Netgraph для пользователя
Многие слышали о сетевой подсистеме Netgraph во FreeBSD, но далеко не все представляют себе, что же это такое, как оно работает, и зачем оно нужно - кроме того, что на нем работает mpd (известная очень производительная реализация PPP/PPTP/L2TP). Да еще по сети ходят многочисленные Howto типа "как считать Netflow на нетграфе", где приводят примеры решения конкретных задач, о самой же подсистеме рассказывая "галопом по Европам" (пишите, мол, так, "синтаксис такой-то").
Проблема в том, что вся документация по netgraph рассчитана на программистов: как маны, так и единственная достаточно подробная статья от автора подсистемы "Все о Netgraph" - в ней дается общий обзор, а за подробностями читатель отсылается в исходники. Что, разумеется, отпугивает новичков, поскольку кажется слишком сложным, а читатели, привыкшие к другим ОС, часто не понимают суть системы и зачем она нужна, если есть vtun, ipt_netflow и другие решения для типовых частных случаев.
Между тем netgraph - это реализованный в ядре коммуникационный фреймворк общего назначения, и в использовании он не сложнее, чем длинная командная строка вида "prog1 | grep | sort | sed | prog2 | awk", просто для начала необходимо понять ряд вещей, о которых я и попытаюсь рассказать доступным языком.
(Примечание: далее будут использованы некоторые фрагменты упоминавшейся выше статьи "All about NetGraph", и кое-где будут примечания с пометкой AANG, показывающие места, в которых та статья уже устарела)
Да, netgraph рассчитан прежде всего на программистов, и требуется иметь некоторое представление о программировании, чтобы его понять. Но знать о некоторых понятиях программирования, синтаксисе описания структур в Си и т.д. - совсем не то же, что действительно программировать. В конце концов, любой администратор, который пишет скрипты, уже немножко программист. Ну а глубокое понимание того, как система работает - необходимое условие как для просто нетривиальных настроек, так и, скажем, оптимизации на максимальную производительность... кто тюнил систему под 100-200 тысяч одновременных соединений, поднимите руки :)
Лирическое отступление и пояснения на аналогиях
Представьте себе, что Вы - гриб IP-пакет
[...]
Этот раздел с кривыми аналогиями оказался неудачен и только запутывал читателя вместо понимания, поэтому был из статьи выкинут. Вместе с литературной критикой этой самой статьи (которую вы прям щас читаете), его можно прочитать в отдельном посте (если интересно).
[...]
Известно правило 80/20, в разных формулировках, применимое во многих областях (не всегда в именно такой буквальной пропорции, конечно). И если 80% задач - типовые и решаются сравнительно легко, то netgraph предназначен для решения тех 20% задач, которые сложные, и на которые нужно потратить, соответственно, больше усилий.
Итак,
Что же это такое?
Если название вызвало у Вас ассоциации из дискретной математики - Вы правильно подумали. Netgraph действительно представляет собой граф. Идея проста: есть узлы (nodes, ноды) и ребра (edges) которые соединяют пару узлов. Пакеты данных (mbuf) идут в двух направлениях вдоль ребер от узла к узлу. Когда узел получает пакет данных, он обрабатывает его, и затем (обычно) отправляет его другому узлу. Нет требований, чтобы данные следовали строго в определенном направлении (хотя некоторые типы узлов такое ограничение налагают), и нет ограничений на действия, которые узел выполняет с пакетом - т.е. граф неориентирован, и за циклами надо следить самостоятельно.

На этом математика заканчивается, и начинаются особенности netgraph. Каждое ребро (edge) в действительности не существует как таковое - оно всегда состоит из двух сцепленных крючков (хуков, hooks). Каждый хук всегда принадлежит своему узлу и имеет имя, уникальное в пределах узла (разные узлы могут иметь хуки с одинаковыми именами). Хук может существовать только в соединенном виде, т.е. в паре с хуком с другого узла. Имя хука задается только один раз при его создании (соединении узлов) и обычно несет смысл в контексте узла, который ему принадлежит. Например, ng_iface через хук с именем inet принимает и отправляет IP-пакеты, а через хук с именем ipx - соответственно, IPX. Собственно, узлы при отправке данных и оперируют не самими подключениями к соседям (им плевать, кто там), а своими хуками. Если случается попытка отправить пакет через хук, который сейчас не подключен (т.е. не существует хука с таким именем), пакет молча дропается системой. Операция соединения узлов, т.е. создания двух хуков - трехшаговая, поскольку каждый узел сначала спрашивается, хочет ли он иметь хук с таким именем (у ряда узлов имена хуков жестко определены), и узел может отказать в подключении (AANG: ранее, до SMP, операция соединения была атомарной, сейчас разделена во избежание возможных дедлоков).
Адресация и имена
Для управления netgraph обычно используется ngctl(8). Чтобы понимание было четче, было бы неплохо уже показать примеры и иллюстрации, но чтобы их толково показать, нужно достаточно полно описать ngctl, а полно не получится, пока не объяснен ряд вещей из этого и следующих разделов. Поэтому сначала только посмотрим на готовые графы. Итак, есть машина с FreeBSD и mpd4, имеющим одно клиентское подключение по PPPoE. Берем рута и смотрим, что там mpd насоздавал?
# ngctl list
There are 10 total nodes:
Name: Type: pppoe ID: 00000007 Num hooks: 2
Name: Type: socket ID: 00000004 Num hooks: 0
Name: mpd805-stkp-mss Type: tcpmss ID: 00000009 Num hooks: 2
Name: mpd805-stkp Type: ppp ID: 00000003 Num hooks: 3
Name: ng0 Type: iface ID: 00000002 Num hooks: 1
Name: rl0 Type: ether ID: 00000005 Num hooks: 1
Name: mpd805-stkp-so Type: socket ID: 00000001 Num hooks: 1
Name: ngctl85814 Type: socket ID: 0000002b Num hooks: 0
Name: mpd805-stats Type: socket ID: 00000008 Num hooks: 0
Name: ed0 Type: ether ID: 00000006 Num hooks: 0
Команда ngctl list показывает, как нетрудно догадаться, список всех имеющихся сейчас в ядре узлов. Очевидным является так же, что у каждого узла есть свой тип (поле Type) и энное количество подключенных хуков. Менее очевидным является то, что у узла может быть имя, но может его и не быть. Кроме того, у каждого узла всегда есть ID (шестнадцатеричное число), гарантированно уникальный с последнего ребута (если узел будет уничтожен, его ID никем не будет занят). Как имя, так и ID используются для целей адресации. Адрес узла (node address) или путь (path) - это просто ASCII-строка, идентифицирующая узел, и, как уже, возможно, Вам подсказали ассоциации, путь может быть абсолютным или относительным.
Абсолютный адрес состоит из имени узла и двоеточия. Например, выше в списке был узел с именем ng0, его абсолютный адрес будет "ng0:". Если у узла нет имени, в качестве имени может быть использован ID в квадратных скобках, т.е. "[2]:" или "[0002]:" будет указывать на тот же ng0 (нули необязательны, ибо ID - число //ваш K.O.).
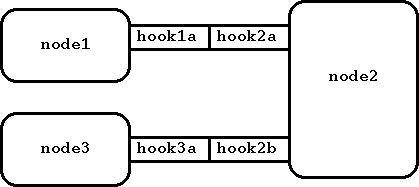
Относительная адресация задает путь к узлу от какого-либо другого узла через имена хуков по соединяющему их пути. Во-первых, адрес ".:" или просто "." всегда указывает на локальный узел. Рассмотрим три узла на нагло спертом из AANG рисунке слева, пусть локальным будет узел node1. Тогда, если node1 хочет адресовать узел node2, он может использовать адрес ".:hook1a" или просто "hook1a". Для обращения к узлу node3, он может использовать адрес ".:hook1a.hook2b" или просто "hook1a.hook2b". Аналогично, узел node3 может обратиться к узлу node1, используя адрес ".:hook3a.hook2a" или просто "hook3a.hook2a".
Относительные и абсолютные адреса можно сочетать, например, "node1:hook1a.hook2b" будет указывать на узел node3.
Применим это на практике, на той машине, откуда был получен листинг выше. Для ngctl локальным узлом является узел типа ng_socket с именем из строки "ngctl" и PID процесса ngctl (как и видно в листинге выше). Команда ngctl show показывает более подробную информацию об узле:
Максимальные длины ASCII-строк netgraph, актуальные для админа (программисты сами посмотрят остальные в ng_message.h), составляют (включая терминирующий null):
#define NG_HOOKSIZ 32 // имя хука
#define NG_NODESIZ 32 // имя узла
#define NG_PATHSIZ 512 // путь/адресПервые два в старых версиях FreeBSD равнялись 16 (из-за чего у mpd они могли иногда не влезать, по каковой дурацкой причине он у некоторых не обслуживал более 100 или 1000 клиентов).
# ngctl show rl0
ngctl: send msg: No such file or directory
# ngctl show rl0:
Name: rl0 Type: ether ID: 00000005 Num hooks: 1
Local hook Peer name Peer type Peer ID Peer hook
---------- --------- --------- ------- ---------
orphans pppoe 00000007 ethernet
# ngctl show rl0:orphans
Name: Type: pppoe ID: 00000007 Num hooks: 2
Local hook Peer name Peer type Peer ID Peer hook
---------- --------- --------- ------- ---------
mpd805-PPPoE mpd805-stkp ppp 00000003 link0
ethernet rl0 ether 00000005 orphans
# ngctl show [009]:
Name: mpd805-stkp-mss Type: tcpmss ID: 00000009 Num hooks: 2
Local hook Peer name Peer type Peer ID Peer hook
---------- --------- --------- ------- ---------
out ng0 iface 00000002 inet
in mpd805-stkp ppp 00000003 inet
Здесь видна и адресация безымянного узла по ID, и сочетания абсолютной и относительной адресации. А также типичная ошибка по невнимательности: забыли указать двоеточие, и netgraph не нашел такой узел. Если кто-то при наборе длинных команд и получении ошибок на это матерился - что ж, теперь знаете, почему синтаксис именно такой.
Интерлюдия: немного иллюстраций

Интерфейс командной строки - это, конечно, хорошо, но кто-то уже прикидывает, что, хотя ngctl list и ngctl show и достаточны для просмотра узлов и их связей, в голове собирать из этого картинку всё-таки тяжело. Вот бы оно еще умело графически показывать, что там и как?..
Так вот - умеет! Ну, не само, конечно (зачем иксы на роутер тащить). Есть такой пакет визуализации графов ports/graphics/graphviz, он умеет автоматически рисовать графы по заданному текстовому описанию на специальном языке. А ngctl умеет выводить информацию об узлах на этом языке. Итак, ставим graphviz, и в соответствии с заветами Unix way соединяем одно с другим:
# ngctl dot | dot -Tpng > dot.netgraph.png
В результате имеем картинку в формате PNG (умеет также и другие растровые, и html-карты, и SVG), наподобие той, что приведена справа (где изображено подключение ng_ipacct c ng_ether и ng_tee).
Следует помнить, что в этом формате как узлы, так и хуки netgraph являются узлами изображенного графа - просто узлы netgraph изображены как прямоугольники (подписаны имя, ID, тип), а хуки netgraph - как восьмиугольники, и ребра, соединяющие узел со своими хуками, более жирные. Так сделано для большей наглядности и выделенности хуков, а также потому, что при обычном рисовании графа не получилось бы у одного ребра написать два названия (ведь ребро netgraph состоит из двух хуков).
Еще нужно заметить, что graphviz состоит из нескольких программ, реализующих разные алгоритмы визуализации, по-разному раскладывающих узлы на листе-картинке. Кроме dot есть еще neato, twopi, а, например, картинка выше (и ниже) получены с помощью fdp - по моему опыту, конкретно графы netgraph он рисует более оптимально (другие склонны оставлять слишком много пустого пространства при больших размерах картинки).
Можно ознакомиться с тем, что в свое время сгенерировал graphviz на роутере с FreeBSD 6, где местами развесистая конфигурация узлов была сгенерирована сразу несколькими сущностями: mpd 3.18 (ng3 в соединенном состоянии), rc.d-скрипт ng_ipacct из портов, самодельный rc.d-скрипт для ng_nat с простым языком конфигурирования, и вручную добавленный ng_tcpmss:

Кстати сказать, другая замечательная подсистема FreeBSD - GEOM - тоже умеет выводить свою конфигурацию в пригодном для построения графа виде. Если у Вас что-то сложнее gmirror, то sysctl -b kern.geom.confdot скорее всего пригодится посмотреть, как оно там внутри.
Объектно-ориентированный и функциональный
Выше было сказано, что у каждого узла есть свой тип. Это не просто некий неопределенный тип: netgraph имеет объектно-ориентированную архитектуру (в том количестве, насколько это необходимо в ядре и возможно на Си). В терминах ООП, каждый тип есть класс, наследующий от общего предка (поэтому все узлы имеют унаследованную возможность "иметь имя", например). Внутри тип есть просто таблица методов (указателей на функции), автору модуля достаточно не указывать свой собственный метод, чтобы унаследовать поведение по умолчанию. Каждый узел, соответственно, есть объект, instance класса, и в полном соответствии с принципом инкапсуляции ООП внутреннее состояние узла нельзя посмотреть - можно только спросить его самого об этом.
А вот тут, как и с полиморфизмом, начинаются вещи, непривычные для большинства сегодняшних пользователей ООП. Netgraph реализует ООП в изначальном, классическом смысле, как в Smalltalk (в современных и популярных так делают разве что в Ruby) - вместо вызовов методов делается посылка сообщений. В литературе их часто называют управляющими сообщениями, посвященный им раздел в мане по каждому узлу называется CONTROL MESSAGES. Почему так? Потому что в статическом OO-языке методы известны во время компиляции, в netgraph же заранее неизвестно, какие будут типы - система на ходу. Узел должен иметь возможность принять что угодно, а не только жестко заданные методы.
Сообщение есть просто заголовок и произвольная структура данных в качестве аргумента. Заголовок содержит имя сообщения, тип/семейство (так называемый cookie), длину аргументов, флаг того, является ли это сообщением ответом (reply control message) на другое. Имя и тип сообщения - просто числовые константы. Узел, получив сообщение, может вернуть либо одно число - код ошибки из стандартного набора errno(2) (ngctl напечатает тогда соответствующую строку), если он не умеет обрабатывать такое сообщение, или ему не понравился формат аргументов. Либо, если всё нормально, чуть позже узел посылает сообщение-ответ с необходимыми данными.
Подобным образом, сообщениями, реализовано вообще всё управление netgraph. Возможность адресации существует исключительно для посылки сообщений (в дополнение к стандартной отправке соседу вдоль хука). Сами команды ngctl в действительности почти все представляют собой отправку сообщений. Например, ngctl show отправляет указанному узлу сообщение NGM_LISTHOOKS. Он отвечает сообщением, в аргументе которого содержится список его хуков, который ngctl и печатает в красивом виде. Или соединить два узла (ngctl connect) - узлу посылается сообщения "соединись-ка ты с вон тем, сделав себе хук с именем X, а ему Y" - и тот послушно выпускает из себя хук и соединяется. Никаких специальных функций, всё средствами фреймворка же. Полный ООП.
Собственно, обработка этих стандартных сообщений, соответствующих командам ngctl, наследуется узлами от общего предка, в манах их называют generic control messages. Поскольку узлу никто не запрещает реализовать обработку каких угодно сообщений (обычно, по соглашению, он обрабатывает лишь сообщения со своим cookie), то возможен и своего рода полиморфизм, если узел обработает и какие-нибудь "чужие" сообщения (duck typing в Ruby или интерфейсы в Go). Некоторые узлы в базовой системе это используют.
В подзаголовке было еще слово "функциональный", как подчеркивалось в AANG. Да, здесь действительно есть параллели с функциональным программированием, но разве что отдаленные. Имелось в виду, что стиль работы узлов при получении пакета - прямой вызов функции-обработчика следующего узла, куда он передается по хуку (и сделан вызов будет в конце нашего обработчика, этакая хвостовая рекурсия). В наше время, с введением SMP, это уже не совсем так: нередко пакет ставится в очередь, чтобы избежать дедлоков. Так же на некоторых архитектурах есть эвристика, которая следит за использованием стека, при слишком большом числе вызовов тоже ставит пакет в очередь (а то будет еще Fatal trap 12). В остальных случаях да, для повышения скорости работы netgraph использует прямые вызовы функций.
Универсальный синтаксис: ng_parse()
Сообщения посылаются командой ngctl msg, и, как Вы уже, быть может, видели в примерах, там указываются вполне человекочитаемые строки, однако здесь и в манах речь идет о каких-то константах. Здесь скрывается одна из наиболее ярких особенностей netgraph, которую довольно скупо освещают в документации, а на русском языке я её описания вообще не видел (AANG дает очень краткий обзор для программиста и отсылает к исходному коду).
Напомню, netgraph (и его документация) был сделан прежде всего для программиста, и рассчитан для максимального его удобства. Когда узел получает управляющее сообщение, он получает его сразу в виде готовой Си-структуры. Никакого кода для парсинга строк, обработки конфигов, проверки на ошибки и т.д. - всё уже готово. Программисты оценят. В man-страницах, соответственно, приводятся константы и структуры из заголовочных файлов, вставляй в код и работай. Однако следом сразу же возникает вопрос, а как им тогда из командной строки управлять - на каждый чих писать и компилировать программу на Си, что ли? Для пользователя будет уже совсем неудобно. Ответом стало очень изящное решение, красивое как в идее, так и элегантное в реализации (одни виртуальные методы на Си-препроцессоре чего стоят) - предоставить средство для автоматического перевода бинарных Си-структур в человекочитаемую ASCII-форму и обратно.
Реализуется это так. Каждый узел в специальном виде описывает свои структуры для парсера. Потом пользователь дает ngctl нечто текстовое, предназначенное для узла. Поскольку ngctl не знает, что с этим делать, он посылает узлу сообщение NGM_ASCII2BINARY. Узел, в смысле определенных автором функций, тоже об этом ничего не знает - на сообщение отвечает унаследованный от фреймворка метод, который вызывает ng_parse() и отправляет ответ со структурой в бинарном виде (или ошибку). После чего ngctl полученное бинарное сообщение уже собственно шлет узлу. Если от него приходит ответ, то ngctl опять же не знает, как этот ответ показать пользователю, процедура повторяется сообщением NGM_BINARY2ASCII.
Итак, синтаксические правила (во многом напоминающие сам Си) такие:
Структуры:
'{' [ = ... ] '}'
Массивы:
'[' [ [index=] ... ] ']'
Думаю, не требуется пояснять, что, поскольку на выходе получаются структуры Си, то работают и правила Си, т.е. элементом массива может быть, например, структура, и т.д.
Пример (двоичные значения показаны для i386 с учетом выравнивания компилятором, пользователь может не заморачиваться, программисту же ясно, что фреймворк обрабатывает и это):
Структура Двоичное значение в памяти
--------- --------------------------
struct foo {
struct in_addr ip; 01 02 03 04
int bar; 00 00 00 00
char label[8]; 61 62 63 0a 00 00 00 00
u_char alen; 04 00
short ary[]; 05 00 00 00 0a 00 06 00
};
Значение в ASCII
----------------
{ ip=1.2.3.4 label="abc\n" alen=3 ary=[ 5 2=10 6 ] }
Обратите внимание на значения по умолчанию. Можно было написать "bar=0", но фреймворк автоматически выставил пропущенное значение в 0. В массиве ary элемент с индексом 0 имеет значение 5, а элемент с индексом 1 - нулевое (по умолчанию), и потому пропущен. Однако пропущенным он считается по причине того, что у следующего указан явный индекс 2 - если бы элементы были просто перечислены, логично, что они шли бы по порядку. Следом идет элемент со значением 6, индекс равен индексу предыдущего плюс один, т.е. 2+1=3. Можно было бы указать этот массив и как "ary=[ 5 0 0x0a 6 ]". Явное указание индексов удобно, если у Вас большие массивы, в основном пустые.
Чем удобно решение ng_parse() для пользователя, сравнительно с альтернативами? Синтаксис - единый, ничего не нужно учить для каждого типа узла. Они, конечно, различны, но это данные у них разные, а не язык. В то же время, типичный подход, к примеру, в Linux - создавать файлы в /proc. В этом случае каждому автору приходится заниматься не только "вклейкой" кода VFS, но и обработкой параметров вручную. В результате чего на каждый чих появляется свой новый синтаксис - если задача сложнее тривиального echo 1 >> /proc/..., конечно. Разумеется, в случае больших объемов данных или других сложных случаев и синтаксис ng_parse() станет неудобен - в таком случае пишется отдельная программа управления, например, mpd для своего вороха типов узлов, или ipacctctl для ng_ipacct.
Пример работы и использования документации
Что ж, выше было уже достаточно теории, чтобы можно было наконец перейти к практике. Получим навыки использования ngctl и man-cтраниц netgraph, реализовав на нем что-нибудь хорошо известное. Для такой задачи сгодится ng_nat(4).
Бегло просмотрев man, выясняется, что ng_nat сделан на базе той же библиотеки libalias, что и natd, а значит, применима вся имеющая информация по прохождению пакетов и конфигурированию natd. То есть, надо зарулить пакеты через ipfw. Секция SEE ALSO ссылается на ng_ipfw(4). Открываем его и узнаём из секции HOOKS, что нода разрешает любые имена хуков, при условии, что они числовые. "Напоминает номера divert-портов", - подумал Штирлиц. Дальше идет какая-то непонятная админу секция, явно для программистов. Единственный полезный вывод мы можем сделать только из её первого и последнего абзаца - во-первых, ноду просто так не создать, надо загрузить модуль ядра, во-вторых, пакеты ведут себя так же, как в случае divert: продолжают со следующего правила. Причем только такие пакеты, которые вышли из ng_ipfw - другие она выкинет. Секция SHUTDOWN, в отличие от многих других узлов, говорит, что ng_ipfw существует постоянно и не исчезает, если от него отключить все хуки. И вообще лучше её не гасить. OK, сделаем kldload ng_ipfw и вернемся к ману по ng_nat.
Из секции HOOKS узнаем, что хуков два - аналогичных ключам -i и -o у natd. Поскольку минимальная настройка NAT требует всего лишь указания интерфейса, нам хватит только одного управляющего сообщения: NGM_NAT_SET_IPADDR (setaliasaddr). Обратим внимание, что после значения константы в скобках приведено ASCII-имя сообщения. В некоторых man-страницах они отсутствуют: вероятно, приславших патчи с этими узлами авторов недостаточно шпыняли насчет качества документации. Что ж, таков опенсорс, здесь никто никому ничего не должен, но в подобных случаях всё же остается возможность посмотреть исходник...
Теги пакета
В AANG упоминалась структура ng_meta для передачи связанной с пакетом метаинформации. Это уже давно не актуально - вместо этого теперь во всей сетевой подсистеме FreeBSD применяются описанные в mbuf_tags(9) теги пакета. Нет, не надо путать их с VLAN-тегами. Те внутри пакета, mbuf-теги же прикреплены к нему снаружи, и используются в ядре для очень многих целей. Как, например, описано в man ng_ipfw. Теги mbuf применяются, в частности, для действий tag в pf и в ipfw, и надо подчеркнуть, что это НЕ те же самые теги, что у ng_ipfw, а другой подтип mbuf-тегов. Для обобщенного манипулирования mbuf-тегами (например, man по узлу может упоминать про теги) в netgraph существует ng_tag(4), хотя рядовому админу этот узел скорее всего понадобится только для проверки/навешивания ipfw tag.
Итак, запускаем ngctl, и на этот раз в интерактивном режиме. Поскольку оригинал каждый может посмотреть сам, я сделаю перевод вывода:
# ngctl
Доступные команды:
config Получить/установить конфигурацию узла по адресу "path"
connect Соединить хук "peerhook" узла по адресу "relpath" к хуку "hook"
debug Получить/установить уровень вывода отладочной информации
dot Выдать GraphViz (.dot) всего netgraph целиком.
help Показать этот список команд или справку по конкретной команде
list Показать список всех узлов
mkpeer Создать и присоединить новый узел к узлу по адресу "path"
msg Отправить управляющее сообщение узлу по адресу "path"
name Присвоить имя "name" узлу по адресу "path"
read Прочитать и выполнить команды ngctl из файла
rmhook Отсоединить хук "hook" от узла с адресом "path"
show Показать информацию об узле с адресом "path"
shutdown Погасить узел по адресу "path"
status Получить текстовый статус узла с адресом "path"
types Вывести информацию обо всех загруженных типах узлов
write Отправить пакет данных через хук "hook".
quit Выйти из программы
+ mkpeer ipfw: nat 60 out
+ name ipfw:60 nat
+ connect ipfw: nat: 61 in
+ msg nat: setaliasaddr 82.117.64.1
+ quit
# ipfw add 300 netgraph 61 all from any to any in via fxp0
# ipfw add 400 netgraph 60 all from any to any out via fxp0
# sysctl net.inet.ip.fw.one_pass=0
Всё, NAT настроен (последние 3 команды шеллу - это правила отправки трафика в netgraph и инструкция возвращать пакеты в ipfw обратно). Что отсюда очевидно? Что достаточно всего 4 команд ngctl для настройки, причем без name можно было и обойтись - именовали исключительно для удобства набора последующих команд (и доступа при последующих запусках). Более интересно, однако, то, что не очевидно сразу. Например, то, что в интерфейсе нет команды для просто создания узла - mkpeer обязательно соединяет его с каким-то уже существующим, то есть, требует его наличия. В нашем примере узел ipfw: уже существовал перед запуском ngctl, так же часто достаточно заранее существующих узлов ng_ether. Во всех остальных случаях конструирование графа придется начать с единственного доступного узла - созданного запущенным ngctl. И учитывать, что при выходе из ngctl этот узел и присоединенные к нему хуки - исчезнут (а многие узлы сами делают себе shutdown, если им оторвали все хуки). Поэтому многие вещи придется делать за один запуск ngctl (например, используя синтаксис < шелла, если не интерактивно), и даже тогда в некоторых случаях придется делать сборку схемы в определенном порядке или с использованием промежуточных узлов, которые потом будут убраны (например, если в планируемой схеме узлы поддерживают строго ограниченное число хуков). Некоторая информация по таким узлам будет дана позже.
Еще нужно пояснить некоторые команды из списка ngctl, которые могли кого-то заинтересовать. Команда status предназначена для получения информации о состоянии узла в произвольном текстовом (человекочитаемом) формате. В базовой системе её реализуют только некоторые узлы, главным образом, в подсистемах ATM, Bluetooth, а также ng_lmi и ng_cisco. Команда config задает конфигурацию узла, но реально в базовой системе поддерживается только драйвером mn(4) - потому что передается тоже в текстовом виде и требует парсинга самим узлом. Поэтому во всех остальных местах опираются ряд управляющих сообщений и ранее уже описанный ng_parse().
Вернемся к нему и мы, и к man-странице по ng_nat. Вот нам понадобился проброс портов. Что ж, читаем про сообщение NGM_NAT_REDIRECT_PORT и видим там структуру, говорящую нам, какие имена переменных следует использовать. Ба, да там еще и плюшка по сравнению с другим видами NAT обнаружилась - каждому пробросу можно задать до 64 символов описания текстом! Что ж, воспользуемся, и оформим команды шеллу красиво и читаемо:
# ngctl msg nat: redirectport '{
> alias_port=6881
> local_port=6881
> local_addr=192.168.4.4
> proto=6
> description="For uTorrent TCP"
> }'
Rec'd response "redirectport" (4) from "[33]:":
Args: 1
# ngctl msg nat: redirectport '{
> alias_port=6881
> local_port=6881
> local_addr=192.168.4.4
> proto=17
> description="For uTorrent UDP"
> }'
Rec'd response "redirectport" (4) from "[33]:":
Args: 2
На каждое сообщение узел немедленно отвечал каким-то числом. Как говорит man, это ID редиректа в списке, который потом можно пихать в другие сообщения. Посмотрим на этот список:
# ngctl msg nat: listredirects
Rec'd response "listredirects" (10) from "[33]:":
Args: { total_count=2 redirects=[ { id=1 local_addr=192.168.4.4 local_port=6881 alias_port=6881 proto=6 description="For uTorrent TCP" } { id=2 local_addr=192.168.4.4 local_port=6881 alias_port=6881 proto=17 description="For uTorrent UDP" } ] }
Итак, узел ответил структурой ng_nat_list_redirects, в которой, как говорит man, лежит количество элементов списка, и затем массив структур ng_nat_listrdrs_entry - в них, внутри квадратных и фигурных скобок, мы и наблюдаем те id, которыми узел отвечал при создании редиректов. Здесь следует обратить внимание на довольно часто используемый в netgraph прием, как при отдаче информации наружу, так и при конфигурировании пользователем - перед массивом структур лежит переменная, в которой указано число элементов в нём. Это важно: если какой-то узел принимает в конфигурации массив, придется посчитать их и сказать ему, сколько. Впрочем, это обычно несложно :)
Вывод отформатирован, к сожалению, не так красиво, но всё же еще читаемо. Зато это единственный NAT, который дает возможность править пробросы портов на ходу, без перезапуска. Не обязательно, конечно, пользоваться им, конфигурируя "от и до" самому: NAT в mpd сделан на базе именно этого узла, основную конфигурацию можно держать в конфиге mpd, и при необходимости чего-то нетривиального всё-таки иметь возможность это сделать.
Тем же, кому хочется вывод из ngctl "поудобнее", можно посоветовать вспомнить Unix way - текстовый вывод легко трансформировать командой ngctl msg nat: listredirects | tr -s '{}[]' ' \n\n ' | sed '1,2d;/^( )*$/d;s/Args...//g' (подойдет для любого вывода, не только для ng_nat).
Вместо заключения
Еще можно было бы рассказать об утилите nghook(8), служащей для подключения обычных pipeline'ов шелла к узлам netgraph. Но это слишком просто, так что она будет показана в составе примера, призванного продемонстривать, для каких неожиданных вещей может быть использован netgraph.
Допустим, есть такая задача: организовать вещание multimedia-потока на огромное количество клиентов, при условии, что multicast недоступен. Известно: типичный media stream устроен так, что его можно начать обрабатывать с любого места, клиент сам поймает синхронизацию. И серверу вещания более полезно занимать свой CPU непосредственно сжатием, а не обработкой клиентов (с чем он справляется хуже). Возникает идея сделать его бэкендом, а фронтендом поставить специальный прокси, который просто копирует клиентам поток. В простейшем случае по HTTP алгоритм работы таков: взять заголовки HTTP-запроса клиента, дать их серверу, запомнить HTTP-заголовки ответа, отдать клиенту (и отдавать их каждому новому клиенту), далее основной цикл - прочитать от бэкенда порцию, скопировать её в сокеты всем клиентам. С точки зрения highload здесь сразу видно три неоптимальные вещи:
Решение ниже приведено как готовые скрипты для копипаста и проверено в работе на VLC, вещающем видео в MPEG-TS. Перед началом работы прицепимся к бэкенду и сохраним от него заголовки HTTP-ответа, которые потом отдавать клиентам:
# /usr/bin/printf "GET / HTTP/1.1\r\nRange: 0-\r\nIcy-MetaData: 1\r\n\r\n" | nc 10.0.0.4 19080 | dd of=http.reply count=2
Далее создадим и соединим сокет к бэкенду, а также хаб-разветвитель:
/usr/sbin/ngctl -f- <<-SEQ
mkpeer . hub tmp tmp
name .:tmp fanout
mkpeer fanout: ksocket up inet/stream/tcp
name fanout:up upstream
msg upstream: connect inet/10.0.0.4:19080
SEQ
/usr/bin/printf "GET / HTTP/1.1\r\nRange: bytes=0-\r\nIcy-MetaData: 1\r\n\r\n" | nghook fanout:
ngctl
mkpeer . ksocket listen inet/stream/tcp
name .:listen servsock
msg servsock: bind inet/0.0.0.0:8080
msg servsock: listen 64
msg servsock: accept
Как видно, ngctl запущен в интерактивном режиме (чтоб не шатдаунился слушающий сокет). Теперь ждем клиентов. Когда прицепится первый из них, ngctl напишет примерно такое:
Rec'd response "accept" (3) from "[13]:":
Args: { nodeid=0x1d addr={ len=16 family=2 data=[ 0x6 0xd 0xa 0x0 0x0 0x4 ] } }
На один accept создается только один соединенный узел ksocket, поэтому используем полученный номер (подставим в команды), присоединяя клиента к раздаче, а потом снова делаем accept, который будет ждать следующего (этот шаг повторяется столько, сколько клиентов):
mkpeer . tee l2r left2right
connect l2r [1d]: left ksockhook
write l2r -f http.reply
connect l2r fanout: right 0x1d
shutdown l2r
msg servsock: accept
Конечно, здесь лабораторные условия, для production-использования решение потребует доработки (отсутствует обработка ошибок, убивания отсоединенных сокетов, реконнект к бэкенду, flow control и т.д.), возможно, с написанием специализированного узла и/или демона. Но то уже рутина, а вот сколь велики возможности netgraph, видно очень хорошо.
Проблема в том, что вся документация по netgraph рассчитана на программистов: как маны, так и единственная достаточно подробная статья от автора подсистемы "Все о Netgraph" - в ней дается общий обзор, а за подробностями читатель отсылается в исходники. Что, разумеется, отпугивает новичков, поскольку кажется слишком сложным, а читатели, привыкшие к другим ОС, часто не понимают суть системы и зачем она нужна, если есть vtun, ipt_netflow и другие решения для типовых частных случаев.
Между тем netgraph - это реализованный в ядре коммуникационный фреймворк общего назначения, и в использовании он не сложнее, чем длинная командная строка вида "prog1 | grep | sort | sed | prog2 | awk", просто для начала необходимо понять ряд вещей, о которых я и попытаюсь рассказать доступным языком.
(Примечание: далее будут использованы некоторые фрагменты упоминавшейся выше статьи "All about NetGraph", и кое-где будут примечания с пометкой AANG, показывающие места, в которых та статья уже устарела)
Да, netgraph рассчитан прежде всего на программистов, и требуется иметь некоторое представление о программировании, чтобы его понять. Но знать о некоторых понятиях программирования, синтаксисе описания структур в Си и т.д. - совсем не то же, что действительно программировать. В конце концов, любой администратор, который пишет скрипты, уже немножко программист. Ну а глубокое понимание того, как система работает - необходимое условие как для просто нетривиальных настроек, так и, скажем, оптимизации на максимальную производительность... кто тюнил систему под 100-200 тысяч одновременных соединений, поднимите руки :)
Лирическое отступление и пояснения на аналогиях
Представьте себе, что Вы - гриб IP-пакет
[...]
Этот раздел с кривыми аналогиями оказался неудачен и только запутывал читателя вместо понимания, поэтому был из статьи выкинут. Вместе с литературной критикой этой самой статьи (которую вы прям щас читаете), его можно прочитать в отдельном посте (если интересно).
[...]
Известно правило 80/20, в разных формулировках, применимое во многих областях (не всегда в именно такой буквальной пропорции, конечно). И если 80% задач - типовые и решаются сравнительно легко, то netgraph предназначен для решения тех 20% задач, которые сложные, и на которые нужно потратить, соответственно, больше усилий.
Итак,
Что же это такое?
Если название вызвало у Вас ассоциации из дискретной математики - Вы правильно подумали. Netgraph действительно представляет собой граф. Идея проста: есть узлы (nodes, ноды) и ребра (edges) которые соединяют пару узлов. Пакеты данных (mbuf) идут в двух направлениях вдоль ребер от узла к узлу. Когда узел получает пакет данных, он обрабатывает его, и затем (обычно) отправляет его другому узлу. Нет требований, чтобы данные следовали строго в определенном направлении (хотя некоторые типы узлов такое ограничение налагают), и нет ограничений на действия, которые узел выполняет с пакетом - т.е. граф неориентирован, и за циклами надо следить самостоятельно.
На этом математика заканчивается, и начинаются особенности netgraph. Каждое ребро (edge) в действительности не существует как таковое - оно всегда состоит из двух сцепленных крючков (хуков, hooks). Каждый хук всегда принадлежит своему узлу и имеет имя, уникальное в пределах узла (разные узлы могут иметь хуки с одинаковыми именами). Хук может существовать только в соединенном виде, т.е. в паре с хуком с другого узла. Имя хука задается только один раз при его создании (соединении узлов) и обычно несет смысл в контексте узла, который ему принадлежит. Например, ng_iface через хук с именем inet принимает и отправляет IP-пакеты, а через хук с именем ipx - соответственно, IPX. Собственно, узлы при отправке данных и оперируют не самими подключениями к соседям (им плевать, кто там), а своими хуками. Если случается попытка отправить пакет через хук, который сейчас не подключен (т.е. не существует хука с таким именем), пакет молча дропается системой. Операция соединения узлов, т.е. создания двух хуков - трехшаговая, поскольку каждый узел сначала спрашивается, хочет ли он иметь хук с таким именем (у ряда узлов имена хуков жестко определены), и узел может отказать в подключении (AANG: ранее, до SMP, операция соединения была атомарной, сейчас разделена во избежание возможных дедлоков).
Адресация и имена
Для управления netgraph обычно используется ngctl(8). Чтобы понимание было четче, было бы неплохо уже показать примеры и иллюстрации, но чтобы их толково показать, нужно достаточно полно описать ngctl, а полно не получится, пока не объяснен ряд вещей из этого и следующих разделов. Поэтому сначала только посмотрим на готовые графы. Итак, есть машина с FreeBSD и mpd4, имеющим одно клиентское подключение по PPPoE. Берем рута и смотрим, что там mpd насоздавал?
# ngctl list
There are 10 total nodes:
Name: Type: pppoe ID: 00000007 Num hooks: 2
Name: Type: socket ID: 00000004 Num hooks: 0
Name: mpd805-stkp-mss Type: tcpmss ID: 00000009 Num hooks: 2
Name: mpd805-stkp Type: ppp ID: 00000003 Num hooks: 3
Name: ng0 Type: iface ID: 00000002 Num hooks: 1
Name: rl0 Type: ether ID: 00000005 Num hooks: 1
Name: mpd805-stkp-so Type: socket ID: 00000001 Num hooks: 1
Name: ngctl85814 Type: socket ID: 0000002b Num hooks: 0
Name: mpd805-stats Type: socket ID: 00000008 Num hooks: 0
Name: ed0 Type: ether ID: 00000006 Num hooks: 0
Команда ngctl list показывает, как нетрудно догадаться, список всех имеющихся сейчас в ядре узлов. Очевидным является так же, что у каждого узла есть свой тип (поле Type) и энное количество подключенных хуков. Менее очевидным является то, что у узла может быть имя, но может его и не быть. Кроме того, у каждого узла всегда есть ID (шестнадцатеричное число), гарантированно уникальный с последнего ребута (если узел будет уничтожен, его ID никем не будет занят). Как имя, так и ID используются для целей адресации. Адрес узла (node address) или путь (path) - это просто ASCII-строка, идентифицирующая узел, и, как уже, возможно, Вам подсказали ассоциации, путь может быть абсолютным или относительным.
Абсолютный адрес состоит из имени узла и двоеточия. Например, выше в списке был узел с именем ng0, его абсолютный адрес будет "ng0:". Если у узла нет имени, в качестве имени может быть использован ID в квадратных скобках, т.е. "[2]:" или "[0002]:" будет указывать на тот же ng0 (нули необязательны, ибо ID - число //ваш K.O.).
Относительная адресация задает путь к узлу от какого-либо другого узла через имена хуков по соединяющему их пути. Во-первых, адрес ".:" или просто "." всегда указывает на локальный узел. Рассмотрим три узла на нагло спертом из AANG рисунке слева, пусть локальным будет узел node1. Тогда, если node1 хочет адресовать узел node2, он может использовать адрес ".:hook1a" или просто "hook1a". Для обращения к узлу node3, он может использовать адрес ".:hook1a.hook2b" или просто "hook1a.hook2b". Аналогично, узел node3 может обратиться к узлу node1, используя адрес ".:hook3a.hook2a" или просто "hook3a.hook2a".
Относительные и абсолютные адреса можно сочетать, например, "node1:hook1a.hook2b" будет указывать на узел node3.
Применим это на практике, на той машине, откуда был получен листинг выше. Для ngctl локальным узлом является узел типа ng_socket с именем из строки "ngctl" и PID процесса ngctl (как и видно в листинге выше). Команда ngctl show показывает более подробную информацию об узле:
Максимальные длины ASCII-строк netgraph, актуальные для админа (программисты сами посмотрят остальные в ng_message.h), составляют (включая терминирующий null):
#define NG_HOOKSIZ 32 // имя хука
#define NG_NODESIZ 32 // имя узла
#define NG_PATHSIZ 512 // путь/адресПервые два в старых версиях FreeBSD равнялись 16 (из-за чего у mpd они могли иногда не влезать, по каковой дурацкой причине он у некоторых не обслуживал более 100 или 1000 клиентов).
# ngctl show rl0
ngctl: send msg: No such file or directory
# ngctl show rl0:
Name: rl0 Type: ether ID: 00000005 Num hooks: 1
Local hook Peer name Peer type Peer ID Peer hook
---------- --------- --------- ------- ---------
orphans pppoe 00000007 ethernet
# ngctl show rl0:orphans
Name: Type: pppoe ID: 00000007 Num hooks: 2
Local hook Peer name Peer type Peer ID Peer hook
---------- --------- --------- ------- ---------
mpd805-PPPoE mpd805-stkp ppp 00000003 link0
ethernet rl0 ether 00000005 orphans
# ngctl show [009]:
Name: mpd805-stkp-mss Type: tcpmss ID: 00000009 Num hooks: 2
Local hook Peer name Peer type Peer ID Peer hook
---------- --------- --------- ------- ---------
out ng0 iface 00000002 inet
in mpd805-stkp ppp 00000003 inet
Здесь видна и адресация безымянного узла по ID, и сочетания абсолютной и относительной адресации. А также типичная ошибка по невнимательности: забыли указать двоеточие, и netgraph не нашел такой узел. Если кто-то при наборе длинных команд и получении ошибок на это матерился - что ж, теперь знаете, почему синтаксис именно такой.
Интерлюдия: немного иллюстраций
Интерфейс командной строки - это, конечно, хорошо, но кто-то уже прикидывает, что, хотя ngctl list и ngctl show и достаточны для просмотра узлов и их связей, в голове собирать из этого картинку всё-таки тяжело. Вот бы оно еще умело графически показывать, что там и как?..
Так вот - умеет! Ну, не само, конечно (зачем иксы на роутер тащить). Есть такой пакет визуализации графов ports/graphics/graphviz, он умеет автоматически рисовать графы по заданному текстовому описанию на специальном языке. А ngctl умеет выводить информацию об узлах на этом языке. Итак, ставим graphviz, и в соответствии с заветами Unix way соединяем одно с другим:
# ngctl dot | dot -Tpng > dot.netgraph.png
В результате имеем картинку в формате PNG (умеет также и другие растровые, и html-карты, и SVG), наподобие той, что приведена справа (где изображено подключение ng_ipacct c ng_ether и ng_tee).
Следует помнить, что в этом формате как узлы, так и хуки netgraph являются узлами изображенного графа - просто узлы netgraph изображены как прямоугольники (подписаны имя, ID, тип), а хуки netgraph - как восьмиугольники, и ребра, соединяющие узел со своими хуками, более жирные. Так сделано для большей наглядности и выделенности хуков, а также потому, что при обычном рисовании графа не получилось бы у одного ребра написать два названия (ведь ребро netgraph состоит из двух хуков).
Еще нужно заметить, что graphviz состоит из нескольких программ, реализующих разные алгоритмы визуализации, по-разному раскладывающих узлы на листе-картинке. Кроме dot есть еще neato, twopi, а, например, картинка выше (и ниже) получены с помощью fdp - по моему опыту, конкретно графы netgraph он рисует более оптимально (другие склонны оставлять слишком много пустого пространства при больших размерах картинки).
Можно ознакомиться с тем, что в свое время сгенерировал graphviz на роутере с FreeBSD 6, где местами развесистая конфигурация узлов была сгенерирована сразу несколькими сущностями: mpd 3.18 (ng3 в соединенном состоянии), rc.d-скрипт ng_ipacct из портов, самодельный rc.d-скрипт для ng_nat с простым языком конфигурирования, и вручную добавленный ng_tcpmss:

Кстати сказать, другая замечательная подсистема FreeBSD - GEOM - тоже умеет выводить свою конфигурацию в пригодном для построения графа виде. Если у Вас что-то сложнее gmirror, то sysctl -b kern.geom.confdot скорее всего пригодится посмотреть, как оно там внутри.
Объектно-ориентированный и функциональный
Выше было сказано, что у каждого узла есть свой тип. Это не просто некий неопределенный тип: netgraph имеет объектно-ориентированную архитектуру (в том количестве, насколько это необходимо в ядре и возможно на Си). В терминах ООП, каждый тип есть класс, наследующий от общего предка (поэтому все узлы имеют унаследованную возможность "иметь имя", например). Внутри тип есть просто таблица методов (указателей на функции), автору модуля достаточно не указывать свой собственный метод, чтобы унаследовать поведение по умолчанию. Каждый узел, соответственно, есть объект, instance класса, и в полном соответствии с принципом инкапсуляции ООП внутреннее состояние узла нельзя посмотреть - можно только спросить его самого об этом.
А вот тут, как и с полиморфизмом, начинаются вещи, непривычные для большинства сегодняшних пользователей ООП. Netgraph реализует ООП в изначальном, классическом смысле, как в Smalltalk (в современных и популярных так делают разве что в Ruby) - вместо вызовов методов делается посылка сообщений. В литературе их часто называют управляющими сообщениями, посвященный им раздел в мане по каждому узлу называется CONTROL MESSAGES. Почему так? Потому что в статическом OO-языке методы известны во время компиляции, в netgraph же заранее неизвестно, какие будут типы - система на ходу. Узел должен иметь возможность принять что угодно, а не только жестко заданные методы.
Сообщение есть просто заголовок и произвольная структура данных в качестве аргумента. Заголовок содержит имя сообщения, тип/семейство (так называемый cookie), длину аргументов, флаг того, является ли это сообщением ответом (reply control message) на другое. Имя и тип сообщения - просто числовые константы. Узел, получив сообщение, может вернуть либо одно число - код ошибки из стандартного набора errno(2) (ngctl напечатает тогда соответствующую строку), если он не умеет обрабатывать такое сообщение, или ему не понравился формат аргументов. Либо, если всё нормально, чуть позже узел посылает сообщение-ответ с необходимыми данными.
Подобным образом, сообщениями, реализовано вообще всё управление netgraph. Возможность адресации существует исключительно для посылки сообщений (в дополнение к стандартной отправке соседу вдоль хука). Сами команды ngctl в действительности почти все представляют собой отправку сообщений. Например, ngctl show отправляет указанному узлу сообщение NGM_LISTHOOKS. Он отвечает сообщением, в аргументе которого содержится список его хуков, который ngctl и печатает в красивом виде. Или соединить два узла (ngctl connect) - узлу посылается сообщения "соединись-ка ты с вон тем, сделав себе хук с именем X, а ему Y" - и тот послушно выпускает из себя хук и соединяется. Никаких специальных функций, всё средствами фреймворка же. Полный ООП.
Собственно, обработка этих стандартных сообщений, соответствующих командам ngctl, наследуется узлами от общего предка, в манах их называют generic control messages. Поскольку узлу никто не запрещает реализовать обработку каких угодно сообщений (обычно, по соглашению, он обрабатывает лишь сообщения со своим cookie), то возможен и своего рода полиморфизм, если узел обработает и какие-нибудь "чужие" сообщения (duck typing в Ruby или интерфейсы в Go). Некоторые узлы в базовой системе это используют.
В подзаголовке было еще слово "функциональный", как подчеркивалось в AANG. Да, здесь действительно есть параллели с функциональным программированием, но разве что отдаленные. Имелось в виду, что стиль работы узлов при получении пакета - прямой вызов функции-обработчика следующего узла, куда он передается по хуку (и сделан вызов будет в конце нашего обработчика, этакая хвостовая рекурсия). В наше время, с введением SMP, это уже не совсем так: нередко пакет ставится в очередь, чтобы избежать дедлоков. Так же на некоторых архитектурах есть эвристика, которая следит за использованием стека, при слишком большом числе вызовов тоже ставит пакет в очередь (а то будет еще Fatal trap 12). В остальных случаях да, для повышения скорости работы netgraph использует прямые вызовы функций.
Универсальный синтаксис: ng_parse()
Сообщения посылаются командой ngctl msg, и, как Вы уже, быть может, видели в примерах, там указываются вполне человекочитаемые строки, однако здесь и в манах речь идет о каких-то константах. Здесь скрывается одна из наиболее ярких особенностей netgraph, которую довольно скупо освещают в документации, а на русском языке я её описания вообще не видел (AANG дает очень краткий обзор для программиста и отсылает к исходному коду).
Напомню, netgraph (и его документация) был сделан прежде всего для программиста, и рассчитан для максимального его удобства. Когда узел получает управляющее сообщение, он получает его сразу в виде готовой Си-структуры. Никакого кода для парсинга строк, обработки конфигов, проверки на ошибки и т.д. - всё уже готово. Программисты оценят. В man-страницах, соответственно, приводятся константы и структуры из заголовочных файлов, вставляй в код и работай. Однако следом сразу же возникает вопрос, а как им тогда из командной строки управлять - на каждый чих писать и компилировать программу на Си, что ли? Для пользователя будет уже совсем неудобно. Ответом стало очень изящное решение, красивое как в идее, так и элегантное в реализации (одни виртуальные методы на Си-препроцессоре чего стоят) - предоставить средство для автоматического перевода бинарных Си-структур в человекочитаемую ASCII-форму и обратно.
Реализуется это так. Каждый узел в специальном виде описывает свои структуры для парсера. Потом пользователь дает ngctl нечто текстовое, предназначенное для узла. Поскольку ngctl не знает, что с этим делать, он посылает узлу сообщение NGM_ASCII2BINARY. Узел, в смысле определенных автором функций, тоже об этом ничего не знает - на сообщение отвечает унаследованный от фреймворка метод, который вызывает ng_parse() и отправляет ответ со структурой в бинарном виде (или ошибку). После чего ngctl полученное бинарное сообщение уже собственно шлет узлу. Если от него приходит ответ, то ngctl опять же не знает, как этот ответ показать пользователю, процедура повторяется сообщением NGM_BINARY2ASCII.
Итак, синтаксические правила (во многом напоминающие сам Си) такие:
- Пробелы, табуляции, переводы строк - разделители элементов, их может быть сколько угодно, или в некоторых случаях не быть вовсе.
- Integer-типы задаются обычными числами по основанию 8 (если начинается с 0), 10 или 16 (если начинается с 0x).
- Строки заключаются в двойные кавычки и поддерживают обычные escape-последовательности Си типа \r, \n, \012 и т.д.
- IP-адреса имеют очевидную форму.
- Массивы заключаются в квадратные скобки, элементы перечисляются последовательно, с нулевого индекса. Элемент опционально может иметь перед собой индекс и знак равенства (`='). Если у элемента индекс не указан явно, то его индекс равен индексу предыдущего плюс один.
- Структуры заключаются в фигурные скобки, каждое поле указывается в формате fieldname=value.
- Любой элемент массива или поле структуры, чье значение равно некоему "значению по умолчанию", может быть опущен (а на выходе из бинарного в текстовый вид - не будет выведен системой). Большинство авторов узлов не указывают фреймворку явно, что считать значением по умолчанию, и тогда "умолчания по умолчанию" считаются равными заполнению памяти двоичными нулями (т.е. не задают метод getDefault(), унаследованный же возвращает нули). Для чисел это означает нули, для IP-адресов 0.0.0.0, для строк - пустую строку.
- Элементы массивов и поля структур можно указывать в любом порядке.
Структуры:
'{' [ = ... ] '}'
Массивы:
'[' [ [index=] ... ] ']'
Думаю, не требуется пояснять, что, поскольку на выходе получаются структуры Си, то работают и правила Си, т.е. элементом массива может быть, например, структура, и т.д.
Пример (двоичные значения показаны для i386 с учетом выравнивания компилятором, пользователь может не заморачиваться, программисту же ясно, что фреймворк обрабатывает и это):
Структура Двоичное значение в памяти
--------- --------------------------
struct foo {
struct in_addr ip; 01 02 03 04
int bar; 00 00 00 00
char label[8]; 61 62 63 0a 00 00 00 00
u_char alen; 04 00
short ary[]; 05 00 00 00 0a 00 06 00
};
Значение в ASCII
----------------
{ ip=1.2.3.4 label="abc\n" alen=3 ary=[ 5 2=10 6 ] }
Обратите внимание на значения по умолчанию. Можно было написать "bar=0", но фреймворк автоматически выставил пропущенное значение в 0. В массиве ary элемент с индексом 0 имеет значение 5, а элемент с индексом 1 - нулевое (по умолчанию), и потому пропущен. Однако пропущенным он считается по причине того, что у следующего указан явный индекс 2 - если бы элементы были просто перечислены, логично, что они шли бы по порядку. Следом идет элемент со значением 6, индекс равен индексу предыдущего плюс один, т.е. 2+1=3. Можно было бы указать этот массив и как "ary=[ 5 0 0x0a 6 ]". Явное указание индексов удобно, если у Вас большие массивы, в основном пустые.
Чем удобно решение ng_parse() для пользователя, сравнительно с альтернативами? Синтаксис - единый, ничего не нужно учить для каждого типа узла. Они, конечно, различны, но это данные у них разные, а не язык. В то же время, типичный подход, к примеру, в Linux - создавать файлы в /proc. В этом случае каждому автору приходится заниматься не только "вклейкой" кода VFS, но и обработкой параметров вручную. В результате чего на каждый чих появляется свой новый синтаксис - если задача сложнее тривиального echo 1 >> /proc/..., конечно. Разумеется, в случае больших объемов данных или других сложных случаев и синтаксис ng_parse() станет неудобен - в таком случае пишется отдельная программа управления, например, mpd для своего вороха типов узлов, или ipacctctl для ng_ipacct.
Пример работы и использования документации
Что ж, выше было уже достаточно теории, чтобы можно было наконец перейти к практике. Получим навыки использования ngctl и man-cтраниц netgraph, реализовав на нем что-нибудь хорошо известное. Для такой задачи сгодится ng_nat(4).
Бегло просмотрев man, выясняется, что ng_nat сделан на базе той же библиотеки libalias, что и natd, а значит, применима вся имеющая информация по прохождению пакетов и конфигурированию natd. То есть, надо зарулить пакеты через ipfw. Секция SEE ALSO ссылается на ng_ipfw(4). Открываем его и узнаём из секции HOOKS, что нода разрешает любые имена хуков, при условии, что они числовые. "Напоминает номера divert-портов", - подумал Штирлиц. Дальше идет какая-то непонятная админу секция, явно для программистов. Единственный полезный вывод мы можем сделать только из её первого и последнего абзаца - во-первых, ноду просто так не создать, надо загрузить модуль ядра, во-вторых, пакеты ведут себя так же, как в случае divert: продолжают со следующего правила. Причем только такие пакеты, которые вышли из ng_ipfw - другие она выкинет. Секция SHUTDOWN, в отличие от многих других узлов, говорит, что ng_ipfw существует постоянно и не исчезает, если от него отключить все хуки. И вообще лучше её не гасить. OK, сделаем kldload ng_ipfw и вернемся к ману по ng_nat.
Из секции HOOKS узнаем, что хуков два - аналогичных ключам -i и -o у natd. Поскольку минимальная настройка NAT требует всего лишь указания интерфейса, нам хватит только одного управляющего сообщения: NGM_NAT_SET_IPADDR (setaliasaddr). Обратим внимание, что после значения константы в скобках приведено ASCII-имя сообщения. В некоторых man-страницах они отсутствуют: вероятно, приславших патчи с этими узлами авторов недостаточно шпыняли насчет качества документации. Что ж, таков опенсорс, здесь никто никому ничего не должен, но в подобных случаях всё же остается возможность посмотреть исходник...
Теги пакета
В AANG упоминалась структура ng_meta для передачи связанной с пакетом метаинформации. Это уже давно не актуально - вместо этого теперь во всей сетевой подсистеме FreeBSD применяются описанные в mbuf_tags(9) теги пакета. Нет, не надо путать их с VLAN-тегами. Те внутри пакета, mbuf-теги же прикреплены к нему снаружи, и используются в ядре для очень многих целей. Как, например, описано в man ng_ipfw. Теги mbuf применяются, в частности, для действий tag в pf и в ipfw, и надо подчеркнуть, что это НЕ те же самые теги, что у ng_ipfw, а другой подтип mbuf-тегов. Для обобщенного манипулирования mbuf-тегами (например, man по узлу может упоминать про теги) в netgraph существует ng_tag(4), хотя рядовому админу этот узел скорее всего понадобится только для проверки/навешивания ipfw tag.
Итак, запускаем ngctl, и на этот раз в интерактивном режиме. Поскольку оригинал каждый может посмотреть сам, я сделаю перевод вывода:
# ngctl
Доступные команды:
config Получить/установить конфигурацию узла по адресу "path"
connect Соединить хук "peerhook" узла по адресу "relpath" к хуку "hook"
debug Получить/установить уровень вывода отладочной информации
dot Выдать GraphViz (.dot) всего netgraph целиком.
help Показать этот список команд или справку по конкретной команде
list Показать список всех узлов
mkpeer Создать и присоединить новый узел к узлу по адресу "path"
msg Отправить управляющее сообщение узлу по адресу "path"
name Присвоить имя "name" узлу по адресу "path"
read Прочитать и выполнить команды ngctl из файла
rmhook Отсоединить хук "hook" от узла с адресом "path"
show Показать информацию об узле с адресом "path"
shutdown Погасить узел по адресу "path"
status Получить текстовый статус узла с адресом "path"
types Вывести информацию обо всех загруженных типах узлов
write Отправить пакет данных через хук "hook".
quit Выйти из программы
+ mkpeer ipfw: nat 60 out
+ name ipfw:60 nat
+ connect ipfw: nat: 61 in
+ msg nat: setaliasaddr 82.117.64.1
+ quit
# ipfw add 300 netgraph 61 all from any to any in via fxp0
# ipfw add 400 netgraph 60 all from any to any out via fxp0
# sysctl net.inet.ip.fw.one_pass=0
Всё, NAT настроен (последние 3 команды шеллу - это правила отправки трафика в netgraph и инструкция возвращать пакеты в ipfw обратно). Что отсюда очевидно? Что достаточно всего 4 команд ngctl для настройки, причем без name можно было и обойтись - именовали исключительно для удобства набора последующих команд (и доступа при последующих запусках). Более интересно, однако, то, что не очевидно сразу. Например, то, что в интерфейсе нет команды для просто создания узла - mkpeer обязательно соединяет его с каким-то уже существующим, то есть, требует его наличия. В нашем примере узел ipfw: уже существовал перед запуском ngctl, так же часто достаточно заранее существующих узлов ng_ether. Во всех остальных случаях конструирование графа придется начать с единственного доступного узла - созданного запущенным ngctl. И учитывать, что при выходе из ngctl этот узел и присоединенные к нему хуки - исчезнут (а многие узлы сами делают себе shutdown, если им оторвали все хуки). Поэтому многие вещи придется делать за один запуск ngctl (например, используя синтаксис < шелла, если не интерактивно), и даже тогда в некоторых случаях придется делать сборку схемы в определенном порядке или с использованием промежуточных узлов, которые потом будут убраны (например, если в планируемой схеме узлы поддерживают строго ограниченное число хуков). Некоторая информация по таким узлам будет дана позже.
Еще нужно пояснить некоторые команды из списка ngctl, которые могли кого-то заинтересовать. Команда status предназначена для получения информации о состоянии узла в произвольном текстовом (человекочитаемом) формате. В базовой системе её реализуют только некоторые узлы, главным образом, в подсистемах ATM, Bluetooth, а также ng_lmi и ng_cisco. Команда config задает конфигурацию узла, но реально в базовой системе поддерживается только драйвером mn(4) - потому что передается тоже в текстовом виде и требует парсинга самим узлом. Поэтому во всех остальных местах опираются ряд управляющих сообщений и ранее уже описанный ng_parse().
Вернемся к нему и мы, и к man-странице по ng_nat. Вот нам понадобился проброс портов. Что ж, читаем про сообщение NGM_NAT_REDIRECT_PORT и видим там структуру, говорящую нам, какие имена переменных следует использовать. Ба, да там еще и плюшка по сравнению с другим видами NAT обнаружилась - каждому пробросу можно задать до 64 символов описания текстом! Что ж, воспользуемся, и оформим команды шеллу красиво и читаемо:
# ngctl msg nat: redirectport '{
> alias_port=6881
> local_port=6881
> local_addr=192.168.4.4
> proto=6
> description="For uTorrent TCP"
> }'
Rec'd response "redirectport" (4) from "[33]:":
Args: 1
# ngctl msg nat: redirectport '{
> alias_port=6881
> local_port=6881
> local_addr=192.168.4.4
> proto=17
> description="For uTorrent UDP"
> }'
Rec'd response "redirectport" (4) from "[33]:":
Args: 2
На каждое сообщение узел немедленно отвечал каким-то числом. Как говорит man, это ID редиректа в списке, который потом можно пихать в другие сообщения. Посмотрим на этот список:
# ngctl msg nat: listredirects
Rec'd response "listredirects" (10) from "[33]:":
Args: { total_count=2 redirects=[ { id=1 local_addr=192.168.4.4 local_port=6881 alias_port=6881 proto=6 description="For uTorrent TCP" } { id=2 local_addr=192.168.4.4 local_port=6881 alias_port=6881 proto=17 description="For uTorrent UDP" } ] }
Итак, узел ответил структурой ng_nat_list_redirects, в которой, как говорит man, лежит количество элементов списка, и затем массив структур ng_nat_listrdrs_entry - в них, внутри квадратных и фигурных скобок, мы и наблюдаем те id, которыми узел отвечал при создании редиректов. Здесь следует обратить внимание на довольно часто используемый в netgraph прием, как при отдаче информации наружу, так и при конфигурировании пользователем - перед массивом структур лежит переменная, в которой указано число элементов в нём. Это важно: если какой-то узел принимает в конфигурации массив, придется посчитать их и сказать ему, сколько. Впрочем, это обычно несложно :)
Вывод отформатирован, к сожалению, не так красиво, но всё же еще читаемо. Зато это единственный NAT, который дает возможность править пробросы портов на ходу, без перезапуска. Не обязательно, конечно, пользоваться им, конфигурируя "от и до" самому: NAT в mpd сделан на базе именно этого узла, основную конфигурацию можно держать в конфиге mpd, и при необходимости чего-то нетривиального всё-таки иметь возможность это сделать.
Тем же, кому хочется вывод из ngctl "поудобнее", можно посоветовать вспомнить Unix way - текстовый вывод легко трансформировать командой ngctl msg nat: listredirects | tr -s '{}[]' ' \n\n ' | sed '1,2d;/^( )*$/d;s/Args...//g' (подойдет для любого вывода, не только для ng_nat).
Вместо заключения
Еще можно было бы рассказать об утилите nghook(8), служащей для подключения обычных pipeline'ов шелла к узлам netgraph. Но это слишком просто, так что она будет показана в составе примера, призванного продемонстривать, для каких неожиданных вещей может быть использован netgraph.
Допустим, есть такая задача: организовать вещание multimedia-потока на огромное количество клиентов, при условии, что multicast недоступен. Известно: типичный media stream устроен так, что его можно начать обрабатывать с любого места, клиент сам поймает синхронизацию. И серверу вещания более полезно занимать свой CPU непосредственно сжатием, а не обработкой клиентов (с чем он справляется хуже). Возникает идея сделать его бэкендом, а фронтендом поставить специальный прокси, который просто копирует клиентам поток. В простейшем случае по HTTP алгоритм работы таков: взять заголовки HTTP-запроса клиента, дать их серверу, запомнить HTTP-заголовки ответа, отдать клиенту (и отдавать их каждому новому клиенту), далее основной цикл - прочитать от бэкенда порцию, скопировать её в сокеты всем клиентам. С точки зрения highload здесь сразу видно три неоптимальные вещи:
- Данные копируются из ядра, а потом снова в ядро.
- Данные копируются много раз одни и те же.
- Каждый раз для этого происходит переключение контекста.
Решение ниже приведено как готовые скрипты для копипаста и проверено в работе на VLC, вещающем видео в MPEG-TS. Перед началом работы прицепимся к бэкенду и сохраним от него заголовки HTTP-ответа, которые потом отдавать клиентам:
# /usr/bin/printf "GET / HTTP/1.1\r\nRange: 0-\r\nIcy-MetaData: 1\r\n\r\n" | nc 10.0.0.4 19080 | dd of=http.reply count=2
Далее создадим и соединим сокет к бэкенду, а также хаб-разветвитель:
/usr/sbin/ngctl -f- <<-SEQ
mkpeer . hub tmp tmp
name .:tmp fanout
mkpeer fanout: ksocket up inet/stream/tcp
name fanout:up upstream
msg upstream: connect inet/10.0.0.4:19080
SEQ
/usr/bin/printf "GET / HTTP/1.1\r\nRange: bytes=0-\r\nIcy-MetaData: 1\r\n\r\n" | nghook fanout:
ngctl
mkpeer . ksocket listen inet/stream/tcp
name .:listen servsock
msg servsock: bind inet/0.0.0.0:8080
msg servsock: listen 64
msg servsock: accept
Как видно, ngctl запущен в интерактивном режиме (чтоб не шатдаунился слушающий сокет). Теперь ждем клиентов. Когда прицепится первый из них, ngctl напишет примерно такое:
Rec'd response "accept" (3) from "[13]:":
Args: { nodeid=0x1d addr={ len=16 family=2 data=[ 0x6 0xd 0xa 0x0 0x0 0x4 ] } }
На один accept создается только один соединенный узел ksocket, поэтому используем полученный номер (подставим в команды), присоединяя клиента к раздаче, а потом снова делаем accept, который будет ждать следующего (этот шаг повторяется столько, сколько клиентов):
mkpeer . tee l2r left2right
connect l2r [1d]: left ksockhook
write l2r -f http.reply
connect l2r fanout: right 0x1d
shutdown l2r
msg servsock: accept
Конечно, здесь лабораторные условия, для production-использования решение потребует доработки (отсутствует обработка ошибок, убивания отсоединенных сокетов, реконнект к бэкенду, flow control и т.д.), возможно, с написанием специализированного узла и/или демона. Но то уже рутина, а вот сколь велики возможности netgraph, видно очень хорошо.