Индоевропейские языки и деление кентум-сатем.
Очень много сломано копий о делении кентум-сатем индоевропейских языков, от полного не понимания что это такое, до полной лжи и его отрицания. Причем в ложь опускаются даже негодяи от академической науки чтобы подделать результаты. Разберемся что это такое со строго научной точки зрения.
Изоглоссой кентум-сатем называется переход трех рядов велярных в два ряда велярных в двух группах языков, соответственно кентумной группе и сатемной группе. В праиндоевропеском языке были три ряда велярных: палатовелярные (мягкие) K', обычные велярные K, лабиовелярные Kʷ, таково общепринятая реконструкция. Хотя ранее существовали точки зрения о том что в праиндоевропейском существовали только два ряда велярных, такой точки зрения придерживался Мейе не восстанавливая ряд палатовелярных которые он рассматривал как появившийся перед передними гласными в совершенно неопределенных условиях, он не дал даже намека на гипотезу как же появились палатовелярные в группе сатем, поэтому его точка зрения была категорически не принята никем из лингвистов; другую точку зрения высказал В.В. Иванов исследуя хеттский язык в котором лабиовелярные не отличаются от велярного согласного перед лабиальным гласным, что лабиовелярных в праиндоевропейском языке не было и они появились позднее в группе кентум.
Этот переход заключался в следующей формуле:
Праиндоевропейский
Сатем
Кентум
*K'
*K'
*K
*K
*K
*K
*Kʷ
*K
*Kʷ
То есть один из двух сложных рядов совпал с обычными велярными, что является примером упрощения фонетической системы. Хочу заметить что это произошло во всех языках и тут нет никакой палатализации с которой часто путают сатемную изоглоссу.
Как видно из этой таблички все языки изменяются одинаково, упрощая сложную трехрядную систему в двухрядную, но по своему, в кентумных языках палатовелярные совпали с велярными, в сатемных языках лабиовелярные совпали с велярными. Никто из них не сохраняет древнее состояние и не является более архаичным или более инновационным. С типологической точки зрения переход лабиовелярных в обычные велярные типологически обоснованно и является совершенно обычным делом, лабиовелярные вообще неустойчивый ряд, а переход палатовелярных в обычные велярные является типологически необоснованным (маргинальным), данный ряд является очень устойчивым, и такое происходит обычно из-за воздействия иноязычного субстрата который не умеет выговаривать мягкие согласные.
И уже далее в каждой группе языков происходят процессы палатализации и лабиализации причем в каждом языке независимо друг от друга. Обычно палатализацию путают с сатемизацией, но это совершенно разные вещи, палатализация это совсем другое, палатализация это переход палатализованных (мягких) согласных в палатальные согласные: С' > S (то есть обычно в сибилянты как в праславянском сатемный k' > с, по первой палатализации k' > ч, по второй палатализации k' > ц), палатализованные согласные и соответственно палатализация возникает не только из палатализованного ряда, но и перед любыми передними согласными и не только в сатемных языках, где этот процесс постоянный на протяжении многих тысяч лет, но эпизодически и в кентумных языках, например латинском и английском. Лабиализация это переход лабиализованных согласных в лабиальные: Cʷ > P. Палатализация это совершенно типологически обоснованный процесс, рано или поздно каждый палатализованный согласный перейдет в палатальный ряд, это вопрос времени, а вот лабиализация совершенно маргинальный процесс, он редок, в индоевропейских он произошел только в греческом, кельтском и частично в германском и части италийских, что объясняют как воздействие иноязычного субстрата.
Из-за такой двойственности этого процесса сатемизацию путают с палатализацией. Указывая на то что палатализация самый обычный процесс в языках отрицают существование самой изоглоссы кентум-сатем, что является в высшей мере антинаучной логикой, дескать она просто случайность. Но тут на помощь приходит другая изоглосса - правило РУКИ или закон Педерсена. Это правило гласит что во всех без исключения языках сатемной группы. и только в них, s после звуков r, k, i, u переходил в š[ш] (в славянском далее в х), причем это происходило автоматически (по существу, [s] и [š] не являлись разными фонемами, а являлись аллофонами одной фонемы /s/).
Что такое автоматическое изменение, в отличии от обычного фонетического перехода автоматическое изменение может держаться тысячи лет потому что обусловлено невозможностью произнести иначе данных звуков носителями данного языка. В санскрите закон Педерсена действует даже во внешних сандхи, то есть на границах слов, еще даже в ведическом и классическом санскрите, например, если предыдущее слово заканчивается на u, а следующее начинается на s, то это s произносится как š, потому что носитель языка не мог физически произнести s после РУКИ звуков, и это работает для любых слов. Тоже самое происходит и в русском языке с согласными стоящими перед передними гласными, любой согласный оказавшийся перед передней гласной приобретает палатализацию, то есть переходит из C в C' ([т]+[и] > [т'и] и носитель языка не может произнести т не смягченно), и так было что тысячу лет назад, что сейчас. Это сохраняется до сих пор, если мягкий согласный отвердевает, как это произошло с ш, ж, ц, то следующий за ней гласный произносится задним образом автоматически, хотя ранее до отвердевания он произносился передним образом, откуда правило что [жы] и [шы] пиши с буквой и; если наоборот задний гласный переходит в передний ряд, то автоматически твердый согласный становится мягким, кы > к'и. Эта автоматичность правила РУКИ приводила к тому что если в языке возникало некое ограничение на РУКИ-правило, то оно сразу проявляется во всех словах. В славянском такое ограничение возникло что если s стоит перед взрывными (T), то восстанавливается звук s, что было связанно с тем что комбинация sT трактовалась как один звук (особой четвертой серии), в нуристанских такое ограничение возникло так что u выпало из РУКИ ряда, и после него все s восстановились.
Закон Педерсена уникален, в мире нет языков его имеющих кроме сатемной группы индоевропейсикх языков, он ничем не мотивирован, он не имеет никакого фонетического объяснения и данная изоглосса не может заимствоваться, потому что ничем не мотивированна, возникнуть она могла только в языке-предке и передаться языкам-потомкам. Он есть только в сатемной группе индоевропейских языков которую можно с полным правом называть РУКИ-группой индоевропейских языков.
В данном вопросе доходило до прямой лжи и подлогов, причем даже со стороны неких типов претендующих на академические исследования. Самый известный и позорный это известная ошибочная книжка Гамкрелидзе и В.В.И., которая вообще опровергнута абсолютно по всем пунктам, так что в сумме опровержений будет в три раза больше чем сама книжка Гамкрелидзе. В своей лживой книженции Гамкрелидзе специально даже не упомянул Закон Педерсена, о его существовании, специально, ради подлога чтобы оправдать то, что он отрицает саму группу кентум-сатем и эту изоглоссу. В данном случае мы имеем прямое злономеренное злодейство со стороны грузина Гамкрелидзе помешанного на идеях фашиста Гамсахурдии первородного господства кавказцев над русскими. Он солгал злонамеренно, дело в том что он вначале нарисовал свое дерево языков высосанное из пальца по идеям 19-го века и использовал свой фрический метод по отобранным им подходящим изоглоссам чтобы сделать его правдоподобным, специально исключая те изоглоссы которые ему не подходили, которые разрушали всю его ложь, в чем он признался когда его спросили почему он не упомянул Закон Педерсена - чтобы нас всех обмануть что было важно для его фрического метода доказательства праиндоевропейскости многих слов, которые возникли много позже, но по его делению на и.-е. они оказывались праиндоевропейскими, в общем обман на обмане ради глобального обмана.
Это группа выделяется не только чисто лингвистически, но и генетически по Y-гаплогруппам с практически полным совпадением лингвистического дерева индоевропейских языков и дерева Y-гаплогруппы R1a с полным совпадением их дат разделений (TMRCA) в пределах погрешностей вычислений, что конечно же не является случайным. а является строго обоснованным с точки зрения популяционной генетики поскольку гаплогруппы распространялись в определенных популяциях которые коррелируют с языками.
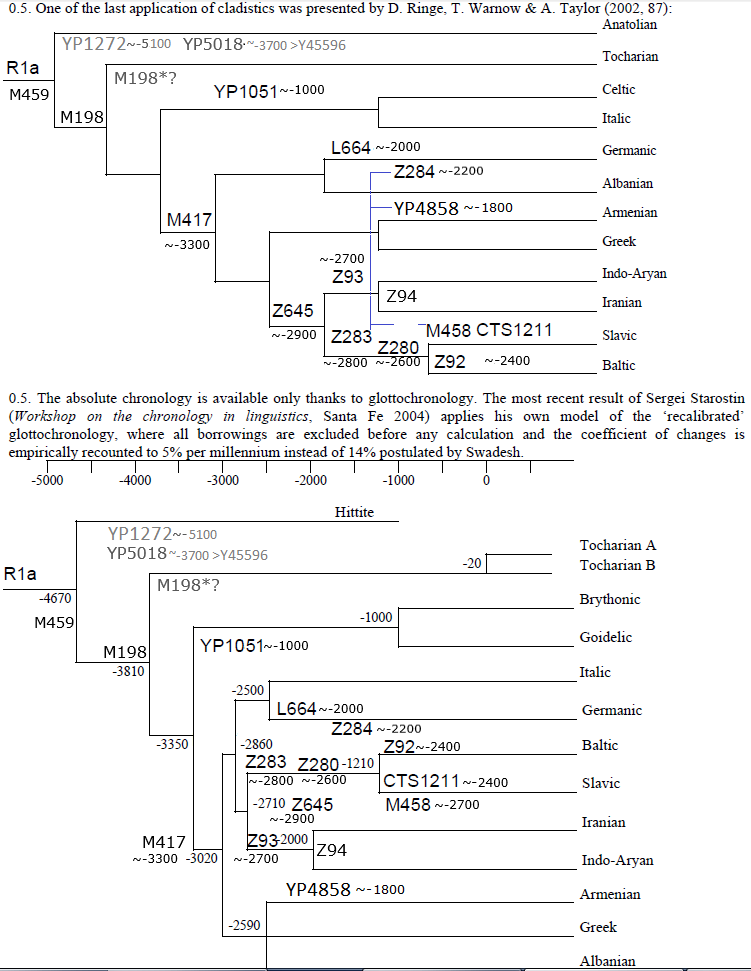
Объединения лингвистического дерева и.-е.языков с датами разделения языков с деревом R1a с датами TMRCA.
(Известно, что данное дерево сторонники клесовщины - Клесов и Рожанский категорически отвергли поскольку оно противоречит их выдуманным постулатам.)
Подобную корреляцию между гаплагруппами и языками установил Балановский для северокавказских языков.
Необходимы три комментария. О германо-итало-кельтских и албано-армяно-греческих языках.
1. Общепринято, что германский язык достаточно поздний, произошел из слияния нескольких близких диалектов, один древний который был у носителей R1a-L664 другой пребалтославянский у носителей R1a-Z284, на что указывал еще Порциг в середине 20-го века сопоставляя лексические изоглоссы и получается из расчетных лингвистических деревьев, изоглосс и лингвистических расчетов, поэтому у него проблемы с отнесением к ветвям на дереве, на многих лингвистических деревьях германские рисуются с двумя идущими в них ветвями.
Из-за этого еще большие проблемы возникают у италийских языков, они делятся на две ветви, которые имеют разные степени близости к германским и кельтским языкам. Поэтому, каждый при разных методиках получает разные варианты пристыковывания италийских то к кельтским, то к германским. По всей видимости верно всё же к кельтским, по крайней мере генетика поможет определить это. Но субклады R1a у кельтов и италийцев еще слабо исследованы.
2. Те же проблемы с армянским прошедшим значительную креолизацию с хуррито-урартскими и западно иранскими языками. Точно его отношение с греческим неизвестно, но они достаточно соотносятся, хотя это может быть все тот же греко-армяно-арийский языковой союз который был в северном Причерноморье между бабинской/КМК (прагреко-праармянской) и синташтинской (праиндоиранской) культурами.
3. Но совсем ничего нельзя сказать об албанском, это очень поздний латино-"бог знает какой" пиджин, неизвестно то ли с фракийским то ли с иллирийским то ли с неизвестной ветвью, его пристыковывают куда угодно поскольку ни доказать ни опровергнуть насчет него ничего невозможно. Субклады R1a у этих народов не исследованы совсем.
Больше всего лексических соответствий у албанцев с греческим и с германскими языками. Поскольку албанцы подвергались сильному влиянию греческого, то могут предполагать что германские соответствия есть исконные, а греческие позднее. Но это все волюнтаризм, зависящий от шума той или иной методики. Поскольку понятно что албанский является очень дальним для них родственником, он гораздо ближе к фракийскому и иллирийскому которые неизвестны совсем и для них ничего нельзя вычислить. Албанский либо является диалектом дако-фракийского либо его близким родственником, поскольку албанцы ранее точно обитали восточнее современного ареала, а иллирийские соответствия можно рассматривать как субстрат. Для этих двух языков все равно неизвестно их отношение к греческому и к германским, а следовательно и для албанского тоже. Без знания степени близости иллирийского и фракийского к греческому и к германскому нельзя правильно вычислить степень близости к последним албанского. Так что оба дерева относительно албанского столь же правильны столь и не правильны.
Литература:
Чекман В. Н. Древнейшая балто-славо-индоиранская изоглосса (*si-k > *š). // Балто-славянские исследования. 1980. - М.: Наука, 1981. - С. 27-37.
Изоглоссой кентум-сатем называется переход трех рядов велярных в два ряда велярных в двух группах языков, соответственно кентумной группе и сатемной группе. В праиндоевропеском языке были три ряда велярных: палатовелярные (мягкие) K', обычные велярные K, лабиовелярные Kʷ, таково общепринятая реконструкция. Хотя ранее существовали точки зрения о том что в праиндоевропейском существовали только два ряда велярных, такой точки зрения придерживался Мейе не восстанавливая ряд палатовелярных которые он рассматривал как появившийся перед передними гласными в совершенно неопределенных условиях, он не дал даже намека на гипотезу как же появились палатовелярные в группе сатем, поэтому его точка зрения была категорически не принята никем из лингвистов; другую точку зрения высказал В.В. Иванов исследуя хеттский язык в котором лабиовелярные не отличаются от велярного согласного перед лабиальным гласным, что лабиовелярных в праиндоевропейском языке не было и они появились позднее в группе кентум.
Этот переход заключался в следующей формуле:
Праиндоевропейский
Сатем
Кентум
*K'
*K'
*K
*K
*K
*K
*Kʷ
*K
*Kʷ
То есть один из двух сложных рядов совпал с обычными велярными, что является примером упрощения фонетической системы. Хочу заметить что это произошло во всех языках и тут нет никакой палатализации с которой часто путают сатемную изоглоссу.
Как видно из этой таблички все языки изменяются одинаково, упрощая сложную трехрядную систему в двухрядную, но по своему, в кентумных языках палатовелярные совпали с велярными, в сатемных языках лабиовелярные совпали с велярными. Никто из них не сохраняет древнее состояние и не является более архаичным или более инновационным. С типологической точки зрения переход лабиовелярных в обычные велярные типологически обоснованно и является совершенно обычным делом, лабиовелярные вообще неустойчивый ряд, а переход палатовелярных в обычные велярные является типологически необоснованным (маргинальным), данный ряд является очень устойчивым, и такое происходит обычно из-за воздействия иноязычного субстрата который не умеет выговаривать мягкие согласные.
И уже далее в каждой группе языков происходят процессы палатализации и лабиализации причем в каждом языке независимо друг от друга. Обычно палатализацию путают с сатемизацией, но это совершенно разные вещи, палатализация это совсем другое, палатализация это переход палатализованных (мягких) согласных в палатальные согласные: С' > S (то есть обычно в сибилянты как в праславянском сатемный k' > с, по первой палатализации k' > ч, по второй палатализации k' > ц), палатализованные согласные и соответственно палатализация возникает не только из палатализованного ряда, но и перед любыми передними согласными и не только в сатемных языках, где этот процесс постоянный на протяжении многих тысяч лет, но эпизодически и в кентумных языках, например латинском и английском. Лабиализация это переход лабиализованных согласных в лабиальные: Cʷ > P. Палатализация это совершенно типологически обоснованный процесс, рано или поздно каждый палатализованный согласный перейдет в палатальный ряд, это вопрос времени, а вот лабиализация совершенно маргинальный процесс, он редок, в индоевропейских он произошел только в греческом, кельтском и частично в германском и части италийских, что объясняют как воздействие иноязычного субстрата.
Из-за такой двойственности этого процесса сатемизацию путают с палатализацией. Указывая на то что палатализация самый обычный процесс в языках отрицают существование самой изоглоссы кентум-сатем, что является в высшей мере антинаучной логикой, дескать она просто случайность. Но тут на помощь приходит другая изоглосса - правило РУКИ или закон Педерсена. Это правило гласит что во всех без исключения языках сатемной группы. и только в них, s после звуков r, k, i, u переходил в š[ш] (в славянском далее в х), причем это происходило автоматически (по существу, [s] и [š] не являлись разными фонемами, а являлись аллофонами одной фонемы /s/).
Что такое автоматическое изменение, в отличии от обычного фонетического перехода автоматическое изменение может держаться тысячи лет потому что обусловлено невозможностью произнести иначе данных звуков носителями данного языка. В санскрите закон Педерсена действует даже во внешних сандхи, то есть на границах слов, еще даже в ведическом и классическом санскрите, например, если предыдущее слово заканчивается на u, а следующее начинается на s, то это s произносится как š, потому что носитель языка не мог физически произнести s после РУКИ звуков, и это работает для любых слов. Тоже самое происходит и в русском языке с согласными стоящими перед передними гласными, любой согласный оказавшийся перед передней гласной приобретает палатализацию, то есть переходит из C в C' ([т]+[и] > [т'и] и носитель языка не может произнести т не смягченно), и так было что тысячу лет назад, что сейчас. Это сохраняется до сих пор, если мягкий согласный отвердевает, как это произошло с ш, ж, ц, то следующий за ней гласный произносится задним образом автоматически, хотя ранее до отвердевания он произносился передним образом, откуда правило что [жы] и [шы] пиши с буквой и; если наоборот задний гласный переходит в передний ряд, то автоматически твердый согласный становится мягким, кы > к'и. Эта автоматичность правила РУКИ приводила к тому что если в языке возникало некое ограничение на РУКИ-правило, то оно сразу проявляется во всех словах. В славянском такое ограничение возникло что если s стоит перед взрывными (T), то восстанавливается звук s, что было связанно с тем что комбинация sT трактовалась как один звук (особой четвертой серии), в нуристанских такое ограничение возникло так что u выпало из РУКИ ряда, и после него все s восстановились.
Закон Педерсена уникален, в мире нет языков его имеющих кроме сатемной группы индоевропейсикх языков, он ничем не мотивирован, он не имеет никакого фонетического объяснения и данная изоглосса не может заимствоваться, потому что ничем не мотивированна, возникнуть она могла только в языке-предке и передаться языкам-потомкам. Он есть только в сатемной группе индоевропейских языков которую можно с полным правом называть РУКИ-группой индоевропейских языков.
В данном вопросе доходило до прямой лжи и подлогов, причем даже со стороны неких типов претендующих на академические исследования. Самый известный и позорный это известная ошибочная книжка Гамкрелидзе и В.В.И., которая вообще опровергнута абсолютно по всем пунктам, так что в сумме опровержений будет в три раза больше чем сама книжка Гамкрелидзе. В своей лживой книженции Гамкрелидзе специально даже не упомянул Закон Педерсена, о его существовании, специально, ради подлога чтобы оправдать то, что он отрицает саму группу кентум-сатем и эту изоглоссу. В данном случае мы имеем прямое злономеренное злодейство со стороны грузина Гамкрелидзе помешанного на идеях фашиста Гамсахурдии первородного господства кавказцев над русскими. Он солгал злонамеренно, дело в том что он вначале нарисовал свое дерево языков высосанное из пальца по идеям 19-го века и использовал свой фрический метод по отобранным им подходящим изоглоссам чтобы сделать его правдоподобным, специально исключая те изоглоссы которые ему не подходили, которые разрушали всю его ложь, в чем он признался когда его спросили почему он не упомянул Закон Педерсена - чтобы нас всех обмануть что было важно для его фрического метода доказательства праиндоевропейскости многих слов, которые возникли много позже, но по его делению на и.-е. они оказывались праиндоевропейскими, в общем обман на обмане ради глобального обмана.
Это группа выделяется не только чисто лингвистически, но и генетически по Y-гаплогруппам с практически полным совпадением лингвистического дерева индоевропейских языков и дерева Y-гаплогруппы R1a с полным совпадением их дат разделений (TMRCA) в пределах погрешностей вычислений, что конечно же не является случайным. а является строго обоснованным с точки зрения популяционной генетики поскольку гаплогруппы распространялись в определенных популяциях которые коррелируют с языками.
Объединения лингвистического дерева и.-е.языков с датами разделения языков с деревом R1a с датами TMRCA.
(Известно, что данное дерево сторонники клесовщины - Клесов и Рожанский категорически отвергли поскольку оно противоречит их выдуманным постулатам.)
Подобную корреляцию между гаплагруппами и языками установил Балановский для северокавказских языков.
Необходимы три комментария. О германо-итало-кельтских и албано-армяно-греческих языках.
1. Общепринято, что германский язык достаточно поздний, произошел из слияния нескольких близких диалектов, один древний который был у носителей R1a-L664 другой пребалтославянский у носителей R1a-Z284, на что указывал еще Порциг в середине 20-го века сопоставляя лексические изоглоссы и получается из расчетных лингвистических деревьев, изоглосс и лингвистических расчетов, поэтому у него проблемы с отнесением к ветвям на дереве, на многих лингвистических деревьях германские рисуются с двумя идущими в них ветвями.
Из-за этого еще большие проблемы возникают у италийских языков, они делятся на две ветви, которые имеют разные степени близости к германским и кельтским языкам. Поэтому, каждый при разных методиках получает разные варианты пристыковывания италийских то к кельтским, то к германским. По всей видимости верно всё же к кельтским, по крайней мере генетика поможет определить это. Но субклады R1a у кельтов и италийцев еще слабо исследованы.
2. Те же проблемы с армянским прошедшим значительную креолизацию с хуррито-урартскими и западно иранскими языками. Точно его отношение с греческим неизвестно, но они достаточно соотносятся, хотя это может быть все тот же греко-армяно-арийский языковой союз который был в северном Причерноморье между бабинской/КМК (прагреко-праармянской) и синташтинской (праиндоиранской) культурами.
3. Но совсем ничего нельзя сказать об албанском, это очень поздний латино-"бог знает какой" пиджин, неизвестно то ли с фракийским то ли с иллирийским то ли с неизвестной ветвью, его пристыковывают куда угодно поскольку ни доказать ни опровергнуть насчет него ничего невозможно. Субклады R1a у этих народов не исследованы совсем.
Больше всего лексических соответствий у албанцев с греческим и с германскими языками. Поскольку албанцы подвергались сильному влиянию греческого, то могут предполагать что германские соответствия есть исконные, а греческие позднее. Но это все волюнтаризм, зависящий от шума той или иной методики. Поскольку понятно что албанский является очень дальним для них родственником, он гораздо ближе к фракийскому и иллирийскому которые неизвестны совсем и для них ничего нельзя вычислить. Албанский либо является диалектом дако-фракийского либо его близким родственником, поскольку албанцы ранее точно обитали восточнее современного ареала, а иллирийские соответствия можно рассматривать как субстрат. Для этих двух языков все равно неизвестно их отношение к греческому и к германским, а следовательно и для албанского тоже. Без знания степени близости иллирийского и фракийского к греческому и к германскому нельзя правильно вычислить степень близости к последним албанского. Так что оба дерева относительно албанского столь же правильны столь и не правильны.
Литература:
Чекман В. Н. Древнейшая балто-славо-индоиранская изоглосса (*si-k > *š). // Балто-славянские исследования. 1980. - М.: Наука, 1981. - С. 27-37.