Netgraph для пользователя: некоторые типы узлов
Как известно, инженер не должен помнить наизусть кучу формул, констант, свойств материалов, ключей командной строки и прочей информации: он должен помнить общие принципы, и уметь пользоваться справочниками, в которых и можно посмотреть нужное. А также уметь эту справочную информацию найти (знать, в какие справочники смотреть). Общие принципы netgraph были описаны в предыдущем посте, справочниками служат man-страницы и исходные тексты. Остается рассказать, какие узлы netgraph существуют (куда смотреть), и что они умеют - обзор того, что система умеет, какие задачи можно решать, что же именно можно комбинировать друг с другом.
Конечно, уделить внимание всем типам узлов не получится (ведь всего их уже более 60!), но хотя бы по некоторым будет иногда и такая информация, которой нет непосредственно в справочнике. Кроме того, этот пост можно рассматривать как приложение к предыдущему (ограничения на объем поста ЖЖ не позволяют даже поставить ссылку там сюда), для понимания материала необходимо его прочитать. Возможно, здесь будут и другие дополнения к нему.
Итак, узлы можно условно разделить на внутренние и пограничные - в том смысле, что одни общаются только с непосредственными соседями в netgraph, другие же служат для обмена пакетами с сущностями за пределами фреймворка. Ведь какой был бы в подсистеме смысл, если данным в неё никак не попасть? С этих узлов и начнем.
"Пограничные" узлы
Для узлов, осуществляющих связь netgraph с сущностями за его пределами, в целом характерно существовать постоянно, уничтожаясь только по явному NGM_SHUTDOWN (а некоторые игнорируют даже и его), но не при отключении всех хуков. Это естественно, ведь они могут соответствовать, скажем, устройствам, а те не зависят от netgraph.
ng_ether

Возвращаясь к аналогии с вокзалами в городе, трафик обычно прибывает на машину через сетевые интерфейсы Ethernet, и аналогом станции метро при вокзале служит тип узла ng_ether(4). При загрузке этого типа узла в ядро для каждого сетевого интерфейса создается узел типа ng_ether с таким же именем, что и у интерфейса, т.е. что показывает ifconfig, то будет и в ядре. Узел подцепляется в место стека (см. схему прохождения пакетов) между уровнем ether_demux()/ether_output_frame() и драйвером интерфейса, как показано на рисунке справа. В норме подгруженный узел себя никак не проявляет, и у ничего не подозревающего пользователя всё работает точно так же, как и работало ранее - узел обрабатывает ситуацию отсутствия хуков концептуально так же, как если бы они были замкнуты между собой. Вообще же он представляет своего рода разрыв на пути пакетов, в который можно вставить что-то свое.
Хуков у такого узла может быть три, с именами lower, upper и orphans. Полученные хуком lower (во времена AANG он назывался divert, с тех пор переименован) пакеты из netgraph будут отправлены сетевой картой в сеть, полученные же ей из сети пакеты будет отправлены через хук lower в netgraph. Хук orphans ведет себя точно так же, как lower в плане отправки пакетов из netgraph в сеть, но получены через него будут лишь те пакеты, что имеют неизвестный тип фрейма и всё равно были бы молча игнорированы машиной. Этим пользуется, например, mpd - так он получает пакеты PPPoE, не мешая обычной работе интерфейса.
Хук upper ведет к следующему уровню стека - полученное им из netgraph будет передано в ether_demux(), а в netgraph через этот хук отправляется то, что машина отправила бы в сеть по обычному пути после ip_output(). Здесь, правда, есть одна несимметричность, во взаимодействии с ipfw layer2 (sysctl net.link.ether.ipfw=1): на входном пути ipfw вызывается после ng_ether (уже прошло через хук upper наверх), на выходном же пути ng_ether обрабывается до ipfw (после прохождения lower). Иными словами, ipfw layer2 находится по разные стороны от ng_ether в зависимости от пути; ни одному пакету, покидающему netgraph, не удастся избежать ipfw (если тот включен).
Из того, что подключенные хуки представляют собой как бы разрыв на пути пакетов, следует, что нужно не забывать передавать пакеты между lower и upper - иначе нормальная работа сети на этом интерфейсе прекратится (например, если подключить только один из хуков). Что особенно актуально, если Вы делаете такую операцию по ssh через этот же самый интерфейс.
Осталось добавить, что узел существует в ядре постоянно, по ngctl shutdown он просто отключит хуки, promisc, включит заново подмену MAC-адреса на основной, но не исчезнет. Еще можно отметить проблему переименования интерфейсов: ifconfig, как известно, позволяет дать сетевой карте иное имя, но вот соответствующего узла ng_ether это автоматически не коснется.
ng_socket и ng_ksocket



Как уже говорилось в предыдущем посте, никаких специальных функций для управления netgraph не предусмотрено, всё выполняется в едином стиле средствами самого фреймворка. Поэтому управление производится через узел типа ng_socket - каждая программа, желающая взаимодействовать с netgraph, может создать один или несколько таких узлов (обычно для удобства администратора им присваивается имя, в котором указан PID соответствующего процесса).
В то же время существует тип узла ng_ksocket, который позволяет открыть из netgraph обычный сокет - например, чтобы установить TCP-соединение. При этом ng_ksocket обычно описывается как "противоположность ng_socket", что может быть непонятным для неопытного пользователя: в чем противоположность, и почему узел для создания сокета не называется просто ng_socket, где логика?..
Логика авторов netgraph, вместе с пояснением схемы работы узлов, становится понятнее из рисунков справа. Обычно сокет создается пользовательским процессом, при этом в системном вызове socket() ядру указывается, какого семейства протоколов (address family) должен быть сокет, например, AF_INET для IPv4, PF_INET6 для IPv6 или PF_LOCAL для Unix-сокетов (примечание: префиксы AF_ и PF_ означают одно и то же, по историческим причинам). Для netgraph был определен свой тип, PF_NETGRAPH, и вот, когда приложение создает сокет такого типа, в глубинах ядра для его поддержки вместо структур TCP/IP создается узел типа ng_socket.
В случае ng_ksocket же получается, что узел netgraph управляет сокетом вместо пользовательского процесса, а сравнительно с ng_socket - узел находится в противоположном положении относительно обобщенного кода сокетов, по другую его сторону. Обычный сокет считается как бы объектом userland-процесса, а в случае ng_ksocket он получается засунут в ядро. Вот такая неочевидная логика была у авторов.
Тип ng_socket представляет больший интерес для программистов, чем для пользователей, ведь для последних интерфейс доступен через ngctl и nghook. Здесь стоит рассмотреть разве что управление ресурсами: во-первых, на каждый узел создается не один, а два сокета - один для управляющих сообщений, другой для данных (если у Вас процесс типа mpd, который создает тысячи узлов, это может быть актуально при настройке лимитов). Во-вторых оба сокета datagram'ные, то есть пакет принимается целиком за раз, а не по кусочкам - и может потребоваться покрутить в sysctl лимиты net.graph.recvspace и net.graph.maxdgram. Может быть актуально, например, в случае очень большого числа узлов - ngctl list просто запрашивает список у своего собственного узла, и, если список большой, то он может в лимит и не влезть. Хотя другие сообщения, типа показа конкретного узла по имени, естественно, будут продолжать работать.
А вот ng_ksocket для пользователя куда интереснее, правда, требует некоторых знаний о программировании сокетов в сетевых приложениях. Узел поддерживает единственный хук, соответственно, он появляется при создании (mkpeer) узла, и потому задает тип сокета. Например, inet/dgram/udp для UDP. Приятности есть и в управляющих сообщениях: узел реализует свои собственные типы ng_parse(), поэтому вместо обычных структур, с шестнадцатеричными цифрами в квадратных и фигурных скобочках, можно писать адреса типа inet/192.168.1.1:1234 (не для всех типов протоколов, правда, но и то хорошо).
Набор управляющих сообщений напоминает о соответствующих системных вызовах для сокетов, в их неблокирующем варианте. Правда, нет аналога read() и select() - узел сразу отправляет данные в хук по мере их прихода, а на NGM_KSOCKET_ACCEPT просто запоминает, кому отправить ответ позже, если пришло соединение. Вообще работа с новыми принятыми соединениями сделана клонированием нового узла, ID которого сообщается в ответе на accept, и этот новый узел принимает хук с любым именем. Пример такой работы с TCP можно посмотреть в предыдущем посте.
Более типично, конечно, применение ng_ksocket для UDP, во всем известном сочетании с ng_netflow. В этих примерах, как можно заметить, для UDP применяется connect, но для UDP он имеет смысл лишь в качестве выставления адреса по умолчанию, куда отправлять пакеты. Можно этого не делать, а навешивать на каждый пакет mbuf tag с адресом назначения. То же самое, кстати, делает и сам узел, когда отправляет в netgraph пришедшие из сокета данные (в тег записывается ID узла и адрес отправителя).
Остается упомянуть только о баге (появившемся после потери атомарности соединения хуков в netgraph), в результате которого ng_ksocket будет терять данные, пришедшие в accept'нутое соединение, до тех пор, пока не будет подсоединен хук. Его сложно исправить, но очень легко обойти: достаточно в ngctl connect поменять местами адреса, делая хук не к клонированной ноде, а от неё. Тогда накопленные в буфере сокета данные будут корректно отданы в хук. Этот баг, впрочем, используется в примере из предыдущего поста - соединение специально делается так, чтобы данные, которые прислал клиент (HTTP-запрос), были потеряны (в этой задаче они не нужны).
ng_iface и ng_eiface
Этот узел реализует всем известный по mpd интерфейс ng*, который видно в ifconfig. Поддерживаемые хуки - inet для IPv4, inet6 для IPv6, ipx и т.д. Конечно, узел должен быть к чему-то подключен, что будет обрабатывать пакеты и присылать свои. Как правило, это делает для Вас mpd, но можно собрать и свою схему.
Вообще, в /usr/share/examples/netgraph/ лежит ряд скриптов-примеров, вот один из них, udp.tunnel, показывает, как можно сделать простой туннель на ng_iface и ng_ksocket.
Узел же ng_eiface имитирует собой уже не просто интерфейс, а Ethernet-интерфейс, и потому имеет только один хук ether (соответственно, по нему ходят уже не raw IP-пакеты, как у ng_iface, а с Ethernet-заголовком). Создаваемые интерфейсы имеют имена ngeth0, ngeth1 и т.д. Понадобиться такой узел может, например, для примера в файле virtual.lan - виртуальная сеть. Никто не мешает экспериментировать с ng_ksocket для L2-проброса и бриджинга удаленных сетей, и т.д.
ng_device
Представляет собой устройство с именем /dev/ngd0, /dev/ngd1 и т.д. для каждого следующего узла. Конвертирует чтение/запись в устройство в пакеты в netgraph. Поддерживает только один хук с любым именем, и уничтожается при его отсоединении (поскольку не соответствует реальному физическому устройству, держать этот узел постоянным смысла нет).
ng_ip_input
Поддерживает любое количество хуков, ничего не отправляет, всё получаемое ставит во входную очередь ip_input() (как если бы пакет был получен с какого-то физического интерфейса, и уже декапсулирован из L2). В основном применим для экспериментов.
ng_ipfw
Существует только в одном единственном экземпляре и всегда имеет имя ipfw. Имена хуков должны быть только цифровыми - они используются для определения, куда отправить пакет: в действии ipfw netgraph 324 пакет будет отправлен в хук с именем 324. При отправке в netgraph пакет снабжается mbuf-тегом, по аналогии с divert-сокетом - служит для определения, с какого правила продолжить обработку пакета в ipfw. Поскольку определение происходит по тегу, пакет можно вернуть в любой хук, не только в тот, из которого он вышел. Пакет без тега молча отбрасывается. Поскольку тег вешается только для действия ipfw netgraph, а для ngtee этого не делается (из соображений производительности), вернуть обратно пакеты после ngtee, увы, не получится.
ng_gif
Служит аналогом ng_ether для туннельных интерфейсов gif(4). Аналогия, однако, неполная: хука upper не существует, а пакеты с хука lower нельзя использовать напрямую. Вместо этого его нужно подключать к узлу ng_gif_demux, который уже инкапсулирует/декапсулирует пакеты в хуки с именами inet, inet6 и т.д. - как Вы уже догадались, они предназначены для подключения к ng_iface.
ng_fec
Строго говоря, это не пограничный узел, потому что совершенно не использует хуки (хотя принимает любые). Он используется лишь для управления поддержкой Ethernet-транков Cisco Fast EtherChannel на системных Ethernet-интерфейсах (добавляются и удаляются соответствующими сообщениями).
"Внутренние" узлы
Внутренними я обозвал их в рамках сей статьи потому, что они не связаны с сущностями вне netgraph, способны только на обмен пакетами и сообщениями внутри фреймворка. Однако назначение у них при этом может быть самое разное - от поддержки роутинга пакетов внутри самого netgraph до, например, реализации различных протоколов и прочих полезных вещей, ради которых, в основном, netgraph и создавался. Все эти узлы, как правило, делают себе харакири shutdown, когда отсоединен последний хук.
Начнем с узлов, предназначенных для коммутации/поддержания схем самого netgraph.
ng_hole и ng_echo
Принимают хуки с любыми именами, ng_hole молча игнорирует все пакеты и управляющие сообщения (аналог /dev/null), а ng_echo просто отправляет каждый пришедший в хук пакет обратно (и управляющие сообщения - их отправителю). Предназначены, понятное дело, прежде всего для тестирования и отладки, или как временные узлы во время создания сложных схем: если к узлу ngctl создать echo/hole, а следующий узел прицепить уже к нему, а не напрямую, то при выходе из ngctl эти узлы останутся существовать (ср. пример в предыдущем посте - прицепленный напрямую одним хуком слушающий ksocket исчез бы при выходе из ngctl, который держится запущенным постоянно). Иногда, впрочем, может встретиться такой узел/конфигурация, что и в продакшене с этими узлами построить схему удобнее.
ng_split
Это аналог отбойника, когда автомобильная дорога с двусторонним движением превращается в две односторонние в развязке. Поддерживает три хука: "двусторонний" mixed и два односторонних in и out.
ng_tee
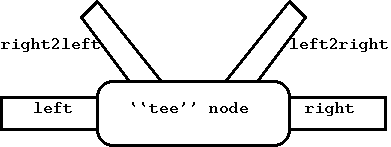
Этот узел, изображенный на честно спертой из AANG картинки справа, довольно полезен и не так мало умеет, несмотря на внешнюю простоту. Это аналог утилиты tee(1) для командной строки. Прежде всего он полезен для отладки - для "подглядывания", что там проходит по хукам. Между двумя узлами, обычно соединениямыми напрямую, сделаем ng_tee, хуки left и right. Пакеты, получаемые через left, отправляются в right, а копия каждого такого пакета шлется в left2right (если, конечно, он присоединен). То же самое происходит в обратном направлении (получаемые через right посылаются через left, и копия шлется через right2left).
Конечно, это бывает нужно далеко не только для отладки. Например, некоторые узлы - особенно это любят те, что считают трафик - после обработки уничтожают пакет. А он бывает еще нужен, тогда-то и можно отдать такому узлу копию.
На этом фичи ng_tee не заканчиваются. Пакет, полученный на left2right, будет отправлен в left (аналогично для right2left). Таким образом можно "впрыскивать" дополнительные пакеты в их нормальное течение между двумя узлами. А еще ng_tee при получении NGM_SHUTDOWN делает такую вещь: он самоустраняется из разрыва, соединяя хуки узлов справа и слева напрямую между собой. Это единственный узел в базовой системе, которые такое умеет (если такое требуется в своем узле, то делается вызовом ng_bypass()).
Оба этих трюка были использованы в примере HTTP-прокси: сначала надо отдать клиенту http-ответ, а потом переключить его на отдачу данных, но отсоединение хука убило бы узел ksocket. "Самовыкусывание" же узла позже (ведь записать ответ надо только один раз) еще и чуть-чуть поднимает производительность - меньше звеньев в цепочке.
ng_hub
Если ng_tee делает из одного пакета всего лишь две копии, то ng_hub поддерживает любое количество хуков с любыми именами. Принцип действия похож на Ethernet-хаб: пакет, полученный на одном из хуков, копирует во все остальные (кроме того, на котором был получен).
ng_one2many
Более интересный разветвитель, чем ng_hub. Имеет один хук с именем one и много хуков с именами many0, many1 и т.д. (в настоящее время не более 64). Пакеты, получаемые на хуках many*, отправляются в one. Пакеты же, получаемые на one, в зависимости от настройки узла либо копируются во все many* сразу, либо (в режиме NG_ONE2MANY_XMIT_ROUNDROBIN) отправляются в один случайный из них. Узел имеет некоторую поддержку определения "дохлых" линков - либо вручную, либо по присылаемым сообщениям от тех узлов, которые это умеют. Например, ng_ether умеет, так что узел пригоден для объединения нескольких интерфейсов в транк.
ng_bridge
Название говорит само за себя: это мост, или, другими словами, Ethernet-свитч (в настоящее время 32-портовый). Поддерживает хуки с именами link0, link1 и т.д. Имеет внутри себя таблицу соответствия MAC-адресов хукам, прям как настоящий свитч, и даже умеет детектировать петли. Поддержки ipfw layer2, правда, еще пока не имеет, автор начал и не закончил. В файле ether.bridge содержится пример настройки (несколько интерфейсов, объединяемых в мост).
ng_etf
Предполагает, что имеет дело с Ethernet-пакетами, и фильтрует их по полю Ethernet-типа в первых 14 байтах данных (считает, что там заголовок). Хук downstream подключается, например, к lower у ng_ether, хук nomatch рассматривается как хук по умолчанию для тех типов, которые не настроены в конфигурации этого узла (наиболее логично отправить их в upper на ng_ether). Хук с любым другим именем может быть использован для фильтрации конкретного протокола (причем узел еще входящие пакеты на таком хуке проверит, соответствуют ли фильтру, если нет, то прибьет). Сами пакеты при этом не изменяются, просто роутятся в нужный хук. Например, можно представить себе такие хуки для соответствующих протоколов:
ngctl 'msg etf: setfilter { matchhook="mpls" ethertype=0x8847 }'
ngctl 'msg etf: setfilter { matchhook="vlan" ethertype=0x8100 }'
Естественно, кто-то эти пакеты должен с той стороны принимать... для приведенного в примере хука vlan это может быть, например, следующий узел.
ng_vlan
Реализует тегирование/демультиплексирование IEEE 802.1Q. Имеет точно такие же имена хуков, как и ng_etf, тоже конфигурируется сообщениями на соответствие номеров тегов VLAN и имен хуков. Только, в отличие от ng_etf, конечно, уже изменяет проходящие пакеты: снимает или навешивает тег. Кроме хука nomatch, через который пакеты ходят немодифицированными - если они не имеют тега (имеют Ethernet-тип не 0x8100). Следует отметить, что ng_vlan - единственный способ на FreeBSD сделать VLAN QinQ. Делается, понятно, вполне естественным и логичным образом, просто повторением узлов несколько раз в цепочке,
ng_ppp и все-все-все
Здесь есть ng_l2tp, ng_pppoe, ng_pptpgre и другие узлы, которые довольно сложно конфигурировать, потому что протоколы, которые они реализуют - тоже сложные. Но вручную и не нужно - этим занимается mpd. Многие из этих узлов предназначены для взаимодействия друг с другом - mpd собирает их в схему в зависимости от указанных опций, и приспособить их для чего-то еще может быть сложно. Но не все: например, ng_pppoe может быть использован не mpd, а системным демоном pppoed(8). Для компрессии своих "ручных" туннелей можно попытаться использовать ng_vjc и ng_mppc, если обеспечить им сброс таблицы при потерях пакетов (или линк без потерь). И т.д.
ng_tcpmss
Используется для правки MSS в TCP SYN-пакетах. Все, кто сталкивался с "непролезанием" больших пакетов на ADSL и т.п. знают, что это и зачем - потому что в Интернете слишком много криворуких администраторов, запрещающих в своих файрволах весь ICMP (они думают, что это только пинги, хехе). Узел принимает любое число хуков, здесь из интересного можно отметить разве что еще не встречавшийся среди описанных выше узлов принцип явного роутинга пакетов между хуками. Хуков может быть любое количество, и в управляющих сообщениях явно указывается - полученное на хуке с именем таким-то отправлять в хук такой-то (поправив заодно MSS, если нужно).
ng_bpf
В нектором смысле суть аналог tcpdump, и потому довольно интересен для администратора, поскольку позволяет фильтровать по любым данным пакета, и заголовкам, и телу. Здесь тоже может быть любое количество хуков с любыми именами, и конфигурируется каждый из них отдельно: с ним связывается bpf-программа, и имена двух хуков. Каждый пришедший на хук пакет прогоняется через программу, если вердикт был положительный (match), пакет отправляется в один из этих хуков, если нет, в другой. Подробно этот узел рассмотрен в моем более раннем посте про tcpdump и ассемблер BPF, вместе с необходимой другой теоретической информацией, вроде понятия DLT (которое используется и в некоторых других узлах). Некоторые примеры применения можно найти и в man ng_tag (пустые выражения для приема всех пакетов, сопряжение с ipfw), хотя ими, конечно, этот узел не ограничивается (mpd применяет его уже более 10 лет, скажем).
ng_netflow и ng_ipacct
Ну, многочисленные примеры про подсчет трафика с помощью ng_netflow уже, наверное, всем оскомину набили. Трафик принимается на хуках с именами iface0, iface1 и т.д. Раньше (в старых версиях) пакеты с трафиком просто уничтожались после подсчета, сейчас вместо копирования через ng_tee еще можно подключить хуки с именами out0, out1 и т.д. На хуке с именем export выдаются datagram'мы Cisco NetFlow v5 - на этом работа узла заканчивается. Вот она, модульность netgraph - подключить хук можно к чему угодно, скажем, к nghook, который будет в файл складировать. Хотя обычно, конечно, подключают к ng_ksocket, который оборачивает в UDP и шлет в какой-нибудь коллектор. Но никто не мешает включит перед ним, допустим, ng_tee, сделать два ng_ksocket и слать сразу на 2 коллектора. Или сделать что-нибудь еще, если UDP-пакеты теряются. В общем, полет фантазии не ограничен. Единственно, что по этому узлу следует упомянуть - используется понятие DLT (подробно описанное в теме BPF), потому что узлу нужно знать, где именно начинаются заголовки пакета. В некоторых случаях узлу следует указать также индекс интерфейса (эти индексы используются, например, и в SNMP).
В портах доступен также узел ng_ipacct, реализующий вывод Cisco IP Accounting в текстовом виде. Для управления им используются стартовые rcNG-скрипты и утилита ipacctctl - пользователю в данном случае практически не нужно заморачиваться с netgraph.
ng_tag
Этот узел был смоделирован по образу и подобию ng_bpf, принципы ifMatch и ifNotMatch-хуков те же самые, только здесь фильтрация осуществляется не по самому пакету, а по метаинформации, с ним связанной - тегам mbuf_tags(9). Нет смысла пересказывать здесь врезку из предыщего поста и информацию из манов про то, что такое теги (для тех мерзких лентяев, кто к сему моменту еще не читал предыдущий пост, сообщаю, что это не vlan-теги, а теперь марш читать). А вот чего нигде нет, так это описание, что же делать в случае необходимости тега с ненулевой длиной данных - секция BUGS сообщает, что там нужно писать байты так, как они непортабельно представлены в памяти конкретной машины, и что, может быть, надо б сделать программу для управления (типа как у ng_ipacct своя есть, или mpd), но никто такую не написал.
Проблема здесь в том, что на современных машинах используется выравнивание элементов структур по кратным размеру в памяти - т.е. могут появляться дополнительные байты padding, сверх просто суммы sizeof всех элементов, и т.д. К сожалению, здесь слишком мало места, чтобы описать всё подробно, поэтому приведу способ очень кратко. Нижеприведенное тестировалось на 7.2R/i386, никаких дополнительных байтов в этих конкретных случаях не оказалось, но это просто повезло (бывают они, ох как бывают). Итак, задача номер 1: допустим, нужно в ng_ksocket передавать тег с адресом назначения пакета. Программа выведет на stdout структуру с тегом, первые 16 байт на i386 - это сам тег, его пропустить, остальное - пойдет в tag_data.
#include
#include
#define MSIZE 256
#include
#include
#include
#include
#include
#include
#define _KERNEL
#include
int main(int argc, char* argv[])
{
struct sa_tag stag;
struct sockaddr_in *sa_sin;
bzero(&stag, sizeof(struct sa_tag));
sa_sin = &stag.sa;
sa_sin->sin_family = AF_INET;
sa_sin->sin_len = sizeof(struct sockaddr_in);
inet_aton("10.11.12.13", &sa_sin->sin_addr);
sa_sin->sin_port = htons(8080);
stag.id = 0x01020304;
stag.tag.m_tag_cookie = NGM_KSOCKET_COOKIE;
stag.tag.m_tag_id = NG_KSOCKET_TAG_SOCKADDR;
stag.tag.m_tag_len = sizeof(ng_ID_t) + stag.sa.sa_len;
write(1, &stag, sizeof(struct sa_tag));
return (0);
}
$ ./mtag_align | hd
00000000 00 00 00 00 01 00 14 00 8d 9f 30 38 00 00 00 00 |..........08....|
00000010 04 03 02 01 10 02 1f 90 0a 0b 0c 0d 00 00 00 00 |................|
00000020 00 00 00 00 |....|
00000024
Другая задача: протегировать пакет так, будто бы он пришел из divert-сокета, и надо, чтобы он продолжил с определенного правила ipfw. Релевантные фрагменты кода:
#define PACKET_TAG_DIVERT 17 /* divert info */
#define MTAG_ABI_COMPAT 0 /* compatibility ABI */
#define IP_FW_DIVERT_LOOPBACK_FLAG 0x00080000
struct divert_tag {
u_int32_t info; /* port & flags */
u_int16_t cookie; /* ipfw rule number */
};
...
dtag->cookie = 6000; /* ipfw rule num */
dtag->info = IP_FW_DIVERT_LOOPBACK_FLAG | 2048; /* divert port and flag */
В итоге получаем такой скрипт, тестируя вручную сделанным ICMP-пакетом:
# ngctl
+ mkpeer . hub tst tst
+ name tst divhub
+ mkpeer divhub: tag mark in
+ name divhub:mark xtag
+ mkpeer xtag: ip_input out divert2048
+ name xtag:out ip_input
+ msg xtag: sethookin { thisHook="in" ifMatch="out" ifNotMatch="out" }
+ msg xtag: sethookout { thisHook="out" tag_cookie=0 tag_id=17 tag_len=8 tag_data=[0x00 0x08 0x08 0x00 0x70 0x17] }
#
# ipfw show 50 6001
00050 0 0 count ip from 192.168.0.0/16 to any
06001 0 0 count ip from 192.168.0.0/16 to any
06001 0 0 count ip from 192.168.0.0/16 to any in
06001 0 0 count ip from 192.168.0.0/16 to any in diverted
# perl -pe 's/(..)[ \t\n]*/chr(hex($1))/ge' <
45 00 00 54 cb 13 00 00 40 01 b9 87 c0 a8 2b 65
0a 00 00 01 08 00 f8 d0 c9 76 00 00 45 37 01 73
00 01 04 0a 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13
14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23
24 25 26 27 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33
34 35 36 37
EOF
# ipfw show 50 6001
00050 1 84 count ip from 192.168.0.0/16 to any
00050 0 0 count ip from 192.168.0.0/16 to any in
00050 1 84 count ip from 192.168.0.0/16 to any out
06001 1 84 count ip from 192.168.0.0/16 to any
06001 1 84 count ip from 192.168.0.0/16 to any in
06001 1 84 count ip from 192.168.0.0/16 to any in diverted
Вполне работает. Опытным путем выяснено, однако, что, в tag_len нужно писать значение, кратное 4, хотя нужны нам всего 6 байт (иначе возвращает EINVAL). Что это за артефакт ng_parse() такой, еще не разбирался.
ng_nat
Этот узел в качестве примера был рассмотрен в предыдущем посте. Он практически дублирует интерфейс программиста к библиотеке libalias(3), а потому подробности нужно смотреть в соответствующем мане, а также в man natd, который тоже сделан на основе libalias (принципы те же самые).
ng_patch
Узел для модификации содержимого проходящих через него пакетов. Подробно описан в man-странице и посте http://nuclight.livejournal.com/126002.html
ng_car
Простой шейпер трафика, реализующий Commited Access Rate (RFC 2697, RFC 2698), CIR (Committed Information Rate), RED и другие слова, знакомые заводчикам Cisco. Поэтому, кроме man-страницы самого узла, следует изучить и соответствующую документацию по теме.
ng_pipe
Это шейпер, реализующий тот же механизм, что в dummynet - ipfw pipe. К сожалению, документации по узлу в настоящее время нет (придется читать исходники).
А дальше?
Да, выше описаны не все узлы, что есть в системе. Не рассмотрен, например, ряд протоколов, скажем, узлы реализаций ATM и Bluetooth. Но я выражаю надежду, что с популяризацией netgraph количество узлов увеличится, тем более, что узел netgraph написать проще, чем "обыкновенный" модуль ядра. Здесь осталось только напомнить разработчикам следовать идеологии netgraph - каждый узел изолирован, делает свою, узко очерченную часть работы, и может быть скомбинирован неизвестно заранее с чем. Другими словами, делайте не сразу сходу решение вашей конкретной задачи, а подумайте, как её можно обобщить, для чего еще приспособить (если, конечно, хотите, чтобы узел был принят в базовую систему FreeBSD). Так, ng_tag вместо тегов одного лишь ipfw может решать и другие задачи, ng_patch вместо правки одного лишь поля ToS/DSCP умеет любые арифметические операции с любым местом пакета, и т.д., при том, что эти изменения не потребовали много кода.
Что ж, в AANG есть некоторые интересные идеи для будущего, а на сегодня пока всё. Удачи.
Конечно, уделить внимание всем типам узлов не получится (ведь всего их уже более 60!), но хотя бы по некоторым будет иногда и такая информация, которой нет непосредственно в справочнике. Кроме того, этот пост можно рассматривать как приложение к предыдущему (ограничения на объем поста ЖЖ не позволяют даже поставить ссылку там сюда), для понимания материала необходимо его прочитать. Возможно, здесь будут и другие дополнения к нему.
Итак, узлы можно условно разделить на внутренние и пограничные - в том смысле, что одни общаются только с непосредственными соседями в netgraph, другие же служат для обмена пакетами с сущностями за пределами фреймворка. Ведь какой был бы в подсистеме смысл, если данным в неё никак не попасть? С этих узлов и начнем.
"Пограничные" узлы
Для узлов, осуществляющих связь netgraph с сущностями за его пределами, в целом характерно существовать постоянно, уничтожаясь только по явному NGM_SHUTDOWN (а некоторые игнорируют даже и его), но не при отключении всех хуков. Это естественно, ведь они могут соответствовать, скажем, устройствам, а те не зависят от netgraph.
ng_ether
Возвращаясь к аналогии с вокзалами в городе, трафик обычно прибывает на машину через сетевые интерфейсы Ethernet, и аналогом станции метро при вокзале служит тип узла ng_ether(4). При загрузке этого типа узла в ядро для каждого сетевого интерфейса создается узел типа ng_ether с таким же именем, что и у интерфейса, т.е. что показывает ifconfig, то будет и в ядре. Узел подцепляется в место стека (см. схему прохождения пакетов) между уровнем ether_demux()/ether_output_frame() и драйвером интерфейса, как показано на рисунке справа. В норме подгруженный узел себя никак не проявляет, и у ничего не подозревающего пользователя всё работает точно так же, как и работало ранее - узел обрабатывает ситуацию отсутствия хуков концептуально так же, как если бы они были замкнуты между собой. Вообще же он представляет своего рода разрыв на пути пакетов, в который можно вставить что-то свое.
Хуков у такого узла может быть три, с именами lower, upper и orphans. Полученные хуком lower (во времена AANG он назывался divert, с тех пор переименован) пакеты из netgraph будут отправлены сетевой картой в сеть, полученные же ей из сети пакеты будет отправлены через хук lower в netgraph. Хук orphans ведет себя точно так же, как lower в плане отправки пакетов из netgraph в сеть, но получены через него будут лишь те пакеты, что имеют неизвестный тип фрейма и всё равно были бы молча игнорированы машиной. Этим пользуется, например, mpd - так он получает пакеты PPPoE, не мешая обычной работе интерфейса.
Хук upper ведет к следующему уровню стека - полученное им из netgraph будет передано в ether_demux(), а в netgraph через этот хук отправляется то, что машина отправила бы в сеть по обычному пути после ip_output(). Здесь, правда, есть одна несимметричность, во взаимодействии с ipfw layer2 (sysctl net.link.ether.ipfw=1): на входном пути ipfw вызывается после ng_ether (уже прошло через хук upper наверх), на выходном же пути ng_ether обрабывается до ipfw (после прохождения lower). Иными словами, ipfw layer2 находится по разные стороны от ng_ether в зависимости от пути; ни одному пакету, покидающему netgraph, не удастся избежать ipfw (если тот включен).
Из того, что подключенные хуки представляют собой как бы разрыв на пути пакетов, следует, что нужно не забывать передавать пакеты между lower и upper - иначе нормальная работа сети на этом интерфейсе прекратится (например, если подключить только один из хуков). Что особенно актуально, если Вы делаете такую операцию по ssh через этот же самый интерфейс.
Осталось добавить, что узел существует в ядре постоянно, по ngctl shutdown он просто отключит хуки, promisc, включит заново подмену MAC-адреса на основной, но не исчезнет. Еще можно отметить проблему переименования интерфейсов: ifconfig, как известно, позволяет дать сетевой карте иное имя, но вот соответствующего узла ng_ether это автоматически не коснется.
ng_socket и ng_ksocket
Как уже говорилось в предыдущем посте, никаких специальных функций для управления netgraph не предусмотрено, всё выполняется в едином стиле средствами самого фреймворка. Поэтому управление производится через узел типа ng_socket - каждая программа, желающая взаимодействовать с netgraph, может создать один или несколько таких узлов (обычно для удобства администратора им присваивается имя, в котором указан PID соответствующего процесса).
В то же время существует тип узла ng_ksocket, который позволяет открыть из netgraph обычный сокет - например, чтобы установить TCP-соединение. При этом ng_ksocket обычно описывается как "противоположность ng_socket", что может быть непонятным для неопытного пользователя: в чем противоположность, и почему узел для создания сокета не называется просто ng_socket, где логика?..
Логика авторов netgraph, вместе с пояснением схемы работы узлов, становится понятнее из рисунков справа. Обычно сокет создается пользовательским процессом, при этом в системном вызове socket() ядру указывается, какого семейства протоколов (address family) должен быть сокет, например, AF_INET для IPv4, PF_INET6 для IPv6 или PF_LOCAL для Unix-сокетов (примечание: префиксы AF_ и PF_ означают одно и то же, по историческим причинам). Для netgraph был определен свой тип, PF_NETGRAPH, и вот, когда приложение создает сокет такого типа, в глубинах ядра для его поддержки вместо структур TCP/IP создается узел типа ng_socket.
В случае ng_ksocket же получается, что узел netgraph управляет сокетом вместо пользовательского процесса, а сравнительно с ng_socket - узел находится в противоположном положении относительно обобщенного кода сокетов, по другую его сторону. Обычный сокет считается как бы объектом userland-процесса, а в случае ng_ksocket он получается засунут в ядро. Вот такая неочевидная логика была у авторов.
Тип ng_socket представляет больший интерес для программистов, чем для пользователей, ведь для последних интерфейс доступен через ngctl и nghook. Здесь стоит рассмотреть разве что управление ресурсами: во-первых, на каждый узел создается не один, а два сокета - один для управляющих сообщений, другой для данных (если у Вас процесс типа mpd, который создает тысячи узлов, это может быть актуально при настройке лимитов). Во-вторых оба сокета datagram'ные, то есть пакет принимается целиком за раз, а не по кусочкам - и может потребоваться покрутить в sysctl лимиты net.graph.recvspace и net.graph.maxdgram. Может быть актуально, например, в случае очень большого числа узлов - ngctl list просто запрашивает список у своего собственного узла, и, если список большой, то он может в лимит и не влезть. Хотя другие сообщения, типа показа конкретного узла по имени, естественно, будут продолжать работать.
А вот ng_ksocket для пользователя куда интереснее, правда, требует некоторых знаний о программировании сокетов в сетевых приложениях. Узел поддерживает единственный хук, соответственно, он появляется при создании (mkpeer) узла, и потому задает тип сокета. Например, inet/dgram/udp для UDP. Приятности есть и в управляющих сообщениях: узел реализует свои собственные типы ng_parse(), поэтому вместо обычных структур, с шестнадцатеричными цифрами в квадратных и фигурных скобочках, можно писать адреса типа inet/192.168.1.1:1234 (не для всех типов протоколов, правда, но и то хорошо).
Набор управляющих сообщений напоминает о соответствующих системных вызовах для сокетов, в их неблокирующем варианте. Правда, нет аналога read() и select() - узел сразу отправляет данные в хук по мере их прихода, а на NGM_KSOCKET_ACCEPT просто запоминает, кому отправить ответ позже, если пришло соединение. Вообще работа с новыми принятыми соединениями сделана клонированием нового узла, ID которого сообщается в ответе на accept, и этот новый узел принимает хук с любым именем. Пример такой работы с TCP можно посмотреть в предыдущем посте.
Более типично, конечно, применение ng_ksocket для UDP, во всем известном сочетании с ng_netflow. В этих примерах, как можно заметить, для UDP применяется connect, но для UDP он имеет смысл лишь в качестве выставления адреса по умолчанию, куда отправлять пакеты. Можно этого не делать, а навешивать на каждый пакет mbuf tag с адресом назначения. То же самое, кстати, делает и сам узел, когда отправляет в netgraph пришедшие из сокета данные (в тег записывается ID узла и адрес отправителя).
Остается упомянуть только о баге (появившемся после потери атомарности соединения хуков в netgraph), в результате которого ng_ksocket будет терять данные, пришедшие в accept'нутое соединение, до тех пор, пока не будет подсоединен хук. Его сложно исправить, но очень легко обойти: достаточно в ngctl connect поменять местами адреса, делая хук не к клонированной ноде, а от неё. Тогда накопленные в буфере сокета данные будут корректно отданы в хук. Этот баг, впрочем, используется в примере из предыдущего поста - соединение специально делается так, чтобы данные, которые прислал клиент (HTTP-запрос), были потеряны (в этой задаче они не нужны).
ng_iface и ng_eiface
Этот узел реализует всем известный по mpd интерфейс ng*, который видно в ifconfig. Поддерживаемые хуки - inet для IPv4, inet6 для IPv6, ipx и т.д. Конечно, узел должен быть к чему-то подключен, что будет обрабатывать пакеты и присылать свои. Как правило, это делает для Вас mpd, но можно собрать и свою схему.
Вообще, в /usr/share/examples/netgraph/ лежит ряд скриптов-примеров, вот один из них, udp.tunnel, показывает, как можно сделать простой туннель на ng_iface и ng_ksocket.
Узел же ng_eiface имитирует собой уже не просто интерфейс, а Ethernet-интерфейс, и потому имеет только один хук ether (соответственно, по нему ходят уже не raw IP-пакеты, как у ng_iface, а с Ethernet-заголовком). Создаваемые интерфейсы имеют имена ngeth0, ngeth1 и т.д. Понадобиться такой узел может, например, для примера в файле virtual.lan - виртуальная сеть. Никто не мешает экспериментировать с ng_ksocket для L2-проброса и бриджинга удаленных сетей, и т.д.
ng_device
Представляет собой устройство с именем /dev/ngd0, /dev/ngd1 и т.д. для каждого следующего узла. Конвертирует чтение/запись в устройство в пакеты в netgraph. Поддерживает только один хук с любым именем, и уничтожается при его отсоединении (поскольку не соответствует реальному физическому устройству, держать этот узел постоянным смысла нет).
ng_ip_input
Поддерживает любое количество хуков, ничего не отправляет, всё получаемое ставит во входную очередь ip_input() (как если бы пакет был получен с какого-то физического интерфейса, и уже декапсулирован из L2). В основном применим для экспериментов.
ng_ipfw
Существует только в одном единственном экземпляре и всегда имеет имя ipfw. Имена хуков должны быть только цифровыми - они используются для определения, куда отправить пакет: в действии ipfw netgraph 324 пакет будет отправлен в хук с именем 324. При отправке в netgraph пакет снабжается mbuf-тегом, по аналогии с divert-сокетом - служит для определения, с какого правила продолжить обработку пакета в ipfw. Поскольку определение происходит по тегу, пакет можно вернуть в любой хук, не только в тот, из которого он вышел. Пакет без тега молча отбрасывается. Поскольку тег вешается только для действия ipfw netgraph, а для ngtee этого не делается (из соображений производительности), вернуть обратно пакеты после ngtee, увы, не получится.
ng_gif
Служит аналогом ng_ether для туннельных интерфейсов gif(4). Аналогия, однако, неполная: хука upper не существует, а пакеты с хука lower нельзя использовать напрямую. Вместо этого его нужно подключать к узлу ng_gif_demux, который уже инкапсулирует/декапсулирует пакеты в хуки с именами inet, inet6 и т.д. - как Вы уже догадались, они предназначены для подключения к ng_iface.
ng_fec
Строго говоря, это не пограничный узел, потому что совершенно не использует хуки (хотя принимает любые). Он используется лишь для управления поддержкой Ethernet-транков Cisco Fast EtherChannel на системных Ethernet-интерфейсах (добавляются и удаляются соответствующими сообщениями).
"Внутренние" узлы
Внутренними я обозвал их в рамках сей статьи потому, что они не связаны с сущностями вне netgraph, способны только на обмен пакетами и сообщениями внутри фреймворка. Однако назначение у них при этом может быть самое разное - от поддержки роутинга пакетов внутри самого netgraph до, например, реализации различных протоколов и прочих полезных вещей, ради которых, в основном, netgraph и создавался. Все эти узлы, как правило, делают себе харакири shutdown, когда отсоединен последний хук.
Начнем с узлов, предназначенных для коммутации/поддержания схем самого netgraph.
ng_hole и ng_echo
Принимают хуки с любыми именами, ng_hole молча игнорирует все пакеты и управляющие сообщения (аналог /dev/null), а ng_echo просто отправляет каждый пришедший в хук пакет обратно (и управляющие сообщения - их отправителю). Предназначены, понятное дело, прежде всего для тестирования и отладки, или как временные узлы во время создания сложных схем: если к узлу ngctl создать echo/hole, а следующий узел прицепить уже к нему, а не напрямую, то при выходе из ngctl эти узлы останутся существовать (ср. пример в предыдущем посте - прицепленный напрямую одним хуком слушающий ksocket исчез бы при выходе из ngctl, который держится запущенным постоянно). Иногда, впрочем, может встретиться такой узел/конфигурация, что и в продакшене с этими узлами построить схему удобнее.
ng_split
Это аналог отбойника, когда автомобильная дорога с двусторонним движением превращается в две односторонние в развязке. Поддерживает три хука: "двусторонний" mixed и два односторонних in и out.
- пакеты, полученные хуком in, отправляются в хук mixed
- пакеты, полученные хуком mixed, отправляются в хук out
- пакеты, полученные хуком out, пускаются под откос (одностороннее движение!)
ng_tee
Этот узел, изображенный на честно спертой из AANG картинки справа, довольно полезен и не так мало умеет, несмотря на внешнюю простоту. Это аналог утилиты tee(1) для командной строки. Прежде всего он полезен для отладки - для "подглядывания", что там проходит по хукам. Между двумя узлами, обычно соединениямыми напрямую, сделаем ng_tee, хуки left и right. Пакеты, получаемые через left, отправляются в right, а копия каждого такого пакета шлется в left2right (если, конечно, он присоединен). То же самое происходит в обратном направлении (получаемые через right посылаются через left, и копия шлется через right2left).
Конечно, это бывает нужно далеко не только для отладки. Например, некоторые узлы - особенно это любят те, что считают трафик - после обработки уничтожают пакет. А он бывает еще нужен, тогда-то и можно отдать такому узлу копию.
На этом фичи ng_tee не заканчиваются. Пакет, полученный на left2right, будет отправлен в left (аналогично для right2left). Таким образом можно "впрыскивать" дополнительные пакеты в их нормальное течение между двумя узлами. А еще ng_tee при получении NGM_SHUTDOWN делает такую вещь: он самоустраняется из разрыва, соединяя хуки узлов справа и слева напрямую между собой. Это единственный узел в базовой системе, которые такое умеет (если такое требуется в своем узле, то делается вызовом ng_bypass()).
Оба этих трюка были использованы в примере HTTP-прокси: сначала надо отдать клиенту http-ответ, а потом переключить его на отдачу данных, но отсоединение хука убило бы узел ksocket. "Самовыкусывание" же узла позже (ведь записать ответ надо только один раз) еще и чуть-чуть поднимает производительность - меньше звеньев в цепочке.
ng_hub
Если ng_tee делает из одного пакета всего лишь две копии, то ng_hub поддерживает любое количество хуков с любыми именами. Принцип действия похож на Ethernet-хаб: пакет, полученный на одном из хуков, копирует во все остальные (кроме того, на котором был получен).
ng_one2many
Более интересный разветвитель, чем ng_hub. Имеет один хук с именем one и много хуков с именами many0, many1 и т.д. (в настоящее время не более 64). Пакеты, получаемые на хуках many*, отправляются в one. Пакеты же, получаемые на one, в зависимости от настройки узла либо копируются во все many* сразу, либо (в режиме NG_ONE2MANY_XMIT_ROUNDROBIN) отправляются в один случайный из них. Узел имеет некоторую поддержку определения "дохлых" линков - либо вручную, либо по присылаемым сообщениям от тех узлов, которые это умеют. Например, ng_ether умеет, так что узел пригоден для объединения нескольких интерфейсов в транк.
ng_bridge
Название говорит само за себя: это мост, или, другими словами, Ethernet-свитч (в настоящее время 32-портовый). Поддерживает хуки с именами link0, link1 и т.д. Имеет внутри себя таблицу соответствия MAC-адресов хукам, прям как настоящий свитч, и даже умеет детектировать петли. Поддержки ipfw layer2, правда, еще пока не имеет, автор начал и не закончил. В файле ether.bridge содержится пример настройки (несколько интерфейсов, объединяемых в мост).
ng_etf
Предполагает, что имеет дело с Ethernet-пакетами, и фильтрует их по полю Ethernet-типа в первых 14 байтах данных (считает, что там заголовок). Хук downstream подключается, например, к lower у ng_ether, хук nomatch рассматривается как хук по умолчанию для тех типов, которые не настроены в конфигурации этого узла (наиболее логично отправить их в upper на ng_ether). Хук с любым другим именем может быть использован для фильтрации конкретного протокола (причем узел еще входящие пакеты на таком хуке проверит, соответствуют ли фильтру, если нет, то прибьет). Сами пакеты при этом не изменяются, просто роутятся в нужный хук. Например, можно представить себе такие хуки для соответствующих протоколов:
ngctl 'msg etf: setfilter { matchhook="mpls" ethertype=0x8847 }'
ngctl 'msg etf: setfilter { matchhook="vlan" ethertype=0x8100 }'
Естественно, кто-то эти пакеты должен с той стороны принимать... для приведенного в примере хука vlan это может быть, например, следующий узел.
ng_vlan
Реализует тегирование/демультиплексирование IEEE 802.1Q. Имеет точно такие же имена хуков, как и ng_etf, тоже конфигурируется сообщениями на соответствие номеров тегов VLAN и имен хуков. Только, в отличие от ng_etf, конечно, уже изменяет проходящие пакеты: снимает или навешивает тег. Кроме хука nomatch, через который пакеты ходят немодифицированными - если они не имеют тега (имеют Ethernet-тип не 0x8100). Следует отметить, что ng_vlan - единственный способ на FreeBSD сделать VLAN QinQ. Делается, понятно, вполне естественным и логичным образом, просто повторением узлов несколько раз в цепочке,
ng_ppp и все-все-все
Здесь есть ng_l2tp, ng_pppoe, ng_pptpgre и другие узлы, которые довольно сложно конфигурировать, потому что протоколы, которые они реализуют - тоже сложные. Но вручную и не нужно - этим занимается mpd. Многие из этих узлов предназначены для взаимодействия друг с другом - mpd собирает их в схему в зависимости от указанных опций, и приспособить их для чего-то еще может быть сложно. Но не все: например, ng_pppoe может быть использован не mpd, а системным демоном pppoed(8). Для компрессии своих "ручных" туннелей можно попытаться использовать ng_vjc и ng_mppc, если обеспечить им сброс таблицы при потерях пакетов (или линк без потерь). И т.д.
ng_tcpmss
Используется для правки MSS в TCP SYN-пакетах. Все, кто сталкивался с "непролезанием" больших пакетов на ADSL и т.п. знают, что это и зачем - потому что в Интернете слишком много криворуких администраторов, запрещающих в своих файрволах весь ICMP (они думают, что это только пинги, хехе). Узел принимает любое число хуков, здесь из интересного можно отметить разве что еще не встречавшийся среди описанных выше узлов принцип явного роутинга пакетов между хуками. Хуков может быть любое количество, и в управляющих сообщениях явно указывается - полученное на хуке с именем таким-то отправлять в хук такой-то (поправив заодно MSS, если нужно).
ng_bpf
В нектором смысле суть аналог tcpdump, и потому довольно интересен для администратора, поскольку позволяет фильтровать по любым данным пакета, и заголовкам, и телу. Здесь тоже может быть любое количество хуков с любыми именами, и конфигурируется каждый из них отдельно: с ним связывается bpf-программа, и имена двух хуков. Каждый пришедший на хук пакет прогоняется через программу, если вердикт был положительный (match), пакет отправляется в один из этих хуков, если нет, в другой. Подробно этот узел рассмотрен в моем более раннем посте про tcpdump и ассемблер BPF, вместе с необходимой другой теоретической информацией, вроде понятия DLT (которое используется и в некоторых других узлах). Некоторые примеры применения можно найти и в man ng_tag (пустые выражения для приема всех пакетов, сопряжение с ipfw), хотя ими, конечно, этот узел не ограничивается (mpd применяет его уже более 10 лет, скажем).
ng_netflow и ng_ipacct
Ну, многочисленные примеры про подсчет трафика с помощью ng_netflow уже, наверное, всем оскомину набили. Трафик принимается на хуках с именами iface0, iface1 и т.д. Раньше (в старых версиях) пакеты с трафиком просто уничтожались после подсчета, сейчас вместо копирования через ng_tee еще можно подключить хуки с именами out0, out1 и т.д. На хуке с именем export выдаются datagram'мы Cisco NetFlow v5 - на этом работа узла заканчивается. Вот она, модульность netgraph - подключить хук можно к чему угодно, скажем, к nghook, который будет в файл складировать. Хотя обычно, конечно, подключают к ng_ksocket, который оборачивает в UDP и шлет в какой-нибудь коллектор. Но никто не мешает включит перед ним, допустим, ng_tee, сделать два ng_ksocket и слать сразу на 2 коллектора. Или сделать что-нибудь еще, если UDP-пакеты теряются. В общем, полет фантазии не ограничен. Единственно, что по этому узлу следует упомянуть - используется понятие DLT (подробно описанное в теме BPF), потому что узлу нужно знать, где именно начинаются заголовки пакета. В некоторых случаях узлу следует указать также индекс интерфейса (эти индексы используются, например, и в SNMP).
В портах доступен также узел ng_ipacct, реализующий вывод Cisco IP Accounting в текстовом виде. Для управления им используются стартовые rcNG-скрипты и утилита ipacctctl - пользователю в данном случае практически не нужно заморачиваться с netgraph.
ng_tag
Этот узел был смоделирован по образу и подобию ng_bpf, принципы ifMatch и ifNotMatch-хуков те же самые, только здесь фильтрация осуществляется не по самому пакету, а по метаинформации, с ним связанной - тегам mbuf_tags(9). Нет смысла пересказывать здесь врезку из предыщего поста и информацию из манов про то, что такое теги (для тех мерзких лентяев, кто к сему моменту еще не читал предыдущий пост, сообщаю, что это не vlan-теги, а теперь марш читать). А вот чего нигде нет, так это описание, что же делать в случае необходимости тега с ненулевой длиной данных - секция BUGS сообщает, что там нужно писать байты так, как они непортабельно представлены в памяти конкретной машины, и что, может быть, надо б сделать программу для управления (типа как у ng_ipacct своя есть, или mpd), но никто такую не написал.
Проблема здесь в том, что на современных машинах используется выравнивание элементов структур по кратным размеру в памяти - т.е. могут появляться дополнительные байты padding, сверх просто суммы sizeof всех элементов, и т.д. К сожалению, здесь слишком мало места, чтобы описать всё подробно, поэтому приведу способ очень кратко. Нижеприведенное тестировалось на 7.2R/i386, никаких дополнительных байтов в этих конкретных случаях не оказалось, но это просто повезло (бывают они, ох как бывают). Итак, задача номер 1: допустим, нужно в ng_ksocket передавать тег с адресом назначения пакета. Программа выведет на stdout структуру с тегом, первые 16 байт на i386 - это сам тег, его пропустить, остальное - пойдет в tag_data.
#include
#include
#define MSIZE 256
#include
#include
#include
#include
#include
#include
#define _KERNEL
#include
int main(int argc, char* argv[])
{
struct sa_tag stag;
struct sockaddr_in *sa_sin;
bzero(&stag, sizeof(struct sa_tag));
sa_sin = &stag.sa;
sa_sin->sin_family = AF_INET;
sa_sin->sin_len = sizeof(struct sockaddr_in);
inet_aton("10.11.12.13", &sa_sin->sin_addr);
sa_sin->sin_port = htons(8080);
stag.id = 0x01020304;
stag.tag.m_tag_cookie = NGM_KSOCKET_COOKIE;
stag.tag.m_tag_id = NG_KSOCKET_TAG_SOCKADDR;
stag.tag.m_tag_len = sizeof(ng_ID_t) + stag.sa.sa_len;
write(1, &stag, sizeof(struct sa_tag));
return (0);
}
$ ./mtag_align | hd
00000000 00 00 00 00 01 00 14 00 8d 9f 30 38 00 00 00 00 |..........08....|
00000010 04 03 02 01 10 02 1f 90 0a 0b 0c 0d 00 00 00 00 |................|
00000020 00 00 00 00 |....|
00000024
Другая задача: протегировать пакет так, будто бы он пришел из divert-сокета, и надо, чтобы он продолжил с определенного правила ipfw. Релевантные фрагменты кода:
#define PACKET_TAG_DIVERT 17 /* divert info */
#define MTAG_ABI_COMPAT 0 /* compatibility ABI */
#define IP_FW_DIVERT_LOOPBACK_FLAG 0x00080000
struct divert_tag {
u_int32_t info; /* port & flags */
u_int16_t cookie; /* ipfw rule number */
};
...
dtag->cookie = 6000; /* ipfw rule num */
dtag->info = IP_FW_DIVERT_LOOPBACK_FLAG | 2048; /* divert port and flag */
В итоге получаем такой скрипт, тестируя вручную сделанным ICMP-пакетом:
# ngctl
+ mkpeer . hub tst tst
+ name tst divhub
+ mkpeer divhub: tag mark in
+ name divhub:mark xtag
+ mkpeer xtag: ip_input out divert2048
+ name xtag:out ip_input
+ msg xtag: sethookin { thisHook="in" ifMatch="out" ifNotMatch="out" }
+ msg xtag: sethookout { thisHook="out" tag_cookie=0 tag_id=17 tag_len=8 tag_data=[0x00 0x08 0x08 0x00 0x70 0x17] }
#
# ipfw show 50 6001
00050 0 0 count ip from 192.168.0.0/16 to any
06001 0 0 count ip from 192.168.0.0/16 to any
06001 0 0 count ip from 192.168.0.0/16 to any in
06001 0 0 count ip from 192.168.0.0/16 to any in diverted
# perl -pe 's/(..)[ \t\n]*/chr(hex($1))/ge' <
45 00 00 54 cb 13 00 00 40 01 b9 87 c0 a8 2b 65
0a 00 00 01 08 00 f8 d0 c9 76 00 00 45 37 01 73
00 01 04 0a 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13
14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23
24 25 26 27 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33
34 35 36 37
EOF
# ipfw show 50 6001
00050 1 84 count ip from 192.168.0.0/16 to any
00050 0 0 count ip from 192.168.0.0/16 to any in
00050 1 84 count ip from 192.168.0.0/16 to any out
06001 1 84 count ip from 192.168.0.0/16 to any
06001 1 84 count ip from 192.168.0.0/16 to any in
06001 1 84 count ip from 192.168.0.0/16 to any in diverted
Вполне работает. Опытным путем выяснено, однако, что, в tag_len нужно писать значение, кратное 4, хотя нужны нам всего 6 байт (иначе возвращает EINVAL). Что это за артефакт ng_parse() такой, еще не разбирался.
ng_nat
Этот узел в качестве примера был рассмотрен в предыдущем посте. Он практически дублирует интерфейс программиста к библиотеке libalias(3), а потому подробности нужно смотреть в соответствующем мане, а также в man natd, который тоже сделан на основе libalias (принципы те же самые).
ng_patch
Узел для модификации содержимого проходящих через него пакетов. Подробно описан в man-странице и посте http://nuclight.livejournal.com/126002.html
ng_car
Простой шейпер трафика, реализующий Commited Access Rate (RFC 2697, RFC 2698), CIR (Committed Information Rate), RED и другие слова, знакомые заводчикам Cisco. Поэтому, кроме man-страницы самого узла, следует изучить и соответствующую документацию по теме.
ng_pipe
Это шейпер, реализующий тот же механизм, что в dummynet - ipfw pipe. К сожалению, документации по узлу в настоящее время нет (придется читать исходники).
А дальше?
Да, выше описаны не все узлы, что есть в системе. Не рассмотрен, например, ряд протоколов, скажем, узлы реализаций ATM и Bluetooth. Но я выражаю надежду, что с популяризацией netgraph количество узлов увеличится, тем более, что узел netgraph написать проще, чем "обыкновенный" модуль ядра. Здесь осталось только напомнить разработчикам следовать идеологии netgraph - каждый узел изолирован, делает свою, узко очерченную часть работы, и может быть скомбинирован неизвестно заранее с чем. Другими словами, делайте не сразу сходу решение вашей конкретной задачи, а подумайте, как её можно обобщить, для чего еще приспособить (если, конечно, хотите, чтобы узел был принят в базовую систему FreeBSD). Так, ng_tag вместо тегов одного лишь ipfw может решать и другие задачи, ng_patch вместо правки одного лишь поля ToS/DSCP умеет любые арифметические операции с любым местом пакета, и т.д., при том, что эти изменения не потребовали много кода.
Что ж, в AANG есть некоторые интересные идеи для будущего, а на сегодня пока всё. Удачи.