"python" challenge
Ganked from memepool, someone has a puzzle that they intend to be solved with python. Being a geek but not python fan (I don't dislike python, just haven't found a good reason to learn it yet), I thought I'd try to solve it otherwise.
- 2 to the 38. Compute using bc command-line calculator:
$ echo '2^38' | bc 274877906944
- I'm not sure exactly what they meant by "think twice",
but it's a simple "rot2" cipher. We can use tr
program for this:
$ tr 'a-z' 'c-za-b' g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj. i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url. pc/def/map.html re/fgh/ocr.jvon
Annoyingly, the only part of the url they actually wanted you to change was "map" to "ocr". Not at all obvious when they say "the url". (It didn't help that there's a snotty response if you try "ocr.jvon".)
- There is a bunch of noise in a comment in the source, and
we're supposed to find the rare characters. We need to
count character frequency; absent any obvious dedicated
command, I break out the
swiss army chainsaw:
perl -nlwe 'foreach (split //) { ++$h{$_} } END { while ( ($c, $n) = each %h ) { print "$n\t$c" } }' | \ sort +0nr
(I consciously decided not to use the perl built-in sort operator; sorting hash keys by value is a bit messy, and it was faster to type the [old-fashioned] sort command-line.) This gave me these results:
6186 ) 6157 @ 6154 ( 6152 ] 6115 # 6112 _ 6108 [ 6105 } 6104 % 6079 ! 6066 + 6046 { 6046 $ 6043 & 6034 * 6030 ^ 1 a 1 e 1 i 1 l 1 q 1 t 1 u 1 y
Now we use tr again to nuke all but those rare characters...
$ tr -d -c 'aeilqtuy' [paste blob of source here] equality
- Another needle-in-the-haystack-of-comment problem.
And again, I'll use perl:
$ perl -lnwe 'while (/[a-z][A-Z]{3}([a-z])[A-Z]{3}[a-z]/g) { $s .= $1 } END { print $s }' [paste blob of source here] linkedlist
Quite a few false starts here: first, I thought it had to be three identical guards, or at least the same three on each side. Also, the "exactly" is important. Don't quite understand why the next stage is a PHP file...
- Oh. Because the next one is a dynamic puzzle. The suggestion
in the source file is to use python's urllib. Bah!
$ n=33110 $ url='http://www.pythonchallenge.com/pc/def/linkedlist.php' $ while true; do n2=$( wget -q -O - "$url?nothing=$n" | \ sed -r -e 's/.*the next nothing is ([0-9]+)/\1/' | \ egrep '^[0-9]+$' ) echo "$n -> $n2" n=$n2 sleep 1 done
This one took a lot of babysitting, and I likely would have finished it much easier had I resorted to just perl instead of sed. Oh well; I'm still solving it with [mostly] descrete tools.
I also didn't know what the point was; I just let it iterate until something bad happened, at which point I would look at the site manually and figure out what had to be done. Once, they threw in extra numbers (which broke the iteration, so I caught it); another time, there are textual instructions, which I just executed manually and restarted the iteration.
Finally, I didn't even think before putting in a delay in that loop; it's just second nature. I originally had 5 seconds, but since the hint warned that there could be as many as 300 iterations, I dropped it to one. Wonder how many novice python programmers hammered the hell out of that server, tho. :)
- Ok, first one that actually requires python,
as it is based on their "pickle" object serialization
protocol:
$ python -c 'import pickle; print pickle.load( file( "banner.p" ) )' [[(' ', 95)], [(' ', 14), ... ('#', 6)], [(' ', 95)]]
So it's a run-length-encoded banner.
Loathe languages that insist on protecting you from yourself. Case in point, there's no way (that I could see) to do this on one line in python:
$ python -c 'import pickle; for l in pickle.load( file( "banner.p" ) ): t="" for s in l: t = t + s[0]*s[1] print t' ##### ##### #### #### #### #### #### #### #### #### #### #### #### #### #### #### ### #### ### ### ##### ### ##### ### ### #### ### ## #### ####### ## ### #### ####### #### ####### ### ### #### ### ### ##### #### ### #### ##### #### ##### #### ### ### #### ### #### #### ### ### #### #### #### #### ### #### #### ### #### #### ### #### #### #### #### ### ### #### #### #### #### ## ### #### #### #### #### #### ### #### #### #### #### ########## #### #### #### #### ############## #### #### #### #### ### #### #### #### #### #### #### #### #### #### #### #### ### #### #### #### #### #### #### ### #### #### #### ### #### #### #### #### ### #### ### ## #### #### ### #### #### #### #### #### ### ## #### ### ## #### #### ########### #### #### #### #### ### ## #### ### ###### ##### ## #### ###### ########### ##### ### ######
Just because it's annoyed me, I'll do that post-processing in perl:
$ python -c 'import pickle; print pickle.load( file( "banner.p" ) )' | \ perl -nwe 'tr/()/[]/; for $l ( @{ eval $_ } ) { for $s ( @$l ) { print $s->[0] x $s->[1]; } print "\n" }'
And to really abuse things, a purely textual manipulation of the RLE data:
$ python -c 'import pickle; print pickle.load( file( "banner.p" ) )' | \ perl -pwe 's/\[//g; s/\(\047(.)\047, (\d+)\)/"$1" x $2/eg; s/\]/\n/g; s/, //g'
Yes, both of those are longer than the equivalent python, but hey, at least perl lets me put it all one one line.
- There's a "channel.zip" file with a bunch of numbered files in it.
Similar to the previous "follow the chain", I expect. I unzip all
the files into a directory and then:
n=90052; while [ -e $n.txt ] do n2=$( perl -nlwe 'print $1 if /next nothing is (\d+)/i' $n.txt ) echo "$n -> $n2" n=$n2 done
But the last one in the chain says "collect the comments". The individual files have no comments, and there's a hint that the answer is in the zip. Hm... Only oddity so far is that all the files are dated 2006-06-06 06:06:06 local time. Ok, there are comments on each one, and zipinfo is being a bitch about displaying them (the "-z" option is supposed to, but it doesn't seem to be working.)
$ zipinfo -v channel.zip | \ perl -lnwe '$s .= $_ if $i; $i = /file comment begins/; END { print $s }'
But the output from that is gibberish. Hmm... 910 files, so maybe 10 lines of 91 each? Just looking at the letters, I eventually figured out it was oxygen. No idea how that is supposed to be self-evident, though. Did try reformatting:
$ ( for w in $( seq 50 200 ) do echo "=== $w ===" split -b $w gag.txt gag. for f in gag.?? ; do cat $f ; echo ; done rm gag.?? done ) > foobar.txt
I wonder if you have to reorder the comments according to their name or the order in the zip file. Huh. *shrug* oh well, I have the answer to get to the next stage...
- This is a png image with one grey bar in it. Looking at it with
gimp, it seems that those grey values are right around
uppercase ascii...
$ pngtopnm oxygen.png | \ dd bs=1 skip=$((15+629*3*50)) count=$((629*3)) | \ perl -plwe 's/(.){21}/$1/g; s/\].*$/]/' | \ perl -lnwe 'print map chr($_), split /\D+/'
The two invocations of perl is just how I evolved the command -- remove the last bit to see what the first hidden message is.
- Ok, the "hide crap in the page source" trick got old a few screens
ago. The comments have two bzip2 strings in them (the BZ gave
that away), which are the username/password to get through the
map. I resorted to using perl to translate the \xHH characters to
their binary equivalents. Only hiccup was having to backwhack
some dollar signs in the second one.
$ perl -we 'print "BZh91AY ..."' | bzip2 -dc ; echo
username "huge", password "file".
- More data hidden in the HTML. Whee. XY data this time. I use
perl to massage it, then gnuplot to plot it:
$ wget --http-user=huge --http-passwd=file \ http://www.pythonchallenge.com/pc/return/good.html $ perl -nlwe 'if ( /first:/ .. /second:/ ) { $s .= $_ } END { $s =~ s/\s+//g; while ( $s =~ /(\d+),(\d+)/g ) { print "$1\t$2" } }' \ good.html > good1.txt $ perl -nlwe 'if ( /second:/ .. 0 ) { $s .= $_ } END { $s =~ s/\s+//g; while ( $s =~ /(\d+),(\d+)/g ) { print "$1\t$2" } }' \ good.html > good2.txt $ echo -e "plot 'good1.txt', 'good2.txt'\npause 10" | gnuplot -
Which renders to something like this: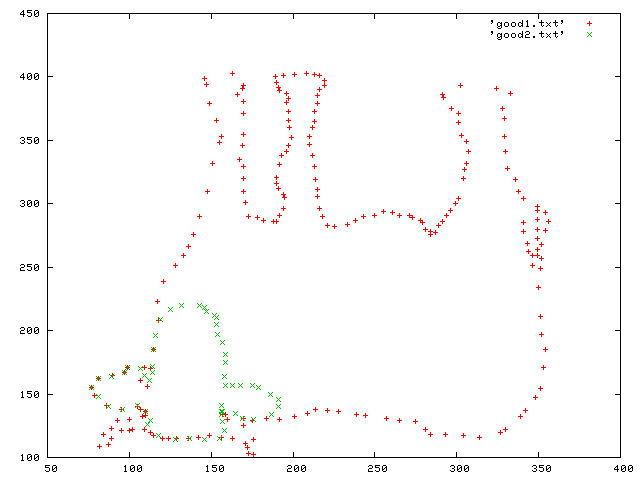
- This is the
look and say sequence, popularized by John Conway.
$ perl -lwe '$s = "1"; for $i ( 1 .. 30 ) { $s2 = ""; $l = 0; while ( $s =~ /((.)\2*)/g ) { $s2 .= length($1) . $2; $l += 2 } print "$i: $s2 ($l)"; $s = $s2 }'
Took me a minute or two to think of the proper regex, but other than that, it was straightforward. You might want to skip printing the actual sequence -- it gets pretty large.
The MathWorld article above indicates that there is an asymptotic formula for the length. Unfortunately, the proportionality constant they give is not quite accurate enough for our purposes; the formula overestimates the number by 3.mumble:
$ echo '1.567*(1.303577269034296^31)' | bc 5811.779683986696858
- The graphic has some very subtle detail that is obscured by the
much brighter picture. I used perl to build a mask, then loaded
it into The Gimp to mask off the brighter picture. (This should
have been possible with just the command-line netpbm tools, but
apparently I'm tickling a bug in them.)
print "P1\n", "640 480\n"; my $odd = ( "0 1 " x 16 . "\n" ) x 20; my $even = ( "1 0 " x 16 . "\n" ) x 20; for ( 1 .. 240 ) { print $odd, $even }
- Ok, this one has me stumped. Time to post...
Yay for drinking too much too early in the evening, so now I'm awake, with a slight headache, and feeling just blah.