Как это работает: как устроена система приоретизации заявок в сервисных подразделениях.
Представьте. Вы обратились за помощью в службу поддержки компании X. Но эти ребята как будто не замечает ваших просьб о помощи, по телефону с ними не связаться, письма остаются без ответа. Знакомо? С чем могут быть связаны подобные проблемы, и имеет ли это отношение к нерациональному распределению ресурсов в сервисных подразделениях и неправильной приоритезации обращений заказчиков? Устраивайтесь поудобнее, сегодня вы узнаете, как работает система приоретизации заявок в сервисных подразделениях!

Мы рассмотрим основные критерии повышения или понижения приоритета обращения в службу технической поддержки, механику их работы, рассмотрим в каком порядке выстраиваются заявки для сотрудников и их непосредственных руководителей.
Для начала давайте выясним, как система выставления приоритетов обращений клиентов выглядит изнутри.
Расстановка приоритетов обращений в сервисных подразделениях при работе с очередями часто вызывает вопросы. Организация должна дорасти до определенного уровня зрелости, чтобы начать придавать этому аспекту оказания услуг нужное внимание. Конечно, объем запросов должен достичь того уровня, чтобы и критерии расстановки приоритетов «созрели», и количество ошибок из-за «человеческого фактора» возросло до неприемлемых величин (что легко заметить по растущему количеству «крикливых» заказчиков и эскалаций от руководства), и экономический эффект от автоматизации процесса стал осязаемым.
Вы когда-нибудь анализировали, сколько времени затрачивается сотрудниками на рутинное администрирование бизнес-процессов в вашем подразделении? Думаю, что даже если и приходилось этим заниматься, то не слишком часто. Между тем, рутина может отнимать значительное количество рабочего времени сотрудника. Нельзя сказать, что она не важна, ведь она обеспечивает функционирование всего механизма, но, вместе с тем, такая работа не приносит и измеряемого результата, который руководство желает видеть в KPI. К примеру, в службе технической поддержки вряд ли кому-то интересно, сколько сотрудник потратил времени на администрирование заявок (то есть проставление приоритетов, заполнение служебных полей и прочее сопутствующее подкручивание винтиков большого механизма заявки в CRM-системе). На контроле, как правило, только количество обработанных и решенных заявок, результаты по проверке качества и CSAT (Customer Satisfaction). Между тем, практика показывает, что заниматься этим вопросом нужно:
Одна-две минуты на заявку * количество заявок =?
А сколько это в неделю? А в месяц? А в год?
А если умножить это количество часов на средний ФОТ сервисной службы?
У менеджеров всегда есть более важные задачи, не терпящие отлагательств, и инвестировать время в то, чтобы автоматизировать часть рутины, да еще получить согласие и поддержку смежных подразделений, чьи интересы эта автоматизация затрагивает, не всегда представляется возможным. К (не)счастью, в современной экономической модели случаются кризисы, которые стимулируют компании работать в режиме экономии и обратить свой взор к оптимизации монструозных процессов, накрученных в тучные годы. Ранее несрочные задачи по оптимизации и автоматизации процессов выходят на первый план. Так случилось и в нашей организации.
Экономическая ситуация в стране не способствует найму сотрудников под каждую новую задачу, а кризис роста в условиях экономии создает уникальную ситуацию, в которой у руководителей подразделений не остается иного выхода, кроме как заняться ревизией процессов, чтобы и сервис не пострадал, и ФОТ не разрастался.
Итак, цель - обеспечить прежний уровень KPI техподдержки в условиях роста количества обращений и ограничения найма новых сотрудников.
Задачи:
- Упрощение и унифицирование определения приоритета обращений для инженера технической поддержки;
- Обеспечение правильной очередности обработки заявок.
Проблема - работы становится больше, количество рабочих рук не растет или растет слишком медленно, требования по приоритетам не отражают реальной ситуации с большим количеством различных нюансов.
Способы решения:
- Контроль рабочего времени сотрудников (в данной статье рассматриваться не будет);
- Повышение квалификации и производительности сотрудников (тоже как-нибудь в другой раз);
- Снижение трудозатрат на рутинное администрирование процессов, в частности процесса выставления приоритетов заявкам (то, о чем и пойдет речь дальше).
В среднем сотрудник затрачивает до полутора минут на то, чтобы просто квалифицировать обращение и назначить ему правильный приоритет, исходя из определенного набора требований. Это обязательная часть процесса работы с обращениями в любом контакт-центре, от которой ни при каких обстоятельствах не избавиться. В нашем случае однажды назначенный приоритет в обращении сохранялся с ним на протяжении всей работы с заявкой и никогда не пересчитывался с учетом новых данных. Такая ситуация не требовала автоматизации, пока руководитель подразделения был в состоянии держать в голове все эскалации, поступившие от смежных подразделений, успевал просматривать все открытые обращения и применять «ручное управление» к очередности обработки заявок от заказчиков. На малых объемах в команде, где есть только один менеджер, такой подход оправдан и достаточен. Но его эффективность весьма ограничена, не подходит для компаний с двумя и более сменами, и не исключает «человеческий фактор». Всегда есть вероятность допустить ошибку, недоглядеть или просто забыть о какой-либо заявке, не вовремя сообщить коллеге из следующей смены о какой-либо эскалации. В результате таких сбоев страдают, как правило, заказчики, а это неприемлемо. В итоге мы приняли решение полностью переработать систему приоритезации заявок в техническую поддержку, максимально исключить «человеческий фактор», решить проблему «не обновляемых» показателей приоритета в кейсах.
В силу того, что CRM-система используется в компании достаточно давно, мы уже накопили приличное количество данных как о наших клиентах, так и о наиболее типичных проблемах и ситуациях в работе организации с заказчиком, заказчика с продуктом, продукта с инфраструктурой заказчика и т.п. Проконсультировавшись с коллегами по цеху и изучив опыт построения подобных систем динамической приоритезации в других компаниях, мы разработали собственную, отвечающую нашим реалиям и укладывающуюся в наши бизнес-процессы.
Решено было построить систему приоритетов в виде числовых значений от 0 до 1, где наивысшим приоритетом обладают обращения со значением приоритета «1». Они должны обрабатываться в первую очередь. Соответственно значение «0» обладает наименьшим приоритетом и попадает в поле зрения инженера технической поддержки только после обработки всех более значимых заявок. Общая схема выглядит следующим образом:

Как видим, за базис приоритета обращения были приняты существующая система SLA и особые источники поступления заявок. В нашей компании имеется три типа контрактов технической поддержки, которые предлагают заказчикам различные SLA. Каждый из таких контрактов получил свое базовое число. Это же касается и источников поступления заявки. При этом система автоматически проставляет более высокий приоритет при выборе из двух базовых. А дальше началось самое интересное. Базовые значения никак не учитывают все возможные нюансы в работе технической поддержки.
Приведу пример:
Очень большой и невероятно важный заказчик написал нам на почту с предложением изменить пиктограмму в интерфейсе. Как нам следует поступить? Должны ли мы срочно бросить все силы на поиск нерадивого дизайнера, нарисовавшего такую отвратительную пиктограмму, заставить его/ее немедленно все переделать, утвердить макет, напрячь технический департамент и без промедления выпустить хотфикс для этого заказчика?
В это же время менее крупный клиент испытывает серьезные затруднения с продуктом, из-за которых у него фактически остановился бизнес, и направляет запрос в нашу службу поддержки.
Следует ли нам понизить в приоритете первый запрос и помочь второму клиенту, пусть и не такому большому и невероятно важному, но чья проблема стоит более остро?
Согласитесь, имея в арсенале лишь ограниченное количество ресурсов, невозможно быть доступным по первому требованию сразу для всех желающих. И подавляющее большинство заказчиков это прекрасно понимают. Не станет даже самый большой и важный заказчик настаивать на немедленном решении вопроса с некрасивой пиктограммой, так как это лишь мелкое неудобство, а не реальная проблема, препятствующая нормальной работе. Поэтому расстановка правильных приоритетов в условиях ограниченных ресурсов очень важна. Не менее важна аккуратность и простота этого механизма.
Отталкиваясь от этой логики, мы дополнили базовую систему приоритезации определенными коэффициентами, активируемыми в разных ситуациях:
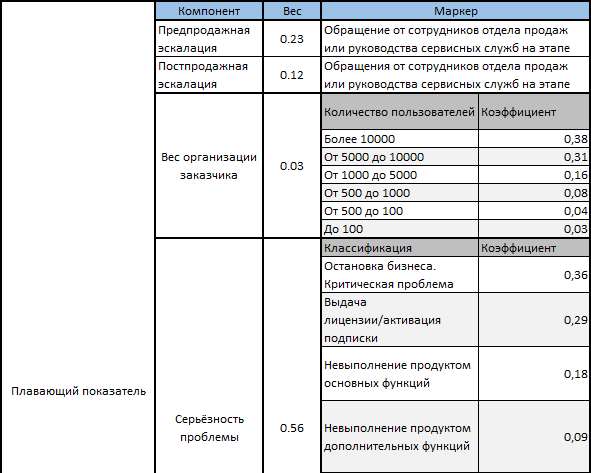
То есть конечная формула выглядит так:
Базовый показатель + плавающий показатель = Итоговое значение приоритета.
Попробую для наглядности провести расчет по приведенным ранее примерам.
Для примера №1 расчет выглядит так:
Premium SLA + Предпродажная эскалация + Постпродажная эскалация + Вес организации*количество пользователей более 10000 + Серьезность проблемы * пожелания по функциональности + продолжительность работы = 0.07+0+0+0.03*0.38+0.56*0.02-0 = 0.07+0.0114+0.0112 = 0.09 Как видите, итоговый показатель приоритета достаточно низкий, несмотря на приличные вводные данные (Premium поддержка, крупный клиент).
Для примера №2 расчет выглядит так:
Extended SLA + Предпродажная эскалация + Постпродажная эскалация + Вес организации*количество пользователей 100 + Серьезность проблемы * Критическая проблема + продолжительность работы = 0.04+0+0+0.03*0.03+0.56*0.42=0.04+0.0009+ 0.24=0.28 Здесь ситуация обратная. Несмотря на то, что организация совсем не крупная и имеет более скромный контракт на техническую поддержку, из-за высокого уровня важности проблемы значение приоритета заявки превышает заявку из примера №1.
То есть, имея в своем арсенале весь набор необходимых данных, система автоматически подняла более критичную проблему от небольшой организации над низкоприоритетной, несмотря на более высокий вес первого заказчика. Система умеет автоматически пересчитывать приоритет заявки по девяти разным параметрам, повышать базовый показатель приоритета с помощью 18 различных коэффициентов, тем самым увеличивая или уменьшая базовое число приоритета. Показатель этот не является статичным. Он изменяется при появлении новых данных в классификации обращения и мгновенно изменяет ранжирование заявок в очереди на обработку. Это позволяет нам распределять заявки именно в той очередности, в которой их необходимо обрабатывать.
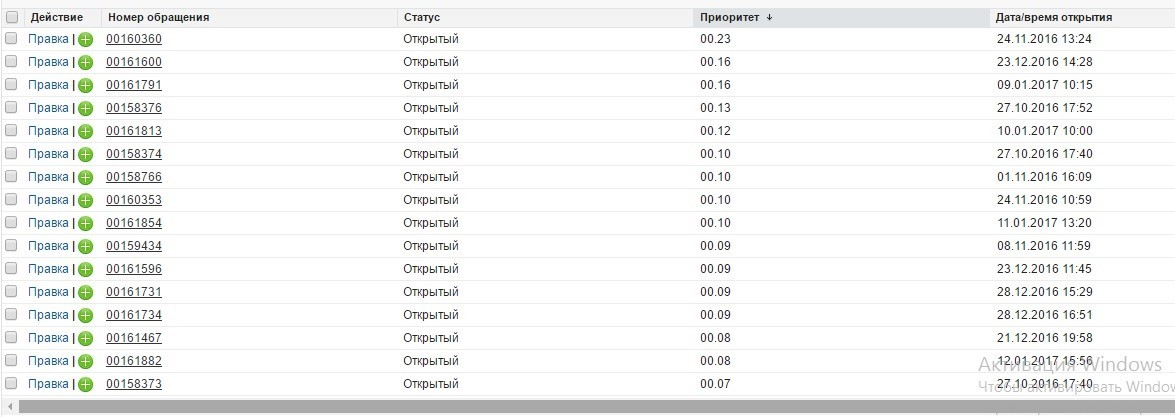
Вот так теперь выглядит очередь обращений для инженера технической поддержки. Больше нет необходимости выяснять приоритет заявки. Инженеры технической поддержки просто обрабатывают заявки сверху вниз в порядке очереди.
Как видите, при создании системы приоритезации мы постарались учесть все возможные нюансы, возникающие при обработке обращения: это и серьезность проблемы обратившегося, и SLA, который зафиксирован в договоре на техническое обслуживание, и различные виды эскалаций и даже длительность работы с обращением с момента его открытия в нашей CRM-системе. А принимая во внимание то, что большинство этих параметров проставляются автоматически, наши инженеры больше не тратят время на администрирование приоритета обращения и могут сконцентрироваться на изучении проблемы заказчика и выработке решений, быть на связи с теми, кто остро нуждается в срочной помощи. Руководителям смен больше не нужно постоянно держать в голове информацию обо всех «особых» заявках и вовремя реагировать на их переоткрытие, а заказчики могут быть уверены, что все их обращения будут обработаны в максимально сжатые сроки и никогда не исчезнут из поля зрения технической поддержки до их полного разрешения.
Новая система внедрена в нашей CRM и функционирует с начала декабря 2016 (51 неделя). За время ее пилотной эксплуатации мы уже заметили снижение количества эскалаций:

Внимательный читатель, несомненно, обратит внимание на то, что в текущей реализации никак не учитывается «Backlog». Все дело в том, что это уже следующий этап задуманной нами автоматизации. Как только механизм автоматического расчета Бэклога будет готов, мы добавим его в существующую систему приоритезации и заново пересчитаем коэффициенты. Пока же «слежка» за бэклогом осуществляется в ручном режиме. Описанию механизма расчета бэклога будет посвящён отдельный пост, после того как механизм будет полностью готов и внедрен.
В ближайшее время так же выйдет статья с подробным описанием математического аппарата расчета коэффициентов описанного выше механизма приоритезации.