Цифровая реальность: как мировая конкуренция поисковиков делает офлайн умнее

Действительность, которая нас сегодня окружает, уже нельзя однозначно назвать онлайном или офлайном. Мы редко об этом задумываемся, но мы уже несколько лет умеем моментально получать правильный ответ на любой вопрос, интернет раньше нас может сформулировать, чего мы хотим прямо сейчас, а личный девайс умеет навигировать по незнакомому городу не хуже местного жителя. Но вся эта быстрая и удобная реальность могла бы быть гораздо менее продвинутой, а могла бы и не случиться вовсе. Она строится на глобальной «оцифровке» офлайна, которая последние пару десятков лет делается руками тысяч больших и маленьких IT-игроков, - а стимулируется, как ни странно, мировой гонкой поисковых систем.
На сегодняшний день поисковый ландшафт планеты раскрашен, конечно, в цвета американского флага. Есть Google, монополист в абсолютном большинстве стран, его мировая поисковая доля - 89%. C ним пытаются бороться другие поисковики американского происхождения - Bing с чуть более чем 4% по миру, Yahoo!, постепенно умирающий (кроме своего японского воплощения Yahoo!Japan) с 3 процентами, и другие игроки с долей меньше процента, вроде Ask и AOL. А еще есть четыре феноменальных национальных компании, которые разными способами выжили и продолжают держать оборону, лидируя в поисковой доле в своих странах. Это китайский Baidu, южнокорейский Naver, чешский Seznam. Мы причисляем себя к их числу. Это те, кто не дают Google расслабляться, - и таким образом участвуют в формировании мировых стандартов интернет-поиска.
История Интернета в оладушках
Еще буквально 20 лет назад поисковики были совсем другими. Единственное, что они умели - это искать интернет-страницы по ключевым словам. Кажется, что они и сейчас делают то же самое, - но так кажется лишь потому, что к хорошему быстро привыкаешь, вот и мы привыкли к тому, что незаметно умеет делать поиск, и принимаем все это как должное, - а ведь мы все долго к этому шли. В середине 90-х, когда интернет еще был относительно молодым и страниц в нем было немного (какие-то десятки миллионов), единственное, чего люди ожидали от поисковика - это чтобы он умел отыскивать страницы, содержащие какие-то искомые слова. Например, по запросу «как готовить картофельные оладьи» пользователю 90-х выдались бы документы, содержащие эти четыре слова, причем без особого ранжирования - просто всё, что нашлось в интернете. На первой странице выдачи вполне могли оказаться глава из книги или вопрос с форума - приоритет отдавался разве что страницам, где искомые слова употреблялись чаще. Тогда было нормой, что для того, чтобы найти ответ на свой вопрос, нужно посидеть и поисследовать - походить по страницам, почитать в разных местах, что-то скомпилировать, составить собственное представление о предмете. Неслучайно название созданного в 1996 году Рамблера произошло от слова «ramble» - бродить, шататься, - а южнокорейский Naver, основанный в 1999-м, образовал свое название от глагола «navigate». Задачей поисковика в те времена было помогать пользователю бродить по интернету в долгих и часто непростых попытках найти нужный ему ответ.
К началу XXI века количество страниц сильно выросло, а кроме того, стало понятно, что поиск - это не просто инструмент навигации по Интернету, но и растущая коммерческая площадка. Все больше запросов задавалось с целью найти товар или услугу. На этой плодородной почве взросло ремесло, навсегда изменившее интернет - именно тогда, на заре нулевых, появились первые специалисты по SEO. Среди них было много тех, кто действительно делал хорошее дело: увеличивал связность Интернета и улучшал находимость информации поисковиках. Но были еще ребята, которые смекнули: чтобы тебя скорее всего заметили и купили, нужно просто попасть в первую десятку выдачи по любому запросу, - а для этого нужно всего лишь написать страницу с ключевыми словами этого запроса, да так, чтобы их там было побольше. И стали писать. Интернет наводнился ничего не значащими страницами с ни к чему не привязанными ключевыми словами, повторяемыми по много раз.
Поисковики, чтобы не потерять смысл своего существования для пользователя, были вынуждены отреагировать - пришлось выработать первые простые алгоритмы, учитывающие некоторые важные сигналы об интернет-страницах - например, об использовании искомых слов в ключевой роли, об авторитетности самой страницы (сколько других страниц на нее ссылаются), о полезности (возвращаются ли пользователи потом обратно в поиск или удовлетворяются тем, что нашли) и так далее. В 2001 Google запатентовал алгоритм PageRank (вскоре Яндекс запустил тематический индекс цитирования - Forbes). На запрос «как приготовить картофельные оладьи» поисковик нулевых уже выдавал страницы, ранжированные по релевантности - в них был подавлен наиболее бессмысленный спам, а наверх понимались страницы, на которые кликало большинство пользователей - например, с кулинарными статьями, упоминающими оладушки, или даже с рецептами.
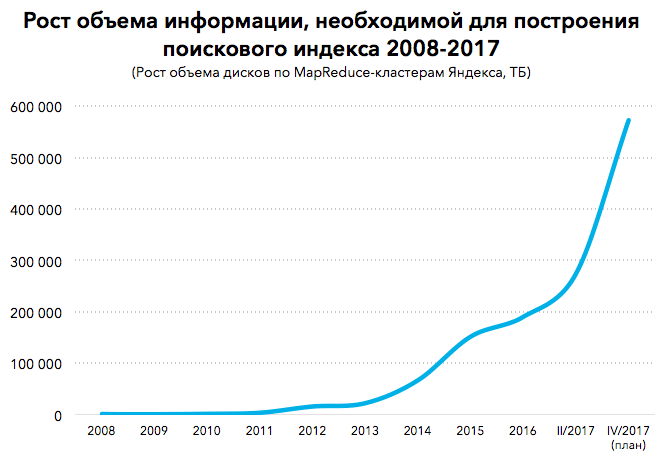
Но на каждое улучшение сеошники отвечали новым трюком - размещали слова в заголовках, покупали ссылки - в общем, делали все, чтобы рост количества информации в интернете обгонял закон Мура. Параллельно с этим шел естественный рост числа настоящих страниц, и тоже по экспоненте. В итоге страниц в интернете, а главное, их признаков (тех самых «сигналов» для поисковика) стало уже так много, что адекватно комбинировать их человеческим мозгом стало просто невозможно. И вот тогда в поиске настала эра искусственного интеллекта.
Нейросеть, нейросеть
Матрикснет (технология ранжирования, используемую в Яндексе в середине 2000-х - Forbes) умел анализировать сначала около сотни, а потом все больше и больше (сегодня их уже больше тысячи) разных видов сигналов от каждой страницы в интернете, а главное, впервые стал распределять их по важности без участия человека. Мы действительно считаем это качественным прорывом: до этого машина обсчитывала сами сигналы (посещаемость, релевантность, авторитетность страницы и т.д.), но только человек (инженер) мог сказать ей, какие сигналы надо считать важными, а какие нет. А здесь она стала учиться сама решать, какой вес присвоить какому сигналу. Это было одно из первых применений в поисковом системе реального машинного обучения. Насколько нам известно, другие поисковые системы до сих пор хотя бы на самом верхнем уровне алгоритма все-таки используют ручную сборку весов сигналов. Это значит, что общие принципы работы поисковика определяет человеческий интеллект. У нас - машинный.
Как и все технологические прорывы, этот случился не от легкой жизни, а потому что, как говорится, прижало. Сработал прекрасный парадокс - чем меньше у компании ресурсов, тем более продвинутые решения она может внедрять, а все потому, что самые продвинутые решения - это те, которые как раз экономят максимум ресурсов. Когда Naver восходил на своем южнокорейском интернет-небосклоне, он пытался убедить корейцев, что поможет им найти ответы на любые вопросы (у них еще была большая национальная кампания с простым посылом - Ask Naver). Но корейскоязычный сегмент интернета был тогда настолько мал, что никаких ответов там на самом деле еще не было. И Naver пришлось придумать решение - он запустил сервис вопросов и ответов, что-то вроде нашего Ответ.Mail.ru, в котором пользователи получали «ачивки» за ответы на чужие вопросы, - и таким образом генерили для поисковика массу бесплатного и релевантного контента, которым могли пользоваться остальные. Это решение, может быть, и определило дальнейшую судьбу Naver не просто как поисковика, а как главного национального контентного агрегатора. Кстати, доля Google в Корее до сих пор не поднимается выше 4%. Корея взяла краудсорсингом, ну а нам пришлось прокачивать свойственную россиянам склонность к математике. У Гугла же такой необходимости не было - у них тогда просто были ресурсы на то, чтобы выполнять некоторые процессы руками, - и только потом заставила выровняться глобальная конкуренция.
Конкуренция вообще вещь полезная. Когда Google только пришел в Россию, реальное качество поиска у них было выше нашего аж на 20%, так показывали наши внутренние метрики. Все бы ничего, но американцы еще и очень хорошо умеют продавать, так что Google принес с собой помимо хорошего поиска блестящую дистрибуцию - например через предустановку в FireFox, который тогда бурно рос в России. Наша доля тогда падала по процентному пункту в месяц, пришлось мобилизоваться. Чтобы нагнать упущенную дистрибуцию, пришлось в том числе создать ненавистный многим Яндекс.Бар, который мы спустя несколько лет похоронили. Но главное, пришлось резко увеличить качество поиска. Для этого пришлось внедрить и Матрикснет, и ряд других технологий - все они появлялись от необходимости хоть в чем-то обгонять конкурентов. Это лишь один из примеров того, как в конкурентной борьбе поисковые системы стали переходить к новому витку развития - от индексирования к знанию.
Смысловая нагрузка
К информации в интернете можно относиться как к хранилищу текста и картинок на веб-страницах - примерно так к ней и относились в первые десять лет существования поисковиков. Но можно относиться к ней и иначе - в текстах и картинках ведь залегает знание. Причем именно его чаще всего ищут люди, которые обращаются к поисковой системе с запросом. По большому счету человеку неважно, сколько страниц есть в интернете с заветными словами «как приготовить картофельные оладьи», - ему важно узнать, как уже, в конце концов, их готовить! Мы, поисковики, обрабатываем сотни миллионов страниц в секунду и гордимся этим, но для человека все наоборот - исследования UX регулярно показывали, что чем меньше страниц пользователю нужно прочитать, чтобы найти ответ, тем больше он доволен поиском. Значит, поисковику нужно уметь не просто индексировать страницы - нужно еще собирать с них некое полезное знание, которое на них лежит. Технологически это означало принципиально другую работу с информацией - из текстов (а потом и картинок) нужно начать выделять не слова и пиксели, а смысл. И справляться с этим при нынешних объемах интернета должна машина.
Чтобы вы понимали, как бы красиво ни называлось все, что касается машинной работы с информацией - нейросети, искусственный интеллект, глубокое обучение, и прочее - без людей там на самом деле не обходится. Машину надо сначала учить, потом проверять, правильно ли она научилась, если неправильно - менять принципы или выборку, на которой ее учат, - все это делают живые люди, и они еще долго будут это делать. Над увеличением качества поиска (у нас по крайней мере) работают не только сотни сотрудников, но еще и тысячи людей, так называемых «толокеров», которые зарабатывают деньги, выполняя небольшие задания - от «выбрать более подходящую картинку» до «проверить наличие организации по адресу» - и помогая таким образом обучать алгоритмы. Ну и естественно, миллионы пользователей каждым своим действием делают то же самое - учат машину делать ее машинную работу лучше.
Как на практике реализовать понимание смысла и работу со знанием? Ну, например, можно воспользоваться системами, в которых это знание присутствует в структурированном виде. Можно взять онлайн-словари, энциклопедии, в конце концов - Википедию. Там и знание хранится понятными блоками, а источники можно считать более-менее надежными. Но задача поисковика уже не в том, чтобы просто показать пользователю эту страницу - а в том, чтобы понять, что он хочет, найти информацию за него и сразу дать ответ - желательно, чтобы он вообще никуда не переходил.
Например, пользователь спрашивает «за кем замужем Собчак» или «сколько километров Джомолунгма». В Википедии есть страницы про нынешнего супруга Ксении Максима Виторгана и про гору Эверест, но там не написано дословно того, что ввел пользователь. Там даже не написано слов «супруг» или «километров». Там написано «третий брак с телеведущей и журналисткой» и «высота над уровнем моря». Но поисковая система умудряется вычленить короткий ответ, который нужен пользователю, и выдать его, не перепутав при этом нынешнюю жену с предыдущими, а гору с морем.
Как это вообще может работать, спросите вы, машина ведь пока не умеет реально понимать смысл как человек? Как человек - нет. Зато она умеет узнавать паттерны и потом применять их.
У совокупности того, что ищут и хотят пользователи и как выглядят правильные ответы на их вопросы, есть некоторые общие характеристики (например, каким языком они задают вопрос), а у правильных ответов, в свою очередь, есть некоторые признаки относительно массива текста (например, в нем употребляется ровно то слово, которое пользователь ввел, информация располагается в определенном месте статьи и так далее). Чтобы машина научилась отличать суть от не сути, нужно скормить ей очень много примеров, показать, где правильно, а где нет, а потом еще научить получать обратную связь от пользователя - то есть по прямым или косвенным признакам понимать, подошел ответ или нет (например, с помощью лайков, времени, проведенного за кликом и т.д.). Так машина научится подтягивать под запрос именно искомое знание, а не просто похожие слова.
То, что описано выше, сегодня реализовано в виде так называемых «фактовых ответов» - формата выдачи ответа, в котором вам вообще не нужно переходить ни на какую страницу, вы просто сразу видите ответ. Это то, что уже есть у многих поисковиков, и именно поэтому пользователи даже не задумываются о том, что это что-то особенное, быстрые ответы просто слишком естественно появились в нашей жизни. Тем не менее, здесь все еще есть большое пространство для развития, - до сих пор поисковики умеет быстро выдавать готовую суть в разном виде примерно для 10-20% запросов.
Отдельный аспект работы со смыслом - это распознавание контекста. Во-первых, то, что пользователь хочет, и то, как он об этом спрашивает, - далеко не всегда одно и то же, - у запросов свой особый язык, который синтаксически не похож ни на один язык мира. Во-вторых, на веб-страницах искомые слова могут отсутствовать, хотя там есть синонимы, или наоборот, слово присутствует, но в другом значении. Поиск должен уметь все это понимать.
И в этом нет ничего невозможного. Обучение машины здесь очень похоже на то, как человек осваивает иностранный язык - иногда мы не можем точно перевести значение слова, но из контекста примерно понимаем суть. Так же и машина - из многих разных контекстов она может «примерно понять» смысл того или иного слова - и сделать выводы о том, какие контексты в каком случае для него релевантны. Машине помогает то, что внутри одной поисковой сессии можно видеть связь между запросом и действиями пользователя - например, иногда пользователь не решает задачу с первого раза и переформулирует запрос, - и тогда мы понимаем, что текстового соответствия недостаточно, нужно анализировать контекст. На таких примерах мы выделяем контексты для примерно миллиарда разных слов и словосочетаний и учимся понимать, какие связи существуют между разными контекстами.
Априорное знание о том, что между словами и словосочетаниями есть смысловая близость, что они чаще или реже встречаются в разных контекстах, что они сочетаются и так далее, инженеры вложили в машину - и на основании этого у поисковиков появились продвинутые алгоритмы, понимающие смысл запросов, а не только слова. (Примерно в одно и то же время у Google появился RankBrain, у «Яндекса» - «Палех» - Forbes).
Почти как человек
Сегодня на запрос «Как приготовить картофельные оладушки» поисковик наконец покажет вам именно то, что вы на самом деле ищете - «рецепт драников», а может быть, даже сразу подтянет сам рецепт в фактовый ответ, чтобы вам никуда не переходить - и это при том, что в запросе и ответе нет ни одного одинакового слова. Поиск умеет понимать вопросы вроде «фильм, в котором человек родился старым, а потом молодел» или «кто такой артемий татьянович». Это делается с помощью сложной математической модели, в которой есть так называемое пространство семантических векторов, и для каждой пары слов или словосочетаний можно посчитать функцию их семантической близости - исходя из контекста и совместной встречаемости, - а потом обучиться с подкреплением сотен миллионов пользовательских действий в день.
Пальцы - двигатель прогресса
Кроме большой и умной математики, стоящей за поисковыми машинами, для человека поиск - это в первую очередь интерфейс. И тут очередная революция случилась при массовом переходе пользователей на мобильные устройства. Причем главное изменение было даже не в том, что пользователю резко понадобилось искать места рядом с собой, и поэтому в механизмы поиска надо было быстро прикрутить геосервисы - на самом деле геопривязанных запросов на мобильном всего около 10%. Главным изменением на самом деле стало то, что на экране смартфона страшно неудобно что-то набирать. Человек со смартфоном хочет как можно меньше печатать и как можно быстрее получить ответ. И здесь, в гонке за пользователем, началась революция голосовых интерфейсов - появился сначала голосовой ввод, потом первые помощники - Siri, Alexa, Google Assistant («Яндекс» также запустил помощника - Алиса). Все поисковики сегодня стремятся к тому, чтобы человеку вообще ничего не нужно было делать руками,а можно было полностью решить свои задачи голосом. Это само по себе сложнейшая техническая задача - для нее нужно, чтобы машина умела общаться контекстуально - не просто хорошо распознала слова «рецепт драников», не просто сумела найти рецепт, озвучить нужное количество картошки, а потом, когда пользователь спросит «а где ее купить», понять из контекста, что за словом «ее» скрывается картошка и найти ее поблизости.
От слов к делу
И наконец, новой вехой развития является то, зачем, собственно, пользователь ищет эти самые драники. Любой запрос - это не просто текст, а будущее действие, поэтому кроме знания рецепта, поиск сегодня уже должен познать суть драников - то есть расшифровать, что на самом деле надо пользователю и чем ему можно помочь. Рецепт обычно ищут, когда хотят приготовить, значит наверное, будет полезно найти, где рядом с пользователем продаются ингредиенты, работает ли сейчас этот магазин, сколько туда добираться и на чем. Когда ищут ресторан, удобно сразу же из поисковой выдачи позвонить в него, а может быть, даже одним нажатием забронировать столик. В общем, сегодняшний пользователь уже ожидает, что все реальные жизненные сценарии будут доступны в едином интерфейсе.
Чтобы это стало возможным, нужно ни много ни мало оцифровать всю реальность, которая хоть что-то значит для человека. Рестораны должны присутствовать в виртуальной системе бронирования, магазины - делиться перечнем товаров на точках, каталоги и реестры - отдавать правильную информацию, и так далее. Китайский Baidu, например, несколько лет назад активно вкладывался как раз в эту связь онлайна и офлайна - у них был проект, целью которого было помочь пользователям искать условные «цветы рядом со мной» - в рамках проекта у локальных организаций была возможность просто отмечаться на общей карте, не создавая дорогостоящего сайта. Пресловутый корейский Naver создает такую же экосистему в области мультимедиа - на нем как на единой площадке размещаются совершенно разные поставщики медийного контента. Так же и мы интегрируем в карты данные о движении городского транспорта, а Google, например, организует хранилище музыки.
В связи с этим бизнес поисковиков должен в скором времени довольно сильно измениться, меняя при этом и повседневную жизнь человека. Например, реклама, на которой сейчас построена вся поисковая монетизация, будет знать про человека гораздо больше, и как следствие, понимать не просто что он ищет, а почему, и соответственно что еще ему в контексте этого предложить. Но главное, помимо рекламной модели будет развиваться модель маркетплейса, встроенного прямо в поисковик - это будет немного похоже на то, как сегодня работают магазины приложений или агрегаторы товаров, только с еще более сильной интеграцией - на поисковый запрос можно будет отвечать не просто товаром или услугой, а проводить пользователя целиком по всему сценарию - от поиска нужного товара до заказа, покупки и доставки.
Это естественное развитие технологий, в ходе которого именно вокруг поисковиков сейчас быстро нарастают цифровые экосистемы. В них игроки реального офлайнового рынка - поставщики чего угодно, от продуктов питания до кино, - предоставляют информацию о себе, ведь им это тоже выгодно.
Давид и Голиаф
Есть ли у локальных игроков хоть какие-то шансы выжить против гиганта с практически неограниченными ресурсами или это вопрос времени? История показывает, что бывает по-разному - выживший в трудные нулевые чешский Seznam сейчас теряет долю и скорее всего, близок к закату. Остальные трое показывают обратную динамику: растут по выручке, внедряют новые технологии, интегрируют в поиск все больше новых сервисов и все прочнее закрепляются в национальных интернет-сегментах.
Как в любой истории про борьбу с гигантами, секрет здесь, наверное, в том, чтобы обратить свою слабость в силу. Единственное неоспоримое преимущество локальных поисковиков - это как раз их локальность. Только местный поиск может позволить себе либо бросить достаточное количество ресурсов на создание специальных локальных сервисов (например, Naver - единственный поисковик, нашедший ресурсы на создание отдельного портала для корейских детей и подростков, учитывающий их интересы и потребности), либо на качественную интеграцию поиска с местными поставщиками данных (хороший пример здесь - городской транспорт, который интегрирован в поиск Google в США и в поиск Яндекса в России). Только владея большими и при этом специальными знаниями и создавая экосистемы на местах своего присутствия, поисковики могут конкурировать за владение оцифрованным миром будущего.