Фонетический поиск для ДНК совпадений по аутосомным маркерам
Тестирование на аутосомные маркеры и сравнение этих маркеров разных людей открыло новые возможности ДНК генеалогии.
Теперь сайты вроде 23andme, familytreedna уверенно предсказывают, что такие то и такие то люди являются где то 4х-5ти юродными братьями моих протестированных родственников.
Однако же чаще всего с этой информацией делать нечего - ты пишешь потенциальному кузену и выясняешь, что в лучшем случае он знает фамилии бабушек и дедушек и знает что они приехали в Америку "из России". Что с этим делать дальше? Ты собирал свое дерево по крупицам - у тебя известны по разным веткам 8-10 поколений, известно какая ветка из какой деревни, а понять хотя бы по какой линии ты родственник с этим "савпаденцем" - не можешь.
И тут нам на помощь может придти технология.
Я написал программку, веб сервис, которой можно скармливать раные документы - например перепись населения какой то деревни за 1856 год. Или список выборщиков в гос думу другой деревни за 1910 год и т.д.
Она может принимать как текстовые документы, так и ссылки (в таком случае она выкачает документ сама).
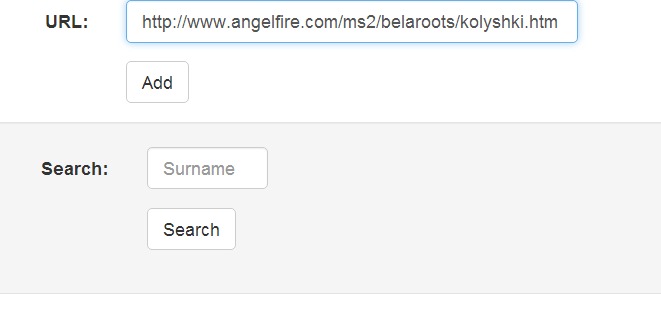
Веб сервис индексирует их, а потом, найдя очередного совпаданца, можно скармливать ему фамилии его предков и вебсервис будет искать в документах с учетом того, что одна и таже фамилия может быть записана (и услышана) по разному.
Если я нашел одну из его фамилий, например, в переписи по Свири за 1856, то можно предположить, что мы с ним связаны именно по линии прадедушки тестя, который жил именно там.
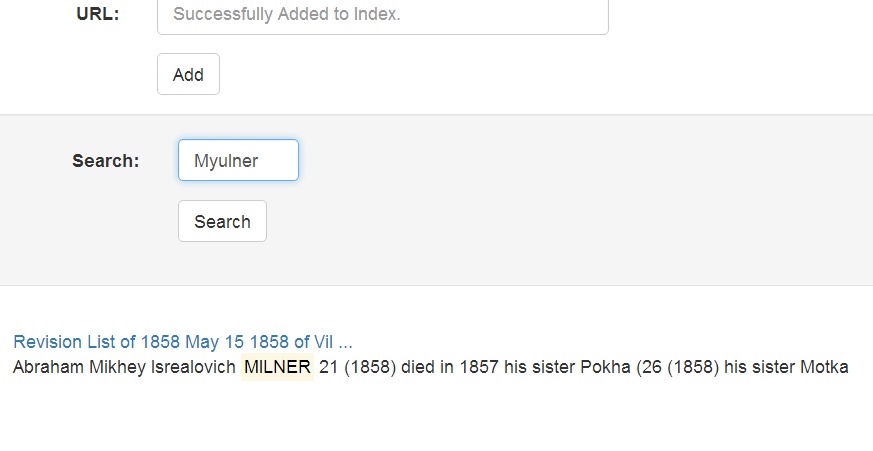
А это дает уже уйму информации - можно начинать просматривать метрические записи - искать брак между семьями и т.д.
Что дальше?
Этот вебсервис, как вы понимаете только прототип.
Как он может развиваться?
1. MyHeritage интегрирована с 23andme и у них есть доступ к разным базам данных в интернете. Они могли бы это сделать частью своего продукта - находить как (возможно) связаны сопваденцы по ДНК
2. Если бы JewishGen открыл бы свои базы по API, и 23andme сделал API на тему совпадений аутосомной ДНК (сейчас у них API есть, но ограниченый, только о себе), то можно было бы такой продукт сделать самому
3. Поиск я веду по всему документы, а в нем не только фамилии, но и имена, рассказ о документе - это может создавать false positives. API ыдавал бы только фамилии
4. Поиск по фонетике ведется с помощью Daitch Mokotoff Soundex а он не очень приспособлен для фамилий (хотя его использует и JewoshGen) - выдает много совпадений, которые не могут быть одной фамилией и наоборот. Хорошо бы сделать его вариант заточенный под европейские фамилии
Теперь сайты вроде 23andme, familytreedna уверенно предсказывают, что такие то и такие то люди являются где то 4х-5ти юродными братьями моих протестированных родственников.
Однако же чаще всего с этой информацией делать нечего - ты пишешь потенциальному кузену и выясняешь, что в лучшем случае он знает фамилии бабушек и дедушек и знает что они приехали в Америку "из России". Что с этим делать дальше? Ты собирал свое дерево по крупицам - у тебя известны по разным веткам 8-10 поколений, известно какая ветка из какой деревни, а понять хотя бы по какой линии ты родственник с этим "савпаденцем" - не можешь.
И тут нам на помощь может придти технология.
Я написал программку, веб сервис, которой можно скармливать раные документы - например перепись населения какой то деревни за 1856 год. Или список выборщиков в гос думу другой деревни за 1910 год и т.д.
Она может принимать как текстовые документы, так и ссылки (в таком случае она выкачает документ сама).
Веб сервис индексирует их, а потом, найдя очередного совпаданца, можно скармливать ему фамилии его предков и вебсервис будет искать в документах с учетом того, что одна и таже фамилия может быть записана (и услышана) по разному.
Если я нашел одну из его фамилий, например, в переписи по Свири за 1856, то можно предположить, что мы с ним связаны именно по линии прадедушки тестя, который жил именно там.
А это дает уже уйму информации - можно начинать просматривать метрические записи - искать брак между семьями и т.д.
Что дальше?
Этот вебсервис, как вы понимаете только прототип.
Как он может развиваться?
1. MyHeritage интегрирована с 23andme и у них есть доступ к разным базам данных в интернете. Они могли бы это сделать частью своего продукта - находить как (возможно) связаны сопваденцы по ДНК
2. Если бы JewishGen открыл бы свои базы по API, и 23andme сделал API на тему совпадений аутосомной ДНК (сейчас у них API есть, но ограниченый, только о себе), то можно было бы такой продукт сделать самому
3. Поиск я веду по всему документы, а в нем не только фамилии, но и имена, рассказ о документе - это может создавать false positives. API ыдавал бы только фамилии
4. Поиск по фонетике ведется с помощью Daitch Mokotoff Soundex а он не очень приспособлен для фамилий (хотя его использует и JewoshGen) - выдает много совпадений, которые не могут быть одной фамилией и наоборот. Хорошо бы сделать его вариант заточенный под европейские фамилии