Интеграция Picasa и Lightroom
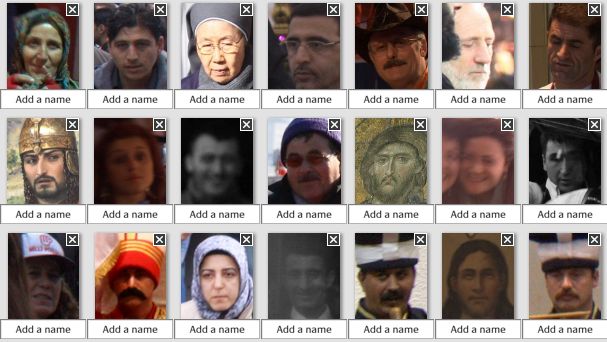
Цель эксперимента: облегчить поиск людей на фотографиях. Не каких-то конкретных, а вообще фотографий, на которых есть люди. Очень удобно, когда ты можешь по-быстренькому выбрать из набора типажей.
Граничные условия: теги должны быть в фотографиях в Лайтруме. Ибо он - основная среда для работы, остальное - баловство.
Задумка: Picasa умеет искать на фотографиях лица. Следовательно если найти с её помощью все лица и пометить эти фотографии одним тегом (например «faces»), то цель будет достигнута.
Особенности реализации и камни на пути. На практике всё оказалось сложнее.
Во-первых, Пикаса слабо настраиваема. Это одна из программ в любимом стиле Apple: «Мы считаем, что стопроцентно позаботились о юзабилити, а если вам что не нравится, идите в жопу, яблокофоб». Т.е., идеи зашиты в практически ненастраиваемый интерфейс. Идеи иногда очень хорошие, а иногда глупые. Но исправить ты всё равно ничего не можешь, потому что создатели софта считают тебя несмышлёнышем, лучшая одёжка которому - смирительная рубашка. В нашем случае эта «рубашка» проявилась в невозможности задать минимальный размер лица. Ну не нужны мне лица высотой в пять пикселей, выхваченные из толпы. А уж как сложно понять - Пикаса уже обработала все фотографии, или ещё будет что-то доделывать? Надпись «найдено 500 лиц, осталось обработать ещё 3000» через полчаса меняется на «найдено 501 лицо, осталось обработать ещё 20,000, займёт 19 часов», а ещё через пять минут на «найдено 358 лиц, осталось обработать ещё 500».
Во-вторых, Пикаса - тормоз. Её просмотрщик мне нравится скоростью, а сама Пикаса как раз тормознутостью и не нравится. Обработка каталога из 20К фотографий заняла больше суток.
В-третьих, Пикаса не пишет теги в EXIF. Surprise! Пикаса пишет теги в собственный файл «.picasa.ini» в той же папке, где и фото. Эта проблема была решена с помощью написания скрипта, который парсил эти файлы, тащил из них ключевые слова и переносил их в картинки (и XMP) с помощью exiftool.
В-четвёртых, Лайтрум не может отличить изменённые картинки от остальных. Поэтому приходится считывать метаданные из всех, что тоже занимает время. Можно было бы попробовать сделать инъекции в его бд на sqlite3, но имхо это уже чересчур.
Результат. Помечено 1400+ картинок с лицами. Беглый взгляд на каталог показывает, что ещё как минимум столько же не найдено, причём совершенно очевидных годных лиц. Я бы спокойно отнёсся и к ложным срабатываниям, и к пятипиксельным физиономиям, если бы охват был стопроцентный. А так непонятно, ради чего система напрягалась, творила чудеса распознавания, если не сумела разглядеть портрет в анфас во весь кадр.
Выводы. Эксперимент признать неудачным. Трудозатраты велики, выход мал. Просто фигуры людей не отмечены, много нужно доделывать. С оговоркой - технология переноса тегов из Picasa в Lightroom отлажена, так что если потребуется отметить лица или перенести другие теги (не представляю пока, зачем), то это можно будет сделать легко.
Bonus. В XMP ключевые слова эксифтулом нужно писать не аргументом «-keywords», а «-XMP-dc:Subject+="слово"». А в JPG ещё и «-IPTC:keywords+="слово"».