Cisco тоже не торт
Вот здесь я распинался о том, почему Cisco лучше чем Juniper. Сейчас я чё-то засомневался. Точнее даже не совсем так. Шо то фигня, шо это фигня. ©
Работал-работал у нас в одной стойке (rack) кластер из двух коммутаторов Cisco 9200L. Его никто никогда не трогал, особых проблем не доставлял. А потом начал без предупреждения творить странные вещи.
В непредсказуемый момент он берет и полностью прекращает передачу данных через себя. Пишет в логах что-то типа
%IOSXE_INFRA-6-PROCPATH_CLIENT_HOG: IOS shim client 'ngwc fed bipc' has taken 11352 msec (runtime: 0 msec) to process a 'unknown' message
и "адьес амигос". Просто "затыкает" все порты. На графике проходящего трафика это выглядит примерно так.
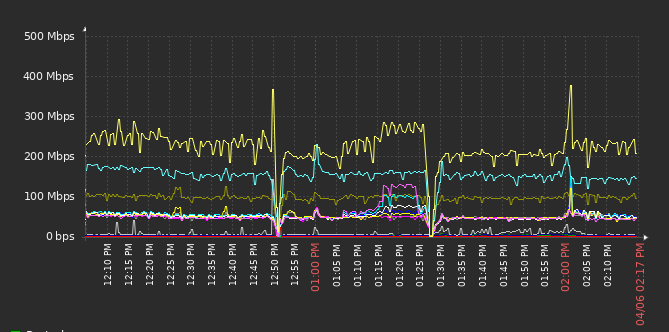
Несколько секунд тупит, потом продолжает работать. Но эти провалы успевают заметить и Zabbix, и базы данных. Чаще TCP-сессии всё таки не рвутся, но приятного в любом случае мало.
По пакетам в секунду там выходит что-то из серии 30 kpps на порт. Вроде не супер много. Но в любом случае, что это за коммутатор на**й, который вообще не держит нагрузку? Тем более, что прямо сейчас к нему подключено вообще только восемь (!) серверов.
На ресурсах цЫски удалось найти только вот это: раз, два. Насколько я понимаю, баг не новый, но его так и не пофиксили.
В общем, в очередной раз неведомая ***ная ***ня творится. Что с этим делать, опять непонятно. Только решили одну проблему с железом, и вот на тебе следующую. Мать-мать-мать, в природе вообще существует нормальное стабильно работающее железо?