду. Имея в своём распоряжении дешёвый микропроцессор и медленное подключение к интернету.
Если вам интересно, Google взял ответ у Design*Sponge: «Производить ластики начала компания Eberhard Faber… Резинки имели в своём составе пемзу - вулканический пепел из Италии, который придавал им абразивные свойства, а также характерный цвет и запах».
Всё ещё не впечатлены? В те времена, когда Watson выиграл раунд телевикторины Jeopardy против двух лучших игроков всех времён, ему понадобился бы компьютер величиной со спальную комнату, чтобы ответить на такой вопрос. Это было всего семь лет назад.
Какое отношение розовые ластики имеют к тому, что все мы останемся без работы через пару десятков лет? Рассказываю. В прошлом октябре сервис грузовых перевозок Otto (дочерняя компания Uber) перевёз две тысячи ящиков Budweiser на расстояние 120 миль из Форт-Коллинза, штат Колорадо, в Колорадо-Спрингс - без водителя за рулём.

За несколько лет эта технология пройдёт путь от прототипа до внедрения, а это значит, что миллионы водителей грузовиков останутся без работы.
Автоматизированные грузовые перевозки не опираются на новомодные машины, как промышленная революция 19 века опиралась на механический ткацкий станок и паровой экскаватор. Как и способность Google распознавать речь и отвечать на вопросы, беспилотные грузовики, а также автомобили, автобусы и корабли полагаются на программы, которые копируют человеческий интеллект.
Теперь все уже слышали прогнозы, по которым беспилотные автомобили могут привести к потере 5 млн рабочих мест. Но немногие понимают, что как только алгоритмы ИИ будут готовы к вождению, они будут готовы и ко многому другому. Не миллионы людей потеряют работу - десятки миллионов.
Вот что мы имеем в виду, когда говорим «роботы». Мы говорим о когнитивных способностях, а не о существах, которые сделаны из металла и питаются электричеством, а не куриными наггетсами.
Другими словами, нужно смотреть не на подвижки в робототехнике, а на скорость, с которой мы мчимся навстречу искусственному интеллекту. Пусть мы пока и близко не подошли к ИИ на уровне человеческого интеллекта, прогресс последней пары десятилетий поражает.
Много лет технологии стояли на месте, и вдруг роботы играют в шахматы лучше гроссмейстеров. Они играют в Jeopardy лучше рекордсменов. Они могут водить автомобили по Сан-Франциско и становятся в этом лучше год от года.
Они так хорошо распознают лица, что полиция Уэльса недавно совершила первый в Великобритании арест, используя программу распознавания лиц. После нескольких лет медленного прогресса в распознавании речи Google объявил, что снизил уровень ошибок в распознавании с 8,5% до 4,9% за десять месяцев.
Всё это говорит о том, что ИИ развивается экспоненциально благодаря улучшению как компьютерного оборудования, так и алгоритмов. По закону Мура, мощность и производительность процессоров удваиваются каждые два года. Недавние усовершенствования алгоритмов были ещё более стремительными. Долгое время эти подвижки казались незначительными.
Переход от интеллекта бактерии к интеллекту нематоды технически представляет собой огромный скачок, но на практике не приближает нас к настоящему искусственному интеллекту. Однако, если удвоение будет продолжаться, один из циклов удвоения приведёт к переходу от интеллекта ящерицы к интеллекту мыши, а затем и к интеллекту обезьяны. Как только это произойдёт, до ИИ уровня человека останется маленький шаг.
Кому-то сложно это представить, поэтому вот график, на котором изображена кривая экспоненциального удвоения в петафлопсах (квадриллионах вычислений в секунду). В течение первых 70 лет цифровой эры компьютерная мощность удваивалась каждые пару лет, что привело к появлению программ бухгалтерского учёта, систем бронирования авиабилетов, прогнозов погоды, Spotify и так далее.
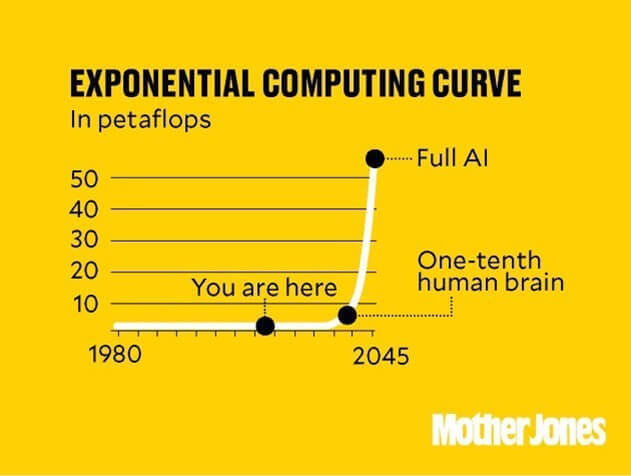
Экспоненциальная кривая вычислений (в петафлопсах): вы находитесь здесь; одна десятая человеческого мозга; полноценный ИИ
Но в масштабах человеческого мозга, который оценивают мощностью от 10 до 50 петафлопсов, это прирост столь мизерный, что не видно никаких изменений. К 2025 году мы наконец начнём замечать видимый прогресс на пути к искусственному интеллекту.
Через десять лет мы достигнем примерно десятой части мощи человеческого мозга, а ещё через десять лет получим полноценный ИИ уровня человека. Нам покажется, что это случилось в одночасье, но в действительности это итог сотни лет постоянного, но незаметного прогресса.
Неужели мы действительно подошли настолько близко к созданию настоящего ИИ? Подумайте вот над чем. Несмотря на всё это «удвоение», до недавнего времени ИТ-специалисты полагали, что только через десятки лет машина сможет выиграть в древнюю игру Го, которая считается самой сложной из существующих человеческих игр.
Но в прошлом году компьютер победил корейского гроссмейстера, считавшегося одним из лучших игроков, а в этом году - игрока в Го, возглавляющего мировой рейтинг. Прогресс развития искусственного интеллекта не только не замедляется - он опережает самые смелые мечты преданных фанатов ИИ.
К несчастью для тех, кого беспокоит перспектива остаться без работы из-за роботов, эти изменения означают, что массовая безработица намного ближе, чем мы боялись. Возможно, она уже начинается. Но вы не узнаете об этом от политиков, которые обходят вопрос молчанием.
Мы на пороге ИИ-революции. Многие из тех, кто работает в ИТ - такие люди, как Билл Гейтс и Илон Маск, - бьют тревогу не первый год. Но их игнорируют политики и до недавнего времени часто высмеивали авторы, пишущие на темы технологий и экономики. Давайте взглянем на некоторые из наиболее популярных аргументов ИИ-скептиков.
«Мы никогда не получим настоящий ИИ, потому что компьютерная мощность не будет удваиваться вечно. Мы достигнем пределов физики задолго до этого»
Есть несколько веских причин не учитывать эти заявления. Для начала, специалисты изобретут более быстрые, специализированные микропроцессоры. Google, например, прошлой весной анонсировала создание «тензорного процессора». Этот микропроцессор работает до 30 раз быстрее и до 80 раз энергоэффективнее для задач машинного обучения, чем процессор Intel.
«Тензорные процессоры» теперь доступны исследователям, использующим облачные сервисы Google. Другие процессоры, заточенные под задачи отдельных аспектов ИИ (распознавание изображений, нейронные сети, обработка текстов и так далее), или уже существуют, или скоро появятся.
Эти технологии всё лучше копируют работу человеческого мозга. У мозга нет сверхмощного вычислительного устройства. Он состоит из около 100 млрд нейронов, которые параллельно поддерживают умственную работу человека и его сознание.
На нижнем уровне нейроны действуют параллельно, создавая маленькие кластеры, которые осуществляют полуавтономные действия, такие, как ответ на определённый внешний стимул. На следующем уровне десятки этих кластеров работают вместе в каждом из около 100 подчинённых отделов мозга - отдельных центров, которые специализируются на конкретных функциях, например, речь, обработка визуальных сигналов и сохранение равновесия.
Наконец, все эти подчинённые отделы мозга тоже работают параллельно. Результат этой работы, общее состояние, мониторится и управляется высшими мозговыми функциями, которые позволяют нам воспринимать мир и дают чувство осознанного контроля своих действий.
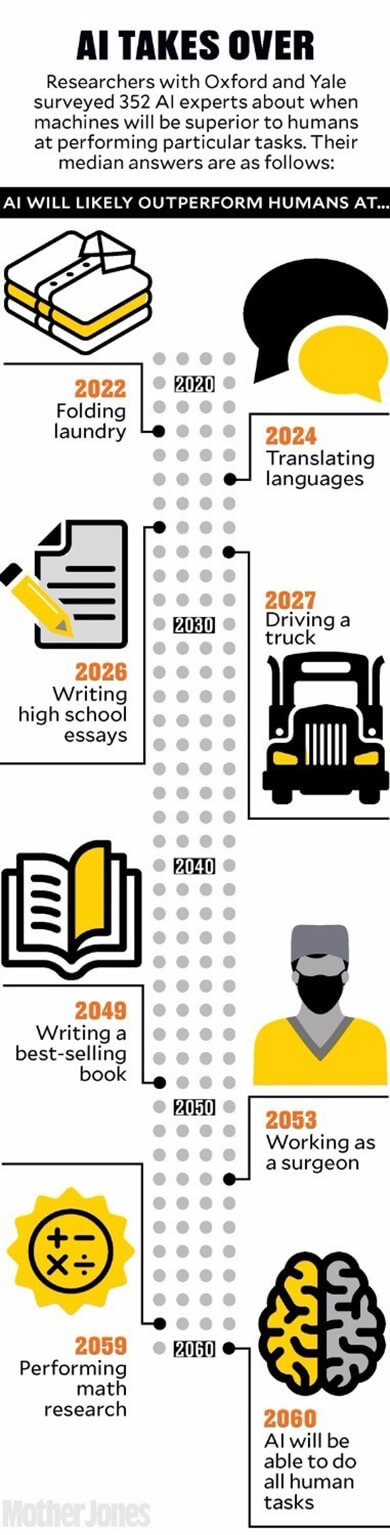
ИИ берёт верх
Исследователи из Оксфорда и Йеля спросили 352 экспертов в области ИИ, когда машины превзойдут людей в выполнении определённых задач. Вот что ответили эксперты.
ИИ сможет лучше человека:
Современные компьютеры также объединяют в своей работе много микропроцессоров. По состоянию на 2017 год, самый быстрый компьютер в мире использует приблизительно 40 тысяч процессоров с 260 ядрами каждый. Это больше 10 млн процессорных ядер, работающих одновременно. У каждого из этих ядер мощность меньше, чем у процессора Intel в вашем компьютере, но машина обладает примерно такой же мощностью, как человеческий мозг.
Это не означает, что мы уже создали ИИ. До этого ещё далеко. Эта массивная и всё ещё невероятно сложная для программирования задач архитектура. Но чем лучше мы используем эту архитектуру, тем вероятнее будут частые прорывы в работе алгоритмов.
Другими словами, даже если закон Мура нарушится или вообще перестанет действовать, общая мощность наверняка продолжит расти ещё много лет.
«Предположим, компьютерная мощность продолжит удваиваться. Но это происходит уже десятки лет! Вы, ребята, продолжаете предсказывать приход полноценного ИИ, но это никогда не случится»
В начале компьютерной эры существовало оптимистичное представление о том, что мы быстро сможем построить «умные» машины. Конец мечтам пришёл в 1970 годах, когда специалисты поняли, что даже самые быстродействующие на тот день ЭВМ производили только около одной миллиардной части от вычислительной мощности человеческого мозга. Осознание умерило пыл работников отрасли, с тех пор они смотрят на её прогресс даже слишком реалистично.
Мы наконец создали компьютеры, которые почти достигли чистой вычислительной мощности человеческого мозга, хотя они и стоят более $100 млн. И неизвестно, способна ли внутренняя архитектура этого суперкомпьютера соперничать с человеческим мозгом или нет.
Но через десять лет этот уровень мощности, скорее всего, будет доступен дешевле $1 млн, и тысячи команд будут тестировать алгоритмы ИИ на платформе, которая действительно способна конкурировать с людьми.
«Возможно, мы получим полноценный ИИ. Это означает только то, что роботы будут вести себя интеллектуально, а не то, что они на самом деле будут «умными»
Это всего лишь тема для утомительной философской дискуссии. Работодателю всё равно, есть ли у «умного» компьютера душа, может ли он любить, чувствовать боль, знает ли, что такое лояльность. Важно только, достаточно ли он похож на человека, чтобы повторить его действия.
Когда ИИ сможет копировать человека, все мы лишимся работы, даже если компьютеры, которые придут на наше место, не будут интеллектуальными.
«Каждая волна автоматизации (паровой двигатель, электричество, компьютер) порождала предсказания массовой безработицы. Вместо этого мы просто стали функционировать эффективнее. С ИИ-революцией будет то же самое»
Популярный аргумент. Но катастрофически ошибочный.
продолжение тут
Автоматизация помогла наступить эпохе Трампа. Что нам готовит ИИ
В ближайшие 40 лет роботы займут ваши рабочие места.
Неважно, кем вы работаете. Копаете траншеи? Робот будет копать их лучше. Пишете статьи для журнала? Робот будет писать лучше вас. Если вы врач, Watson от IBM больше не будет помогать вам с поиском правильного диагноза в его базе данных с миллионами описаний клинических случаев и журнальных статей. Он просто будет лечить лучше, чем вы.
Вы генеральный директор компании? Мне жаль, но роботы будут управлять компаниями лучше, чем вы. Люди творческих профессий? Роботы будут рисовать, писать и лепить лучше вас. Думаете, что ваши социальные навыки недоступны роботам? Очень даже доступны. В течение 20 лет примерно половина из вас лишится работы. Ещё через пару десятилетий та же участь ждёт большинство оставшихся.
В каком-то смысле звучит здорово. Пусть роботы работают! Не придётся больше вытаскивать себя из постели в шесть утра или проводить весь день на ногах. Мы сможем спокойно читать, писать стихи, играть в видеоигры и вообще делать что угодно. И через столетие, скорее всего, так и будет. Человечество вступит в золотой век.
Но что случится через 20 лет? Или 30? Многие к тому времени потеряют работу. Поверьте, это не будет похоже на золотой век. Пока мы не выясним, как справедливо распределить плоды труда роботов, нас ожидает эпоха массовой безработицы и нищеты. Безработица среди рабочего класса сыграла большую роль в выборах 2016 года в США.
Если мы не хотим стать свидетелями того, как демагоги сменяют друг друга у власти из-за того, что машины отнимают у людей средства к существованию, этому нужно положить конец как можно скорее. Наряду с глобальным потеплением, будущее без работы - главная проблема, которая стоит перед прогрессивными политиками, не говоря уже про человечество в целом. Но сейчас эта проблема едва попадает в поле нашего зрения.
Вот занудство, да? К счастью, статьи на сложную или узкоспециальную тему традиционно начинаются с какого-нибудь забавного или необычного случая. Это помогает читателю медленно погрузиться в пугающий своей сложностью материал. Я тоже расскажу вам об одном таком случае.
На прошлое Рождество я был в доме своей матери. Там я упомянул, что недавно прочёл статью про Google Translate. Оказалось, что за несколько недель до этого, никому не сообщив, Google перешла на новый алгоритм машинного обучения. Качество переводов резко подскочило. Я и сам заметил улучшения, но списал их на обычный поступательный прогресс. Я не понял, что это произошло благодаря скачку в работе алгоритмов.
Но если алгоритм переводов Google стал лучше, значит ли это, что распознавание голоса тоже стало лучше? И способность отвечать на вопросы? Как бы нам это проверить? Мы решили распаковать подарки вместо того, чтобы размышлять об этом.
Потом мы непонятно как перешли на тему ластиков. Какие ластики лучше? Светлые? Чёрные? Традиционные розовые? Если подумать, почему они вообще обычно розовые? «Спрошу Google!» - сказал я. После чего достал телефон и задал вопрос: «Почему ластики розовые?» Через полсекунды Google мне ответил.
Художник Роберто Парада
Не впечатлены? А должны быть. Все мы знаем, что телефоны неплохо умеют распознавать голос. И мы знаем, что они могут найти ближайшее кафе или популярный рецепт курицы в вине. Но как насчёт совершенно случайного вопроса? И не лёгкого «кто», «где» или «когда»?
Я задал вопрос «почему», и он был не о том, например, почему певица Pink использует ластики. Google должен сообразить, что я сказал «розовые», что я интересуюсь историческими причинами цвета резинок, а не их состоянием или формой. И он это сделал. Меньше, чем за секунду. Имея в своём распоряжении дешёвый микропроцессор и медленное подключение к интернету.
Если вам интересно, Google взял ответ у Design*Sponge: «Производить ластики начала компания Eberhard Faber… Резинки имели в своём составе пемзу - вулканический пепел из Италии, который придавал им абразивные свойства, а также характерный цвет и запах».
Всё ещё не впечатлены? В те времена, когда Watson выиграл раунд телевикторины Jeopardy против двух лучших игроков всех времён, ему понадобился бы компьютер величиной со спальную комнату, чтобы ответить на такой вопрос. Это было всего семь лет назад.
Какое отношение розовые ластики имеют к тому, что все мы останемся без работы через пару десятков лет? Рассказываю. В прошлом октябре сервис грузовых перевозок Otto (дочерняя компания Uber) перевёз две тысячи ящиков Budweiser на расстояние 120 миль из Форт-Коллинза, штат Колорадо, в Колорадо-Спрингс - без водителя за рулём.
За несколько лет эта технология пройдёт путь от прототипа до внедрения, а это значит, что миллионы водителей грузовиков останутся без работы.
Автоматизированные грузовые перевозки не опираются на новомодные машины, как промышленная революция 19 века опиралась на механический ткацкий станок и паровой экскаватор. Как и способность Google распознавать речь и отвечать на вопросы, беспилотные грузовики, а также автомобили, автобусы и корабли полагаются на программы, которые копируют человеческий интеллект.
Теперь все уже слышали прогнозы, по которым беспилотные автомобили могут привести к потере 5 млн рабочих мест. Но немногие понимают, что как только алгоритмы ИИ будут готовы к вождению, они будут готовы и ко многому другому. Не миллионы людей потеряют работу - десятки миллионов.
Вот что мы имеем в виду, когда говорим «роботы». Мы говорим о когнитивных способностях, а не о существах, которые сделаны из металла и питаются электричеством, а не куриными наггетсами.
Другими словами, нужно смотреть не на подвижки в робототехнике, а на скорость, с которой мы мчимся навстречу искусственному интеллекту. Пусть мы пока и близко не подошли к ИИ на уровне человеческого интеллекта, прогресс последней пары десятилетий поражает.
Много лет технологии стояли на месте, и вдруг роботы играют в шахматы лучше гроссмейстеров. Они играют в Jeopardy лучше рекордсменов. Они могут водить автомобили по Сан-Франциско и становятся в этом лучше год от года.
Они так хорошо распознают лица, что полиция Уэльса недавно совершила первый в Великобритании арест, используя программу распознавания лиц. После нескольких лет медленного прогресса в распознавании речи Google объявил, что снизил уровень ошибок в распознавании с 8,5% до 4,9% за десять месяцев.
Всё это говорит о том, что ИИ развивается экспоненциально благодаря улучшению как компьютерного оборудования, так и алгоритмов. По закону Мура, мощность и производительность процессоров удваиваются каждые два года. Недавние усовершенствования алгоритмов были ещё более стремительными. Долгое время эти подвижки казались незначительными.
Переход от интеллекта бактерии к интеллекту нематоды технически представляет собой огромный скачок, но на практике не приближает нас к настоящему искусственному интеллекту. Однако, если удвоение будет продолжаться, один из циклов удвоения приведёт к переходу от интеллекта ящерицы к интеллекту мыши, а затем и к интеллекту обезьяны. Как только это произойдёт, до ИИ уровня человека останется маленький шаг.
Кому-то сложно это представить, поэтому вот график, на котором изображена кривая экспоненциального удвоения в петафлопсах (квадриллионах вычислений в секунду). В течение первых 70 лет цифровой эры компьютерная мощность удваивалась каждые пару лет, что привело к появлению программ бухгалтерского учёта, систем бронирования авиабилетов, прогнозов погоды, Spotify и так далее.
Экспоненциальная кривая вычислений (в петафлопсах): вы находитесь здесь; одна десятая человеческого мозга; полноценный ИИ
Но в масштабах человеческого мозга, который оценивают мощностью от 10 до 50 петафлопсов, это прирост столь мизерный, что не видно никаких изменений. К 2025 году мы наконец начнём замечать видимый прогресс на пути к искусственному интеллекту.
Через десять лет мы достигнем примерно десятой части мощи человеческого мозга, а ещё через десять лет получим полноценный ИИ уровня человека. Нам покажется, что это случилось в одночасье, но в действительности это итог сотни лет постоянного, но незаметного прогресса.
Неужели мы действительно подошли настолько близко к созданию настоящего ИИ? Подумайте вот над чем. Несмотря на всё это «удвоение», до недавнего времени ИТ-специалисты полагали, что только через десятки лет машина сможет выиграть в древнюю игру Го, которая считается самой сложной из существующих человеческих игр.
Но в прошлом году компьютер победил корейского гроссмейстера, считавшегося одним из лучших игроков, а в этом году - игрока в Го, возглавляющего мировой рейтинг. Прогресс развития искусственного интеллекта не только не замедляется - он опережает самые смелые мечты преданных фанатов ИИ.
К несчастью для тех, кого беспокоит перспектива остаться без работы из-за роботов, эти изменения означают, что массовая безработица намного ближе, чем мы боялись. Возможно, она уже начинается. Но вы не узнаете об этом от политиков, которые обходят вопрос молчанием.
Мы на пороге ИИ-революции. Многие из тех, кто работает в ИТ - такие люди, как Билл Гейтс и Илон Маск, - бьют тревогу не первый год. Но их игнорируют политики и до недавнего времени часто высмеивали авторы, пишущие на темы технологий и экономики. Давайте взглянем на некоторые из наиболее популярных аргументов ИИ-скептиков.
«Мы никогда не получим настоящий ИИ, потому что компьютерная мощность не будет удваиваться вечно. Мы достигнем пределов физики задолго до этого»
Есть несколько веских причин не учитывать эти заявления. Для начала, специалисты изобретут более быстрые, специализированные микропроцессоры. Google, например, прошлой весной анонсировала создание «тензорного процессора». Этот микропроцессор работает до 30 раз быстрее и до 80 раз энергоэффективнее для задач машинного обучения, чем процессор Intel.
«Тензорные процессоры» теперь доступны исследователям, использующим облачные сервисы Google. Другие процессоры, заточенные под задачи отдельных аспектов ИИ (распознавание изображений, нейронные сети, обработка текстов и так далее), или уже существуют, или скоро появятся.
Эти технологии всё лучше копируют работу человеческого мозга. У мозга нет сверхмощного вычислительного устройства. Он состоит из около 100 млрд нейронов, которые параллельно поддерживают умственную работу человека и его сознание.
На нижнем уровне нейроны действуют параллельно, создавая маленькие кластеры, которые осуществляют полуавтономные действия, такие, как ответ на определённый внешний стимул. На следующем уровне десятки этих кластеров работают вместе в каждом из около 100 подчинённых отделов мозга - отдельных центров, которые специализируются на конкретных функциях, например, речь, обработка визуальных сигналов и сохранение равновесия.
Наконец, все эти подчинённые отделы мозга тоже работают параллельно. Результат этой работы, общее состояние, мониторится и управляется высшими мозговыми функциями, которые позволяют нам воспринимать мир и дают чувство осознанного контроля своих действий.
ИИ берёт верх
Исследователи из Оксфорда и Йеля спросили 352 экспертов в области ИИ, когда машины превзойдут людей в выполнении определённых задач. Вот что ответили эксперты.
ИИ сможет лучше человека:
2022 - сложить бельё из стирки.
2024 - сделать перевод с иностранного языка.
2026 - написать эссе для учащегося средней школы.
2027 - водить грузовик.
2049 - написать бестселлер.
2053 - работать хирургом.
2059 - выполнить математическое исследование.
2060 - решить любую другую задачу.
Современные компьютеры также объединяют в своей работе много микропроцессоров. По состоянию на 2017 год, самый быстрый компьютер в мире использует приблизительно 40 тысяч процессоров с 260 ядрами каждый. Это больше 10 млн процессорных ядер, работающих одновременно. У каждого из этих ядер мощность меньше, чем у процессора Intel в вашем компьютере, но машина обладает примерно такой же мощностью, как человеческий мозг.
Это не означает, что мы уже создали ИИ. До этого ещё далеко. Эта массивная и всё ещё невероятно сложная для программирования задач архитектура. Но чем лучше мы используем эту архитектуру, тем вероятнее будут частые прорывы в работе алгоритмов.
Другими словами, даже если закон Мура нарушится или вообще перестанет действовать, общая мощность наверняка продолжит расти ещё много лет.
«Предположим, компьютерная мощность продолжит удваиваться. Но это происходит уже десятки лет! Вы, ребята, продолжаете предсказывать приход полноценного ИИ, но это никогда не случится»
В начале компьютерной эры существовало оптимистичное представление о том, что мы быстро сможем построить «умные» машины. Конец мечтам пришёл в 1970 годах, когда специалисты поняли, что даже самые быстродействующие на тот день ЭВМ производили только около одной миллиардной части от вычислительной мощности человеческого мозга. Осознание умерило пыл работников отрасли, с тех пор они смотрят на её прогресс даже слишком реалистично.
Мы наконец создали компьютеры, которые почти достигли чистой вычислительной мощности человеческого мозга, хотя они и стоят более $100 млн. И неизвестно, способна ли внутренняя архитектура этого суперкомпьютера соперничать с человеческим мозгом или нет.
Но через десять лет этот уровень мощности, скорее всего, будет доступен дешевле $1 млн, и тысячи команд будут тестировать алгоритмы ИИ на платформе, которая действительно способна конкурировать с людьми.
«Возможно, мы получим полноценный ИИ. Это означает только то, что роботы будут вести себя интеллектуально, а не то, что они на самом деле будут «умными»
Это всего лишь тема для утомительной философской дискуссии. Работодателю всё равно, есть ли у «умного» компьютера душа, может ли он любить, чувствовать боль, знает ли, что такое лояльность. Важно только, достаточно ли он похож на человека, чтобы повторить его действия.
Когда ИИ сможет копировать человека, все мы лишимся работы, даже если компьютеры, которые придут на наше место, не будут интеллектуальными.
«Каждая волна автоматизации (паровой двигатель, электричество, компьютер) порождала предсказания массовой безработицы. Вместо этого мы просто стали функционировать эффективнее. С ИИ-революцией будет то же самое»
Популярный аргумент. Но катастрофически ошибочный.
продолжение тут