Кластеризация memcached и выбор ключа кэширования
Запись опубликована Блог Андрея Смирнова. Пожалуйста, оставляйте комментарии там.
Серия постов про “Web, кэширование и memcached” продолжается. В первом посте мы поговорили о memcached, его архитектуре и возможном применении.
Сегодня речь пойдет о:
- выборе ключа кэширования;
- кластеризации memcached и алгоритмах распределения ключей.

Следующий пост будет посвящен атомарности операций и счетчикам в memcached.
Ключ кэширования
Пусть мы уже убедились, что использовать memcached для кэширования - это правильное решение. Первая задача, которая перед нами встаёт - это выбор ключа для каждого кэша. Ключом в memcached является строка ограниченной длины, состоящая из ограниченного набора символов (например, запрещены пробелы). Ключ кэширования должен обладать следующими свойствами:
- При изменении параметров выборки, которую мы кэшируем, ключ кэширования должен изменяться (чтобы с новыми параметрами мы не «попали» в старый кэш).
- По параметрам выборки ключ должен определяться однозначно, т.е. для одной и той же выборки ключ кэширования должен быть только один, иначе мы рискуем понизить эффективность процесса кэширования.
Конечно, мы могли бы для каждой выборки строить ключ самостоятельно, например, ‘user_158’ для выборки информации о пользователе с ID 158 или ‘friends_192_public_sorted_online’ для друзей пользователя с ID 192, которые доступно публично и притом отсортированы в порядке последнего появления на сайте. Такой подход чреват ошибками и несоблюдением условий, сформулированных выше.
Можно использовать следующий вариант (пример для PHP): если существует некоторая точка в коде, через которую проходят все обращения к БД, а любое обращение полностью описывается (содержит все параметры запроса) в некоторой структуре $options, можно использовать следующий ключ:
$key = md5(serialize($options))
Такой ключ несомненно удовлетворяет первому условию (при изменении $options будет обязательно изменен $key), но и второе условие будет соблюдаться, если мы будем все типы данных в $options использовать «канонически», т.е. не допускать строки "1" вместо числа 1 (хотя в PHP два таких значения равны, но их сериализованное представление различается). Функция md5 используется для «сжатия» данных: ключ memcached имеет ограничение по длине, а сериализованное представление может быть слишком длинным.
Кластеризация memcached
Для распределения нагрузки и достижения отказоустойчивости вместо одного сервера memcached используется кластер из таких серверов. Сервера, входящие в кластер, могут быть сконфигурированы с различным объемом памяти, при этом общий объем кэша будет равен сумме объемов кэшей всех memcached, входящих в кластер. Процесс memcached может быть запущен на сервере, где слабо используется процессор и не загружена до предела сеть (например, на файловом сервере). При высокой нагрузке на процессор memcached может не успевать достаточно быстро отвечать на запросы, что приводит к деградации сервиса.
При работе с кластером ключи распределяются по серверам, то есть каждый сервер обрабатывает часть общего массива ключей проекта. Отказоустойчивость следует из того факта, что в случае отказа одного из серверов ключи будут перераспределены по оставшимся серверам кластера. При этом, конечно же, содержимое отказавшего сервера будет потеряно (см. раздел «Потеря ключей»). В случае необходимости важные ключи можно хранить не на одном сервере, а дублировать на нескольких, так можно минимизировать последствия падения сервера за счет избыточности хранения.
При кластеризации становится актуальным вопрос распределения ключей: как наиболее эффективным образом распределить ключи по серверам. Для этого необходимо определить функцию распределения ключей, которая по ключу возвращает номер сервера, на котором он должен храниться (или номера серверов, если хранение происходит с избыточностью).
Исторически первой функцией распределения была функция модуля:
f(ключ) = crc32(ключ) % количество_серверов
Такая функция обеспечивает равномерное распределение ключей по серверам, однако проблемы возникают при переконфигурировании кластера memcached: изменение количества серверов приводит к перемещению значительной части ключей по серверам, что эквивалентно потере значительной части ключей.
Альтернативой для данной функции является механизм консистентного хэширования (consistent hashing), который при переконфигурации кластера сохраняет положение ключей по серверам. Этот подход был реализован в клиентах memcached впервые разработчиками сервиса Last.fm в апреле 2007 года.
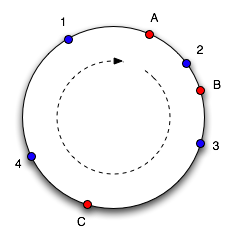
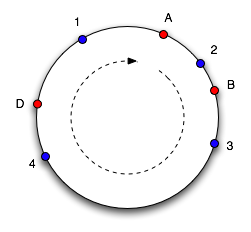
Суть алгоритма заключается в следующем: мы рассматриваем набор целых чисел от 0 до 232, «закручивая» числовую ось в кольцо (склеиваем 0 и 232). Каждому сервера из пула memcached-серверов мы сопоставляем число на кольце (рисунок слева, сервера A, B и C). Ключ хэшируется в число в том же диапазоне (на рисунке - синие точки 1-4), в качестве сервера для хранения ключа мы выбираем сервер в точке, ближайшей к точке ключа в направлении по часовой стрелке. Если сервер удаляется из пула или добавляется в пул, на оси появляется или исчезает точка сервера, в результате чего лишь часть ключей перемещается на другой сервер. На рисунке 2 справа показана ситуация, когда сервер C был удалён из пула серверов и добавлен новый сервер D. Легко заметить, что ключи 1 и 2 не поменяли привязки к серверам, а ключи 3 и 4 переместились на другие сервера. На самом деле одному серверу ставится в соответствие 100-200 точек на оси (пропорционально его весу в пуле), что улучшает равномерность распределения ключей по серверам в случае изменения их конфигурации.
Данный алгоритм был реализован во многих клиентах memcached в различных языках программирования, однако реализация иногда отличается деталями, что приводит к несовместимости хэширования. Данный факт делает консистентное хэширование неудобным для использования при доступе к одному пулу серверов memcached из различных языков программирования. Простейший алгоритм с crc32 и модулем реализован во всех клиентах на всех языках одинаково, что обеспечивает одинаковое хэширование ключей по серверам. Поэтому в случае отсутствия необходимости обращаться к memcached из различных клиентов на разных языках программирования более привлекательным выглядит подход с консистентным хэшированием.
Продолжение следует…
Материалы