Концепция построения IT-инфраструктуры.
Любая новая концепция основана на целостном взгляде на проблему. Она предлагает новый способ мышления, иерархию, где все разложено по полочкам. Решение повседневных проблем не должно проходить в суете и спешке. Как известно, для решения проблемы нужно выйти за пределы той парадигмы мышления, которая её породила. Т.е. Для решения нужно подняться на более высокий уровень мышления. Решать повседневные задачи, увязывая их с той концепцией, которая взята на вооружение.
Здесь я хочу отметить основные мысли и суть концепции построения ИТ-инфраструктуры.
Выделить то что вынес для себя. Чтобы не забыть.
Документ 2000 года, кое-какие названия уже устарели, местами я дополнил их современными аналогами.
Предложенный подход (www.infrastructures.org) предлагает смотреть на ИТ-инфраструктуру как на виртуальную машину. Единый организм, состоящий из множества процессоров, жестких дисков, памяти, периферийных устройств, сетевых сервисов и приложений. Каждый сервер независимо от его назначения является частью целого и рассматривается исключительно в контексте этого целого.
Взяв на вооружение эту философию, следует выстраивать свою работу по построению и администрированию ИТ-инфраструктуры в соответствии с концепцией виртуальной машины. В ней все узлы взаимозаменяемы, легкоуправляемы, унифицированы как по железу, так и по принципу управления. Для управления серверами и рабочими станциями применяются те же методы. Управление производится с одного центрального сервера (gold server). Сам по себе он тоже может выйти из строя, но работа системы при этом не нарушится. Мы разьве что лишимся возможности управлять инфраструктурой пока не восстановим точку управления.
Построение ИТ-инфраструктуры с нуля гораздо прощее и менее болезненно чем миграция уже существующей инфраструктуры на новую методологию.
Авторы концепции предложили перечень составляющих хорошей, масштабируемой ИТ-инфраструктуры и описали порядок внедрения составляющих, отметив его важность.
Вот эти составляющие:
1.Управление версиями. CVS, SVN, GIT. История изменения, возможность восстановления скриптов, программ, - всего того что является клеем для различных технологий и решений, применяемых при построении ИТ-инфраструктуры. Весь написанный код должен быть в репозитории.
2.Управляющий сервер. Все изменения в конфигурации производятся из одного места. Никаких ручных правок и настроек на других серверах и клиентских машинах. Изменения и обновления конфигурации берутся с этого узла.
3.Инсталляция новых хостов. Автоматическая установка ОС, настройка сервера/рабочей станции согласно роли без участия человека.
4.Инструменты для обновления и применения конфигурации. Не по расписанию, а по требованию. Возможность удаленного выполнения команд на узлах.
5.Служба каталога. DNS, NIS, LDAP. Единая система именования.
6.Сервер аутентификации - NIS, Kerberos. Пользователь должен иметь возможность войти в систему с любого компьютера. Попав в него, должен быть способен перемещаться внутри ИТ-инфраструктуры свободно согласно своим правам (принадлежности к группе).
7.Синхронизация времени - NTP. Важно для работы приложений, для резервного копирования.
8.Файловые серверы - NFS, AFS, SMB. Файловые хранилища, доступные для всех используемых ОС.
9.Резервное копирование (в оригинале File Replication Service - SUP, но это перекликается с п. 12).
10.Прозрачный доступ к файлам для клиента. Неважно с какой машины пользователь вошел в систему, он должен получить то же рабочее окружение со всеми файлами, программами, настройками, какие имел на прежнем рабочем месте. Automount, AMD, autolink.
11.Автообновление ОС на клиентах - rc.config, configure, make, cfengine.
12.Управление конфигурацией на клиентах. Cfengine, SUP, CVSup.
13.Управление приложениями на клиентах. Autosup, autolink.
14.Внутренняя почта - SMTP, POP, IMAP.
15.Сетевая печать. Linux/SMB. Независимо от клиентской ОС.
16.Мониторинг - syslogd, paging.
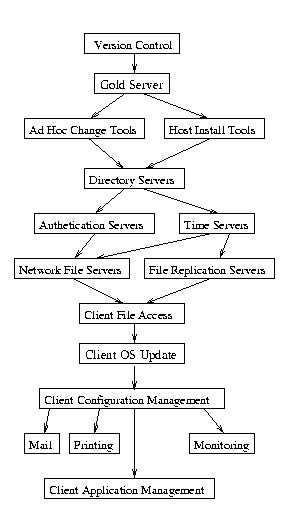
Последовательность внедрения компонентов ИТ-инфраструктуры.
При миграции с существующей инфраструктуры стоит подготовить вышеперечисленные ресурсы и переключать пользователей по одному. Сохранить все нужные данные, затем переналить машину, накатить конфигурацию и вернуть данные. Т.е. не переносить по файлу на каждом клиенте.
Восстановление после сбоев нужно продумать так, чтобы самый низкоквалифицированный сотрудник смог бы с нуля запустить любой из ресурсов ИТ-инфраструктуры.
Полезно при этом думать так: “Можно ли взять сейчас любой из компьютеров и выкинуть его с 10-ого этажа? Будет ли продолжать работать среда? Если ответ положительный, значит мы на верном пути”.
Как распространять изменения? Push vs. Pull. В первом случае центральный сервер инициирует отправку данных на клиентские машины. Во втором случае клиенты сами приходят за обновлениями к центральному серверу. Авторы приводят аргументы за второй способ, так как не нужно при этом заботиться о retry, timout, параллельном выполнении задач. В случайный момент времени по крайней мере один их клиентских хостов будет недоступен, придется обрабатывать подобные случаи в коде. Способ “pull” более прост в реализации, лучше масштабируется.
Великий смысл подобного рода концепций в том чтобы превратить работу системного администратора/архитектора инфраструктуры из кошмара в приятный, размеренный, предсказуемый и управляемый процесс. Чтобы человек проводил ночи и выходные не на работе, а дома.
Разница между системным администратором и архитектором инфраструктуры в том, что первые, как правило, не очень любят писать код. Они не боятся рутинных задач и дейсвтий.
Вторые же большую часть времени проводят за написанием кода, ненавидят делать одно и то же дважды, предпочитая автоматизировать работу.
Здесь я хочу отметить основные мысли и суть концепции построения ИТ-инфраструктуры.
Выделить то что вынес для себя. Чтобы не забыть.
Документ 2000 года, кое-какие названия уже устарели, местами я дополнил их современными аналогами.
Предложенный подход (www.infrastructures.org) предлагает смотреть на ИТ-инфраструктуру как на виртуальную машину. Единый организм, состоящий из множества процессоров, жестких дисков, памяти, периферийных устройств, сетевых сервисов и приложений. Каждый сервер независимо от его назначения является частью целого и рассматривается исключительно в контексте этого целого.
Взяв на вооружение эту философию, следует выстраивать свою работу по построению и администрированию ИТ-инфраструктуры в соответствии с концепцией виртуальной машины. В ней все узлы взаимозаменяемы, легкоуправляемы, унифицированы как по железу, так и по принципу управления. Для управления серверами и рабочими станциями применяются те же методы. Управление производится с одного центрального сервера (gold server). Сам по себе он тоже может выйти из строя, но работа системы при этом не нарушится. Мы разьве что лишимся возможности управлять инфраструктурой пока не восстановим точку управления.
Построение ИТ-инфраструктуры с нуля гораздо прощее и менее болезненно чем миграция уже существующей инфраструктуры на новую методологию.
Авторы концепции предложили перечень составляющих хорошей, масштабируемой ИТ-инфраструктуры и описали порядок внедрения составляющих, отметив его важность.
Вот эти составляющие:
1.Управление версиями. CVS, SVN, GIT. История изменения, возможность восстановления скриптов, программ, - всего того что является клеем для различных технологий и решений, применяемых при построении ИТ-инфраструктуры. Весь написанный код должен быть в репозитории.
2.Управляющий сервер. Все изменения в конфигурации производятся из одного места. Никаких ручных правок и настроек на других серверах и клиентских машинах. Изменения и обновления конфигурации берутся с этого узла.
3.Инсталляция новых хостов. Автоматическая установка ОС, настройка сервера/рабочей станции согласно роли без участия человека.
4.Инструменты для обновления и применения конфигурации. Не по расписанию, а по требованию. Возможность удаленного выполнения команд на узлах.
5.Служба каталога. DNS, NIS, LDAP. Единая система именования.
6.Сервер аутентификации - NIS, Kerberos. Пользователь должен иметь возможность войти в систему с любого компьютера. Попав в него, должен быть способен перемещаться внутри ИТ-инфраструктуры свободно согласно своим правам (принадлежности к группе).
7.Синхронизация времени - NTP. Важно для работы приложений, для резервного копирования.
8.Файловые серверы - NFS, AFS, SMB. Файловые хранилища, доступные для всех используемых ОС.
9.Резервное копирование (в оригинале File Replication Service - SUP, но это перекликается с п. 12).
10.Прозрачный доступ к файлам для клиента. Неважно с какой машины пользователь вошел в систему, он должен получить то же рабочее окружение со всеми файлами, программами, настройками, какие имел на прежнем рабочем месте. Automount, AMD, autolink.
11.Автообновление ОС на клиентах - rc.config, configure, make, cfengine.
12.Управление конфигурацией на клиентах. Cfengine, SUP, CVSup.
13.Управление приложениями на клиентах. Autosup, autolink.
14.Внутренняя почта - SMTP, POP, IMAP.
15.Сетевая печать. Linux/SMB. Независимо от клиентской ОС.
16.Мониторинг - syslogd, paging.
Последовательность внедрения компонентов ИТ-инфраструктуры.
При миграции с существующей инфраструктуры стоит подготовить вышеперечисленные ресурсы и переключать пользователей по одному. Сохранить все нужные данные, затем переналить машину, накатить конфигурацию и вернуть данные. Т.е. не переносить по файлу на каждом клиенте.
Восстановление после сбоев нужно продумать так, чтобы самый низкоквалифицированный сотрудник смог бы с нуля запустить любой из ресурсов ИТ-инфраструктуры.
Полезно при этом думать так: “Можно ли взять сейчас любой из компьютеров и выкинуть его с 10-ого этажа? Будет ли продолжать работать среда? Если ответ положительный, значит мы на верном пути”.
Как распространять изменения? Push vs. Pull. В первом случае центральный сервер инициирует отправку данных на клиентские машины. Во втором случае клиенты сами приходят за обновлениями к центральному серверу. Авторы приводят аргументы за второй способ, так как не нужно при этом заботиться о retry, timout, параллельном выполнении задач. В случайный момент времени по крайней мере один их клиентских хостов будет недоступен, придется обрабатывать подобные случаи в коде. Способ “pull” более прост в реализации, лучше масштабируется.
Великий смысл подобного рода концепций в том чтобы превратить работу системного администратора/архитектора инфраструктуры из кошмара в приятный, размеренный, предсказуемый и управляемый процесс. Чтобы человек проводил ночи и выходные не на работе, а дома.
Разница между системным администратором и архитектором инфраструктуры в том, что первые, как правило, не очень любят писать код. Они не боятся рутинных задач и дейсвтий.
Вторые же большую часть времени проводят за написанием кода, ненавидят делать одно и то же дважды, предпочитая автоматизировать работу.