Лучшие практики использования локальных больших языковых моделей для программистов
Обзорная статья по лучшим практикам использования больших языковых моделей (LLM) для работы с кодом.
Какие большие языковые модели, что я могу рекомендовать:
- Athene-V2-Chat-GGUF 72B- самая продвинутая БЯМ на сегодняшний день. Создана на основе Qwen2.5-72B-Instruct. Доступные варианты квантов для использования - от IQ3_XXS до Q8_0. Размер контекста - 32КБ. 80 слоёв.
- Qwen2.5-72B-Instruct-GGUF- не быстрая, очень качественная. Требует более 128ГБ оперативной памяти при квантовании Q8_0 и использовании полного размера контекста. Размер контекста - 32КБ. 80 слоёв.
- Llama-3.1-Nemotron-70B-Instruct_iMat_GGUF/Llama-3.1-Nemotron-70B-Instruct_fp16-00001-of-00004.gguf - очень мощная не быстрая модель. Результат иногда лучше, иногда на том же уровне, чем Qwen-2.5-72B-Instruct. Большой плюс - размер контекста 128КБ. 80 слоёв.
- Mistral-Large-Instruct-2411 - новая модель, на замену Mistral-Large-Instruct-2407. Главный плюс - время получения первого токена существенно меньше, чем у LLama 3.1 и Qwen 2.5. Количество слоёв = 88. Размер контекста 128K. Очень умная. По качеству генерации не уступает Qwen и Athene, но имеет свои особенности.
- LLama 3.1 405b Instruct - очень мощная модель, но очень капризная. У неё самое большое количество слоёв среди всех и одни из самых больших возможностей. Размер контекстного окна = 128K.
- second-state\Llama-3.3-70B-Instruct-GGUF/Llama-3.3-70B-Instruct-f16-00001-of-00005.gguf - новая, более продвинутая модель LLama. Лучше, чем любые предыдущие, но слабее Qwen, Athene и Mistral Large. Размер контекста 128K. Количество слоёв = 80.
Замечание по точности квантования моделей GGUF
Старайтесь использовать квантование от mradermacher.
Хорошие варианты квантования ищите среди тех моделей GGUF файлов, в имени которых есть «i1»: Mistral-Large-Instruct-2407-i1-GGUF, Mistral-Large-Instruct-2411-i1-GGU, Athene-V2-Chat-i1-GGUF и т.д.
Самые лучшие по качеству LLM содержат F16 и F32 среди вариантов моделей. Их проще искать используя запрос в Яндекс поиск:
Qwen 2.5 GGUF "F16"
Qwen 2.5 GGUF "F32"
и т.д.
Сравнение моделей можно найти тут: https://huggingface.co/Nexusflow/Athene-V2-Chat
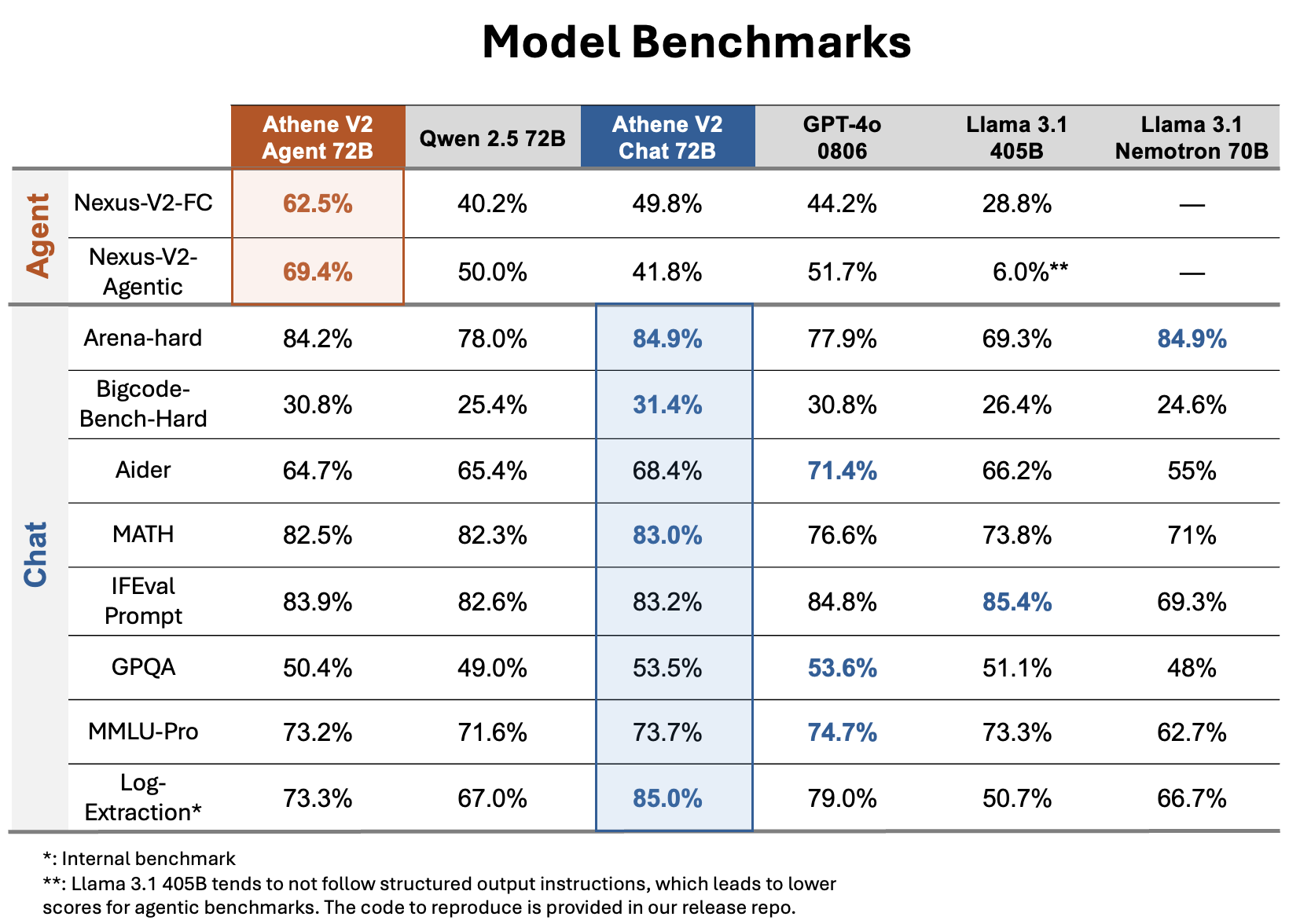
Могу заявить, что уже нет нужды сильно увеличивать модели.
Уровень Athene V2 72B Chat с максимальным квантованием типа F16/F32 достаточен для работы с ним, как с разработчиком высочайшего уровня.
80 слоёв делают модель по уровню интеллекта не ниже качественного специалиста.
Современным моделям не хватает лишь количества слоёв.
Рекордсменом по количеству слоёв является модель LLama 3.1 405B с 126 слоями. И именно поэтому это самая умная модель, но так как её не правильно используют - поэтому возникают проблемы.
Ниже опишу какие проблемы не дают возможность полноценно использовать продвинутые LLM.
Главные проблемы, почему все не кинулись внедрять LLM:
- Нет опыта написания правильно оформленных технических заданий с разметкой Markdown
- В технических заданиях не уделяется внимание подготовительным шагам, в которых должны выстраиваться цепочки мыслей на обдумывание задачи, поиск решений и конструирование дизайна. Т.е., в любом качественном ТЗ должны содержаться такие блоки как:
# На первом этапе, внутри тэга «Изучение» - ты должен построить цепочку мыслей, чтобы понять задачу.
# На втором этапе, внутри тэга «Анализ» - ты должен построить цепочку мыслей, чтобы провести анализ задачи, чтобы найти методы её решения.
# На третьем этапе, внутри тэга «Дизайн» - ты должен создать дизайн программы, который в соответствии с лучшими практиками программирования спроектирует программу и визуальные формы программы.
# На четвёртом этапе, внутри тэга «Предварительный код» - ты построишь предварительный вариант программы.
# На пятом этапе, внутри тэга «Проверка» - ты проверишь, что все нужные функции объявлены и библиотеки подключены.
# На последнем этапе, внутри тэга «Результат» - ты напишешь код программы полностью, добавишь комментарии, добавишь обработчики ошибок, логгирование ошибок и инициализируешь константы.
это лишь общий вид любого ТЗ на кодогенерацию.
Он лишь должен показать, что чем больше мы заставляем писать ИИ - тем более качественный код получим в конце. - Все LLM, количество слоёв у которых меньше 80 - не умеют «думать». Код с нуля они написать смогут (и то с большими проблемами и при наличии отлично прописанных ТЗ), но уже отладку программы им доверить нельзя.
- Чем больше размер пользовательского промпта (размер текста, посылаемого на обработку) - тем дольше будет думать LLM. Самые быстрые на первоначальном этапе - это модели Mistral и Mixtral, особенно с пониженным квантованием типа IQ3_XXS.
- Большие размеры контекстного окна существуют - их можно искать в интерфейсе LM Studio вводя в строке поиска: gradient, 1048K, 4194K и большой размер контекста есть у Mistral Nemo.
- Многие ожидают, что сфорулировав запрос к LLM, типа:
«Напиши мне программу, которая будет общаться с видеокамерой, записывать видео, распознавать вторжение и оповещать пользователя через Telegram»
они сразу получат готовое решение - ошибаются.
Без корректного качественного ТЗ, которое должно быть написано так, чтобы его однозначно понял программист уровня джун - не получится. Именно поэтому, без предварительного этапа выяснения у ИИ чего ему не хватает в ТЗ - не получится. ТЗ необходимо пропускать через промпт, который проанализирует текст и укажет на наличие неоднозначностей и отсутствия необходимой информации (например, о моделях камеры и протоколах обмена). - Настройки в LM Studio должны быть такие и никакие другие:
Размер пакета оценки: по размеру контекста,
Flash attention: желательно вкл. - увеличивается точность,
Температура: 0,
Потоки CPU: максимум доступных потоков, которые можно узнать в диспетчере задач,
Min P: 1e-7,
Top P: 0.000001,
Top K: 500,
Штраф за повторение: 1
Разгрузка на GPU: если модель полностью не помещается в видеопамяти - то подбирать так, чтобы при работе модели температура GPU была максимальной. Узнать температуру GPU можно в диспетчере задач.
- Шаг 1. Улучшение технического задания с помощью специального промпта: https://nikitayev.livejournal.com/148713.html
- Шаг 2. Генерация программ на Python с использованием больших языковых моделей (LLM): https://nikitayev.livejournal.com/147383.html
- Шаг 3. Отладка кода программы: https://nikitayev.livejournal.com/149101.html
- Как студенту в 2025 году написать такой диплом, чтобы приглашение пришло гарантировано:
https://nikitayev.livejournal.com/150432.html - Демонстрации вариантов внедрения ИИ на производстве: https://nikitayev.livejournal.com/148855.html
- Как получить правильную квантизацию модели:
https://nikitayev.livejournal.com/151085.html - Форматирование документов MS Word в формат Markdown: https://nikitayev.livejournal.com/148264.html
- Влияние промпта для LLM. Эффекты от форматирования промпта: https://nikitayev.livejournal.com/145967.html
- Лучший результат выполнения тестового промпта:
https://nikitayev.livejournal.com/150630.html - Провёл испытания локальных БЯМ(LLM): https://nikitayev.livejournal.com/145916.html
- Предложение по созданию модели ускоренного внедрения инноваций в России: https://nikitayev.livejournal.com/144790.html
- LLM Leaderboard: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/
- Промптинг: действительно полезное руководство:
https://habr.com/ru/articles/865952/ - Собираем компьютер для запуска самых больших LLM и обучения моделей YOLOv8+
https://nikitayev.livejournal.com/141817.html

Промпты опубликовал тут: https://disk.yandex.ru/d/iP_f37VTFKm_rA