как работают vybory-24.ru
пока тихонько болею, решил описать, как на сайте Выборы-24 работает подбор новостей по теме и облако меток.
1. Основная проблема с метками (я их буду называть тегами - мне так привычней), то что их количество со временем растёт - у одного из моих клиентов их уже под сотню, а интерес к старым тегам постепенно падает. вот уже никому не интересно про Ивана Охлобыстина, но так как новостей про него было написано порядком, то, во-первых, торчать в списке тегов он будет вечно, а во-вторых - достаточно крупно, ведь в прошлом году новости про него писали даже ленивые. итак, проблема обозначена.
есть ещё один ньюанс: как считать уровень для каждого тега, то есть каким образом определять границы для веса. если это вам понятно, можете пропустить врез, который идёт ниже.
я долго не мог придумать, как же определять границы между уровнями тегов. скажу честно, на Ihateshopping длительное время пограничные значения я задавал просто вручную, но долго это продолжаться не могло.
мне на ум пришла картинка с нормальным распределением. и хотя нормальное распределение само по себе вряд ли может здесь пригодиться, я решил использовать предлагаемые пропорции для граничных значений. таким образом, уровни распределяются следующим образом: 1/6 - 1, 2/6 - 2, 2/6 - 3, 1/6 - 4. получается, что самых больших и самых маленьких тегов будет по 1/6 (на самом деле это не всегда так), а основных (второго и третьего уровня) по 1/3.
теперь осталось дело за малым: выбрать все возможные варианты количества новостей по тегам, посмотреть значение на 1/6, 1/2 и 5/6. вот, собственно, и всё.
решение проблемы со "старыми" тегами, как ни странно, основано на дате. надо найти для каждого тега самую "новую" новость, а потом выбрать какое-то количество (в моём случае это 42 :) верхних из них, отсортировав по дате в обратном порядке. именно эти теги и нужно выводить.
осталась проблема веса и граничных значений для получившейся выборки - ведь и вес, и границы рассчитываются для всех доступных новостей. выход тот же самый - надо использовать дату: минимальную дату из выборки по тегам (максимальную дату для тега для самой старой новости, если так будет понятней). теперь эту дату надо использовать как для подсчёта весов, так и в алгоритме для расчёта граничных значений.
в результате получаем постоянно обновляющееся облако тегов, вес которых отражает реальный интерес к последним событиям.
всё.
2. На всех новостных ресурсах существует проблема подвёрстки новостей "по теме". решается она двумя способами:
оба варианта с моей точки зрения не очень хороши. на первый тратится много времени и существует шанс что-то пропустить; второй часто не обеспечивает должного качества, например, по тегу "суд" рядом с разборками КПРФ и Осколкова стоят новости про Прохорова и конституционный суд.
для себя я нашёл такой выход: использую автомат, но не простой, а золотой :) система должна выбирать новости, в которых совпало максимальное количество тегов. и чем больше тегов используется, тем точнее будет привязка (можете проверить сами, какие новости привязываются к местному суду). идея ясна, но вот над реализацией пришлось подумать. в результате, родилось простое и изящное решение. а ещё - очень быстрое. (прежде чем читать дальше, подумайте - а как бы эту проблему решали вы?)
на самом деле я думал достаточно долго, как выбирать новости с похожими тегами, но решением оказался простой count:
select top 4 object_type, object_id, count(tag_id) as cnt into #tmp from vw_objects_tags
where tag_id in (select tag_id from vw_objects_tags where object_id=@object_id and object_type=@object_type)
and object_id<>@object_id
group by object_type, object_id
order by count(tag_id) desc, object_id desc;
выбираем во временную таблицу идентификаторы новостей, совпадения с тегами нужной новости максимально.
select distinct ot.object_type, ot.object_id, path, images, caption, lead, text_date, date
from vw_objects_tags ot inner join #tmp t on ot.object_type=t.object_type and t.object_id=ot.object_id
where published = 1 order by date desc;
drop table #tmp;
а потом используем их для формирования списка новостей. вот как-то так.
надеюсь, вам было интересно
1. Основная проблема с метками (я их буду называть тегами - мне так привычней), то что их количество со временем растёт - у одного из моих клиентов их уже под сотню, а интерес к старым тегам постепенно падает. вот уже никому не интересно про Ивана Охлобыстина, но так как новостей про него было написано порядком, то, во-первых, торчать в списке тегов он будет вечно, а во-вторых - достаточно крупно, ведь в прошлом году новости про него писали даже ленивые. итак, проблема обозначена.
есть ещё один ньюанс: как считать уровень для каждого тега, то есть каким образом определять границы для веса. если это вам понятно, можете пропустить врез, который идёт ниже.
я долго не мог придумать, как же определять границы между уровнями тегов. скажу честно, на Ihateshopping длительное время пограничные значения я задавал просто вручную, но долго это продолжаться не могло.
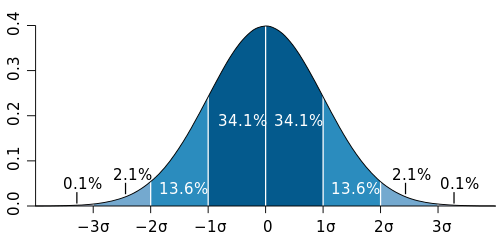
мне на ум пришла картинка с нормальным распределением. и хотя нормальное распределение само по себе вряд ли может здесь пригодиться, я решил использовать предлагаемые пропорции для граничных значений. таким образом, уровни распределяются следующим образом: 1/6 - 1, 2/6 - 2, 2/6 - 3, 1/6 - 4. получается, что самых больших и самых маленьких тегов будет по 1/6 (на самом деле это не всегда так), а основных (второго и третьего уровня) по 1/3.
{kind=link}
теперь осталось дело за малым: выбрать все возможные варианты количества новостей по тегам, посмотреть значение на 1/6, 1/2 и 5/6. вот, собственно, и всё.
решение проблемы со "старыми" тегами, как ни странно, основано на дате. надо найти для каждого тега самую "новую" новость, а потом выбрать какое-то количество (в моём случае это 42 :) верхних из них, отсортировав по дате в обратном порядке. именно эти теги и нужно выводить.
осталась проблема веса и граничных значений для получившейся выборки - ведь и вес, и границы рассчитываются для всех доступных новостей. выход тот же самый - надо использовать дату: минимальную дату из выборки по тегам (максимальную дату для тега для самой старой новости, если так будет понятней). теперь эту дату надо использовать как для подсчёта весов, так и в алгоритме для расчёта граничных значений.
в результате получаем постоянно обновляющееся облако тегов, вес которых отражает реальный интерес к последним событиям.
всё.
2. На всех новостных ресурсах существует проблема подвёрстки новостей "по теме". решается она двумя способами:
- вручную (так делалось раньше на портале Красноярск.Биз и, судя по ответу, так сейчас делается на Ньюслабе;
- автоматически по тегам, сюжетам, персонам, етс.
оба варианта с моей точки зрения не очень хороши. на первый тратится много времени и существует шанс что-то пропустить; второй часто не обеспечивает должного качества, например, по тегу "суд" рядом с разборками КПРФ и Осколкова стоят новости про Прохорова и конституционный суд.
для себя я нашёл такой выход: использую автомат, но не простой, а золотой :) система должна выбирать новости, в которых совпало максимальное количество тегов. и чем больше тегов используется, тем точнее будет привязка (можете проверить сами, какие новости привязываются к местному суду). идея ясна, но вот над реализацией пришлось подумать. в результате, родилось простое и изящное решение. а ещё - очень быстрое. (прежде чем читать дальше, подумайте - а как бы эту проблему решали вы?)
на самом деле я думал достаточно долго, как выбирать новости с похожими тегами, но решением оказался простой count:
select top 4 object_type, object_id, count(tag_id) as cnt into #tmp from vw_objects_tags
where tag_id in (select tag_id from vw_objects_tags where object_id=@object_id and object_type=@object_type)
and object_id<>@object_id
group by object_type, object_id
order by count(tag_id) desc, object_id desc;
выбираем во временную таблицу идентификаторы новостей, совпадения с тегами нужной новости максимально.
select distinct ot.object_type, ot.object_id, path, images, caption, lead, text_date, date
from vw_objects_tags ot inner join #tmp t on ot.object_type=t.object_type and t.object_id=ot.object_id
where published = 1 order by date desc;
drop table #tmp;
а потом используем их для формирования списка новостей. вот как-то так.
надеюсь, вам было интересно