Как можно использовать концепт TransTrance_Art не глобально,но окончательно для понимания чего-либо
В нижеприлагаемой статье сайта QUID о выборе Красного Вина мы видим, что TransTrance_Art, используя BIG DATA мог бы тоже предсказать лично Вам, читающему, все нужные Вам фильмы и книги планеты, все необходимые лично ВАМ отношения, опыты, приключения, людей, и Судьбу.
Как большие данные помогут вам выбрать лучшее вино
Тайлер Кнутсон
https://quid.com
05.30.2017
В 2011 году мой шурин продал мне половину случая 2007 года Pahlmeyer Napa Valley Prestige Red по цене - 480 долларов США, что значительно больше, чем когда-либо потраченное на вино. Это была моя первая красная смесь в стиле Бордо.
Как ни странно, для шести бутылок я был покрыт невероятными ароматами, которые доставили вино. Это мое любимое вино, и я (помилование каламбур) бесплодно искал что-то, что складывается с тех пор.
Проблема: выбор
Есть тысячи красных смесей в стиле Бордо на выбор, и мой личный опыт работы с двигателями рекомендаций для вина оставил желать лучшего. Таким образом, не понаслышке оглядываясь на тысячи обратных выпусков Wine Spectator, как мы можем:
В настоящее время на Wine.com существует более 5000 различных бутылок красных смесей в стиле Бордо. Вместо того, чтобы сегментировать эти вина, используя традиционные структурированные данные - например, цену, винтаж, винодельню, виноградную сортовую - что, если бы мы могли вместо этого полагаться на богатый, выразительный язык, используемый в описании продукта и обзорах экспертов, размещенных в Интернете?
Введите NLP (обработка естественного языка).
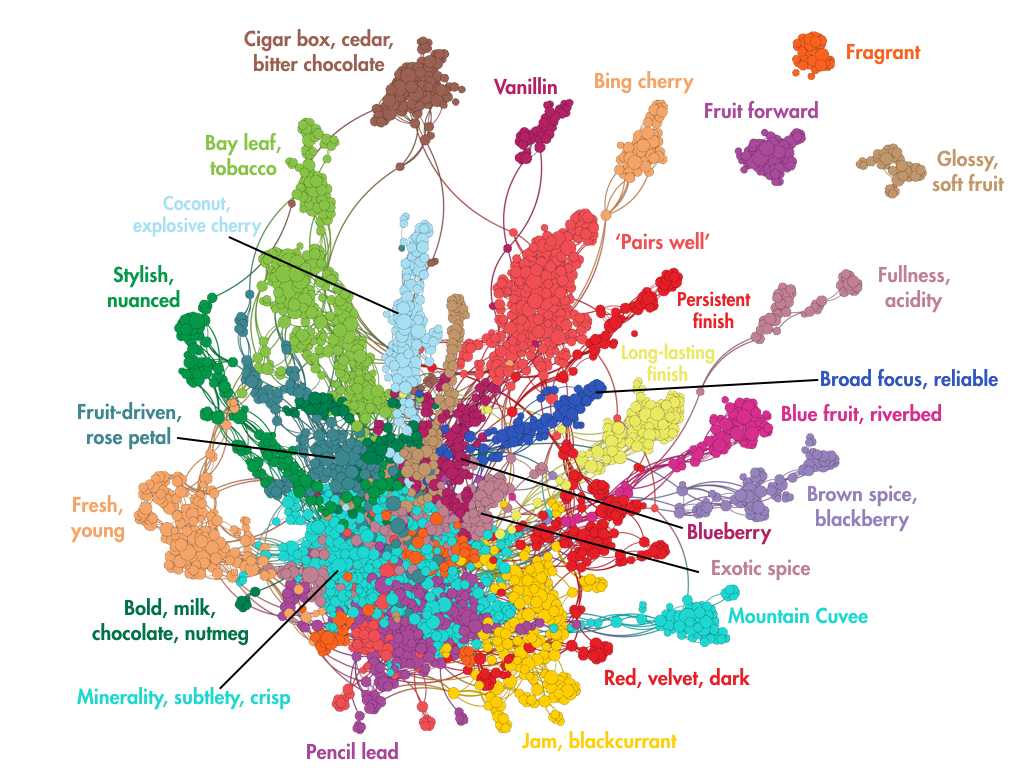
Сеть Quid показывает 3,380 узлов, где каждый узел представляет описание и обзор одной бутылки красного вина в стиле Бордо от Wine.com.Цвета представляют темы похожих вин, основанные на языке, используемом в этих описаниях.
Основные темы визуального выше включают как аромат (например, шоколад, взрывчатую вишню), так и стиль (например, тонкость, полноту), что указывает на значительную вариативность в том, как эти вина описаны в первую очередь.
Несколько вин соединяют несколько тем (так называемые «узлы моста»), что означает, что это может быть интригующим выбором, поскольку они демонстрируют доминирующие функции из более чем одного сегмента. Например, вам может быть интересно узнать о вине, соединяющем джем, черную смородину и экзотические сегменты специй.
В то время как смелые фрукты, такие как ежевика, голубика, смородина и вишня, в значительной степени представлены, более необычные вкусы, похоже, также играют определенную роль, например, лавровый лист, табак, шалфей и даже карандашный свинец.
Идеальная пара
Один кластер сосредоточил внимание на том, насколько хорошо некоторые вина сочетаются с пищей, а не с вкусовым профилем самого вина.

Этот кластер, ориентированный на спаривание вина с пищей, довольно плотный, что означает, что вина обычно ассоциируются с более чем одним предложением спаривания пищи. Другими словами, многие вина одинаковы и хорошо сочетаются с различными приемами пищи.
В этом случае меня больше всего интересуют уникальные вина на периферии. Лично я люблю рикотту и был рад видеть фанк-подгруппу, ориентированную на этот сыр. Хотя я никогда не слышал об этом раньше, Poggio al Tesoro Bolgheri Sondraia 2013 официально сделал мой список вин, чтобы попробовать на 2017 год.
Понимание винтажей
Какой язык используется для характеристики вина за каждый сезон?НЛП помогает нам понять наиболее важные ключевые слова для данного урожая и региона.

В представленном выше виде интересно заметить, что французские смеси часто описываются в абстрактных терминах, таких как «элегантный» и «шелковый», в то время как американские вина имеют тенденцию к конкретным ароматам, таким как «ежевика» и «вишня». Мне также любопытно, что Юг Американские смеси довольно последовательно демонстрируют аромат ванили, в то время как другие регионы, по-видимому, имеют больший диапазон. Итальянские смеси также кажутся уникальными в том, что они чередуются между дескрипторами вкуса и стиля, демонстрируя отличительные вкусы, такие как «кофе» и «мята».
В то время как поиск по регионам дает широкое представление, изучение самого верхнего описательного термина само по себе не соответствует нюансам, которые я ищу. Давайте копаем глубже только в красные смеси Калифорнии.
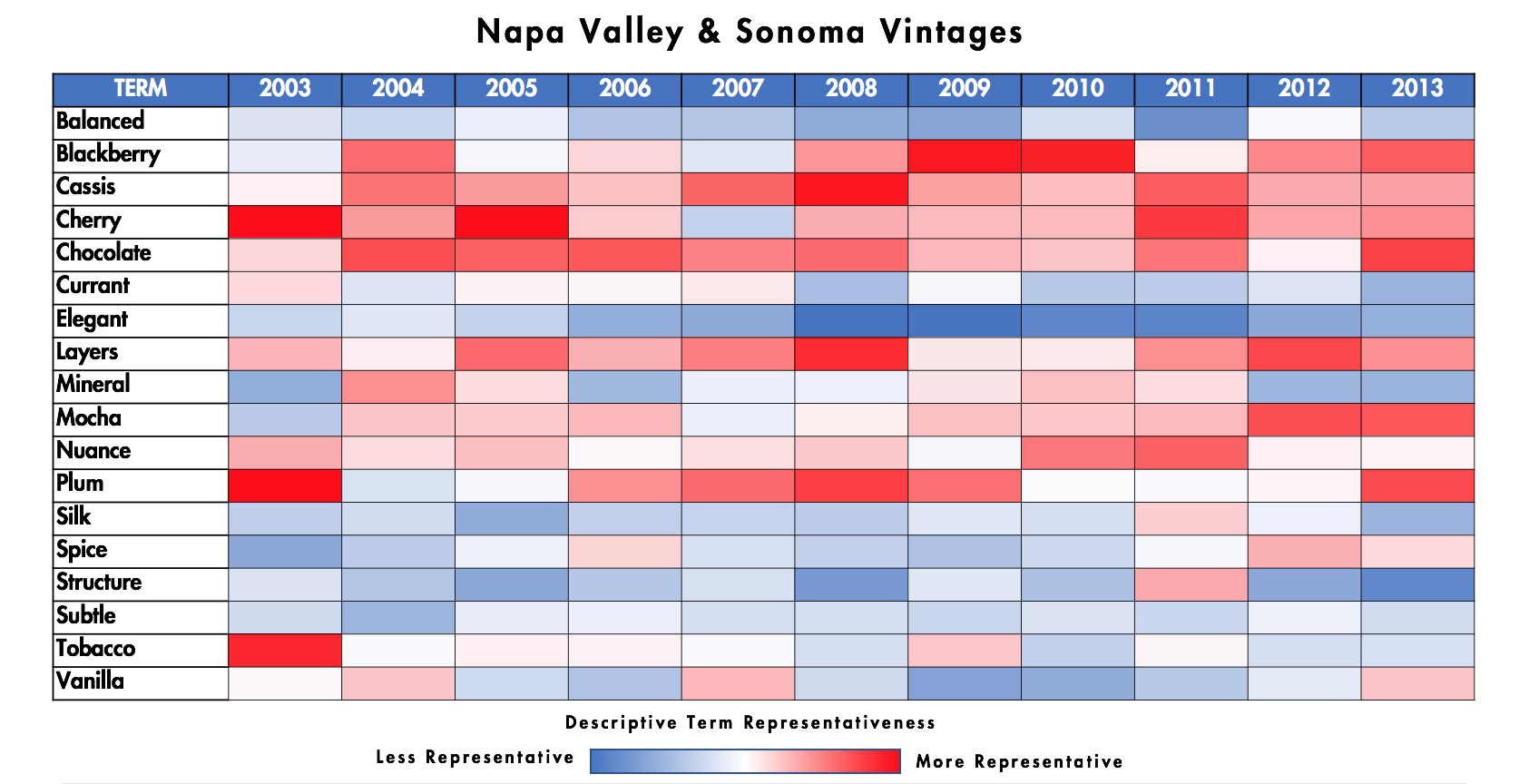
Здесь мы можем начать видеть истинную силу НЛП, примененную к вину. С первого взгляда я могу узнать, что в Напа и Сонома:
Это показывает один из способов применения больших данных и методов машинного обучения к вину и узнать больше о вашем собственном вкусовом профиле и почему вам нравится то, что вам нравится, независимо от мнения экспертов.
Выбор победителей
С NLP мы можем напрямую идентифицировать вина, наиболее похожие на вина, которые мы уже знаем, являются фаворитами. Другими словами, чем больше сходство в используемом языке, тем более вероятно, что два вина должны иметь связи друг с другом.
Существующие подходы к рекомендации по использованию вина сосредоточены на структурированных данных, то есть, как вы уже оценили определенные винтажи, регионы и сорта. Проблема с этой тактикой заключается в том, что в этих измерениях слишком много различий, то есть у нас нет данных, достаточно гранулированных, чтобы последовательно делать точный прогноз.
Если бы эти структурированные данные были достаточными, импликация заключалась бы в том, что все винограды в данном регионе за данный год (более или менее) создаются равными. Спросите любого сомелье, если это предположение держится и подготовиться к страстной лекции.
Из 11 красных смесей, которые я оценил 4+ звезд в приложении Vivino, Quid смог идентифицировать 73 ассоциированных вина, основанных исключительно на сходстве используемого языка.
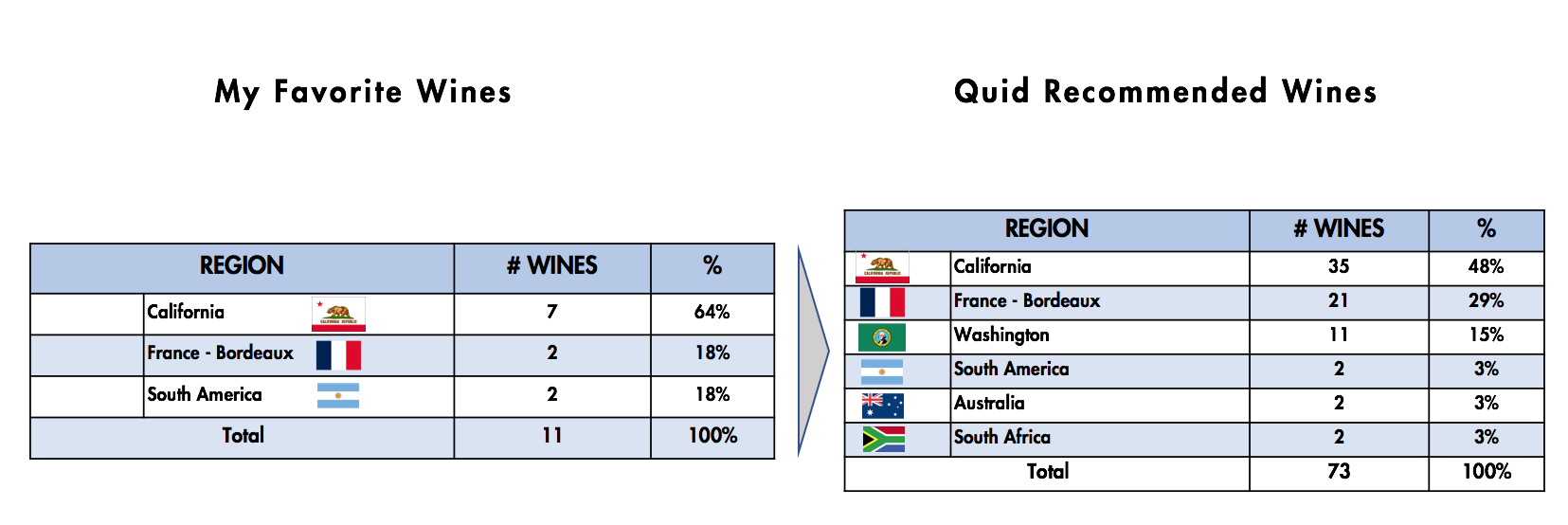
Поскольку этот подход учитывает только язык, алгоритмы Quid рекомендовали для меня различные регионы, а не только три, которые я вводил в качестве данных обучения.
Ниже приводится подмножество этих рекомендуемых вин (со средней ценой менее 500 долларов США).
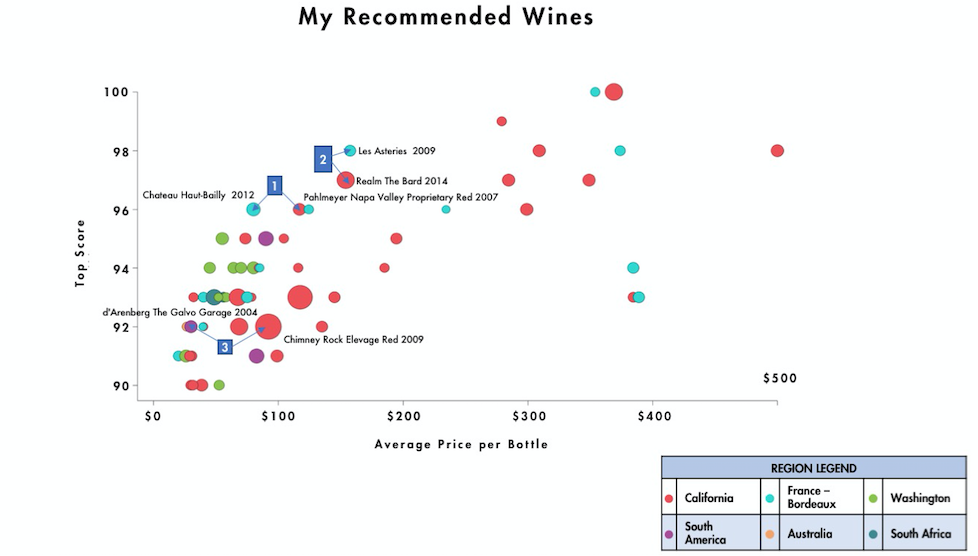
В то время как любой человек в индустрии продуктов питания и напитков может сказать вам, что оценка вина часто ошибочна, давайте предположим, что это реалистичный прокси для качества.Использование вышеприведенного вывода было бы одним из возможных способов определить приоритет этого списка из 73 вин, которые нужно попробовать.
Например: я знаю, что мне нравится «Палмейер», но есть более доступный «12 Chateau Haut-Bailly», который также набрал 96 очков.
'14 Realm the Bard был потрясающим, но я не слышал о '09 Les Asteries, который получил более высокий балл по аналогичной цене. Chimney Rock - это, безусловно, домашнее имя и чрезвычайно представитель сегмента Minerality, Subtlety, Crisp, но меня интересует 2004 d'Arenberg с аналогичным результатом, который является более периферийным и, возможно, уникальным в своем урожае.
То, что я больше всего ценю в этом подходе, заключается в том, что он слеп к чему-либо, кроме описательного языка, то есть мы получаем рекомендации, основанные на том, что такое вино, а не на том, где оно, из винограда, или было слишком дождливо в этом году.
Коммерческие последствия
Существует множество способов использовать НЛП в сочетании с традиционными структурированными данными, чтобы резко нарушить то, как мы думаем о вине.
1. Во-первых, в выборе потребительского вина. Представьте, что подход автоматического горного языка схожесть применяется не только к описаниям продуктов, но и ко всей вселенной отзывов Vivino, чтобы давать рекомендации - включение данных языка может добавить к этой платформе серьезные мощности. Было бы также интересно представить всю винный список ресторана в качестве языковой сети и использовать его, чтобы помочь посетителям исследовать выбор по-новому перед едой.
И, конечно же, подход может применяться к более чем вину. Вы можете использовать эту же методологию для просмотра шаблонов в любых данных, от обзоров до обзоров продуктов.
2. Маркетинговая информация: как описания и вкусы коррелируют с поведением покупателей? Как это меняется со временем и какие сообщения резонируют? НЛП может быть практическим инструментом для маркетологов продуктов питания и напитков, когда они используются таким образом, особенно в винодельнях, которые в значительной степени полагаются на кампании прямого потребителя.
3. Направленные дегустации вин: что, если мы можем добавить визуальные данные, чтобы помочь людям понять больше о том, что они дегустируют, и сделать его более вероятным для запоминания данной марки? Продажи представителей дистрибьюторов, которые проводят дегустации в винных магазинах и магазинах спиртных напитков, могут использовать планшеты с предварительно загруженными данными, чтобы визуально объяснить, что дегустация людей и как их вина относятся к другим винам, с которыми клиент уже может быть знаком.
Глядя на один стиль вина, он служит практическим прецедентом для этого подхода, но я взволнован возможностью распространения этого анализа на несколько сортов. Может быть, тогда я мог бы объяснить использование данных, почему 9 из 10 слепых дегустаторов ошибочно идентифицируют Шато-де-ла-Гардин в 2014 году как красный, а не белый (виноватый).
В любом случае у меня теперь есть 73 новых элемента в моем списке дел. Салюд.
Ключевые слова: Вино , Обзоры , Nlp , Бордо
Как большие данные помогут вам выбрать лучшее вино
Тайлер Кнутсон
https://quid.com
05.30.2017
В 2011 году мой шурин продал мне половину случая 2007 года Pahlmeyer Napa Valley Prestige Red по цене - 480 долларов США, что значительно больше, чем когда-либо потраченное на вино. Это была моя первая красная смесь в стиле Бордо.
Как ни странно, для шести бутылок я был покрыт невероятными ароматами, которые доставили вино. Это мое любимое вино, и я (помилование каламбур) бесплодно искал что-то, что складывается с тех пор.
Проблема: выбор
Есть тысячи красных смесей в стиле Бордо на выбор, и мой личный опыт работы с двигателями рекомендаций для вина оставил желать лучшего. Таким образом, не понаслышке оглядываясь на тысячи обратных выпусков Wine Spectator, как мы можем:
Примените новый подход к классификации вина?
Быстро узнать отличительные черты данного урожая по регионам?
Оптимизируйте выбор вин и выберите победителя, который может находиться под радаром?
В настоящее время на Wine.com существует более 5000 различных бутылок красных смесей в стиле Бордо. Вместо того, чтобы сегментировать эти вина, используя традиционные структурированные данные - например, цену, винтаж, винодельню, виноградную сортовую - что, если бы мы могли вместо этого полагаться на богатый, выразительный язык, используемый в описании продукта и обзорах экспертов, размещенных в Интернете?
Введите NLP (обработка естественного языка).
Сеть Quid показывает 3,380 узлов, где каждый узел представляет описание и обзор одной бутылки красного вина в стиле Бордо от Wine.com.Цвета представляют темы похожих вин, основанные на языке, используемом в этих описаниях.
Основные темы визуального выше включают как аромат (например, шоколад, взрывчатую вишню), так и стиль (например, тонкость, полноту), что указывает на значительную вариативность в том, как эти вина описаны в первую очередь.
Несколько вин соединяют несколько тем (так называемые «узлы моста»), что означает, что это может быть интригующим выбором, поскольку они демонстрируют доминирующие функции из более чем одного сегмента. Например, вам может быть интересно узнать о вине, соединяющем джем, черную смородину и экзотические сегменты специй.
В то время как смелые фрукты, такие как ежевика, голубика, смородина и вишня, в значительной степени представлены, более необычные вкусы, похоже, также играют определенную роль, например, лавровый лист, табак, шалфей и даже карандашный свинец.
Идеальная пара
Один кластер сосредоточил внимание на том, насколько хорошо некоторые вина сочетаются с пищей, а не с вкусовым профилем самого вина.
Этот кластер, ориентированный на спаривание вина с пищей, довольно плотный, что означает, что вина обычно ассоциируются с более чем одним предложением спаривания пищи. Другими словами, многие вина одинаковы и хорошо сочетаются с различными приемами пищи.
В этом случае меня больше всего интересуют уникальные вина на периферии. Лично я люблю рикотту и был рад видеть фанк-подгруппу, ориентированную на этот сыр. Хотя я никогда не слышал об этом раньше, Poggio al Tesoro Bolgheri Sondraia 2013 официально сделал мой список вин, чтобы попробовать на 2017 год.
Понимание винтажей
Какой язык используется для характеристики вина за каждый сезон?НЛП помогает нам понять наиболее важные ключевые слова для данного урожая и региона.
В представленном выше виде интересно заметить, что французские смеси часто описываются в абстрактных терминах, таких как «элегантный» и «шелковый», в то время как американские вина имеют тенденцию к конкретным ароматам, таким как «ежевика» и «вишня». Мне также любопытно, что Юг Американские смеси довольно последовательно демонстрируют аромат ванили, в то время как другие регионы, по-видимому, имеют больший диапазон. Итальянские смеси также кажутся уникальными в том, что они чередуются между дескрипторами вкуса и стиля, демонстрируя отличительные вкусы, такие как «кофе» и «мята».
В то время как поиск по регионам дает широкое представление, изучение самого верхнего описательного термина само по себе не соответствует нюансам, которые я ищу. Давайте копаем глубже только в красные смеси Калифорнии.
Здесь мы можем начать видеть истинную силу НЛП, примененную к вину. С первого взгляда я могу узнать, что в Напа и Сонома:
«Cassis», «Blackberry» и «Chocolate» удивительно характерны для красных смесей в течение многих лет.
С другой стороны, «Элегантный» и «Сбалансированный», вероятно, зарезервированы для французских смесей и редко используются здесь.
2003 год был странным годом, с несколькими упоминаниями о «табачных» ароматах относительно других вин.
2011 год был уникальным, единственный винтаж с высокой степенью «шелкового» и «структурного» языка - очень нехарактерный для этого региона
Мой любимый винтаж (2007) характеризуется «Cassis», «Шоколад», «Слои», «Слива» и «Ваниль».
Это показывает один из способов применения больших данных и методов машинного обучения к вину и узнать больше о вашем собственном вкусовом профиле и почему вам нравится то, что вам нравится, независимо от мнения экспертов.
Выбор победителей
С NLP мы можем напрямую идентифицировать вина, наиболее похожие на вина, которые мы уже знаем, являются фаворитами. Другими словами, чем больше сходство в используемом языке, тем более вероятно, что два вина должны иметь связи друг с другом.
Существующие подходы к рекомендации по использованию вина сосредоточены на структурированных данных, то есть, как вы уже оценили определенные винтажи, регионы и сорта. Проблема с этой тактикой заключается в том, что в этих измерениях слишком много различий, то есть у нас нет данных, достаточно гранулированных, чтобы последовательно делать точный прогноз.
Если бы эти структурированные данные были достаточными, импликация заключалась бы в том, что все винограды в данном регионе за данный год (более или менее) создаются равными. Спросите любого сомелье, если это предположение держится и подготовиться к страстной лекции.
Из 11 красных смесей, которые я оценил 4+ звезд в приложении Vivino, Quid смог идентифицировать 73 ассоциированных вина, основанных исключительно на сходстве используемого языка.
Поскольку этот подход учитывает только язык, алгоритмы Quid рекомендовали для меня различные регионы, а не только три, которые я вводил в качестве данных обучения.
Ниже приводится подмножество этих рекомендуемых вин (со средней ценой менее 500 долларов США).
В то время как любой человек в индустрии продуктов питания и напитков может сказать вам, что оценка вина часто ошибочна, давайте предположим, что это реалистичный прокси для качества.Использование вышеприведенного вывода было бы одним из возможных способов определить приоритет этого списка из 73 вин, которые нужно попробовать.
Например: я знаю, что мне нравится «Палмейер», но есть более доступный «12 Chateau Haut-Bailly», который также набрал 96 очков.
'14 Realm the Bard был потрясающим, но я не слышал о '09 Les Asteries, который получил более высокий балл по аналогичной цене. Chimney Rock - это, безусловно, домашнее имя и чрезвычайно представитель сегмента Minerality, Subtlety, Crisp, но меня интересует 2004 d'Arenberg с аналогичным результатом, который является более периферийным и, возможно, уникальным в своем урожае.
То, что я больше всего ценю в этом подходе, заключается в том, что он слеп к чему-либо, кроме описательного языка, то есть мы получаем рекомендации, основанные на том, что такое вино, а не на том, где оно, из винограда, или было слишком дождливо в этом году.
Коммерческие последствия
Существует множество способов использовать НЛП в сочетании с традиционными структурированными данными, чтобы резко нарушить то, как мы думаем о вине.
1. Во-первых, в выборе потребительского вина. Представьте, что подход автоматического горного языка схожесть применяется не только к описаниям продуктов, но и ко всей вселенной отзывов Vivino, чтобы давать рекомендации - включение данных языка может добавить к этой платформе серьезные мощности. Было бы также интересно представить всю винный список ресторана в качестве языковой сети и использовать его, чтобы помочь посетителям исследовать выбор по-новому перед едой.
И, конечно же, подход может применяться к более чем вину. Вы можете использовать эту же методологию для просмотра шаблонов в любых данных, от обзоров до обзоров продуктов.
2. Маркетинговая информация: как описания и вкусы коррелируют с поведением покупателей? Как это меняется со временем и какие сообщения резонируют? НЛП может быть практическим инструментом для маркетологов продуктов питания и напитков, когда они используются таким образом, особенно в винодельнях, которые в значительной степени полагаются на кампании прямого потребителя.
3. Направленные дегустации вин: что, если мы можем добавить визуальные данные, чтобы помочь людям понять больше о том, что они дегустируют, и сделать его более вероятным для запоминания данной марки? Продажи представителей дистрибьюторов, которые проводят дегустации в винных магазинах и магазинах спиртных напитков, могут использовать планшеты с предварительно загруженными данными, чтобы визуально объяснить, что дегустация людей и как их вина относятся к другим винам, с которыми клиент уже может быть знаком.
Глядя на один стиль вина, он служит практическим прецедентом для этого подхода, но я взволнован возможностью распространения этого анализа на несколько сортов. Может быть, тогда я мог бы объяснить использование данных, почему 9 из 10 слепых дегустаторов ошибочно идентифицируют Шато-де-ла-Гардин в 2014 году как красный, а не белый (виноватый).
В любом случае у меня теперь есть 73 новых элемента в моем списке дел. Салюд.
Ключевые слова: Вино , Обзоры , Nlp , Бордо