Такой прикольный NLB
Originally published at vMind.ru. Please leave any comments there.
В начале июля я начал миграцию электронной почты - за полмесяца почта должна была переехать с MS Exchange 2007 на 2010. В первых числах августа миграция была закончена, но затем возник неприятный нюанс - Outlook начал периодически просить пароль. Отключение Outlook Anywhere большинству пользователей помогло, что делать с остальными мы не знали. В журналах событий даже после включения супер-подробных журналов диагностики было тихо.
Все было настолько печально, что я обратился в техподдержку Microsoft…
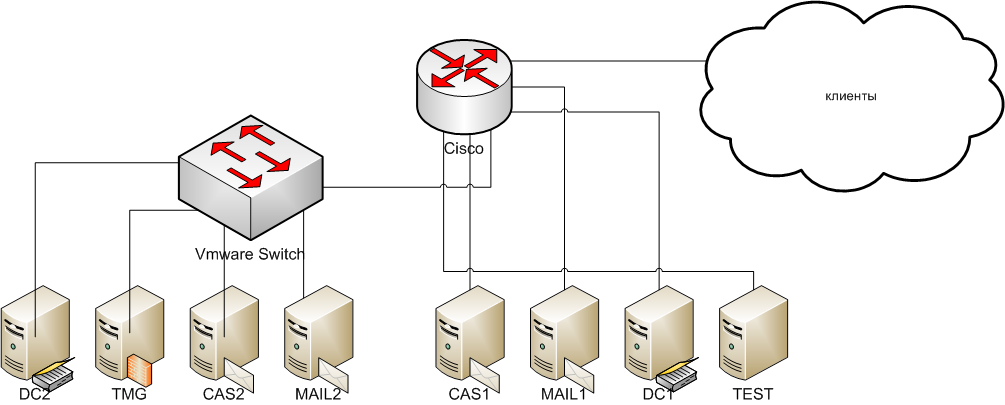
Инфраструктура выглядит следующим образом:
- все серверы находятся в отдельном VLAN;
- есть три контроллера домена, обслуживающие этот сайт AD: один железный и два виртуальных;
- виртуальная инфраструктура - VMware vSphere;
- шлюзом по умолчанию для серверной сети и клиентов является Cisco;
- почта состоит из четырех серверов: два - Mailbox (DAG), еще два - HT/CAS. CAS-сервера объединены в CAS-Array и NLB-кластер. В паре серверов один - физический, другой - виртуальный;
- доступ в интернет осуществляется через MS TMG (работающий в качестве прокси), находящийся в серверном VLAN.
Настроенный мониторинг портов показал очень странную вещь: соединения на отдельные ноды NLB-кластера проходили на ура, а вот NLB-адрес (HTTP, SMTP, POP3) несколько раз в час выдавал таймаут >2 секунд. Оставил в NLB только один узел - та же картина.
Для начала я решил разобраться, как же работает этот странный NLB. Тут же на помощь мне пришло видео с ExchangeRus. Очень рекомендую для ознакомления. Кстати, там же объясняется почему на ряде маршрутизаторов необходимо вручную создавать ARP-запись под Multicast NLB-кластер.
К этому времени тут мы уже обсудили, что в средах VMware лучше использовать Multicast.
С момента возникновения проблемы прошел почти месяц, гугл не помогал, проблема казалась нерешимой. И тут Mr.Nobody посоветовал посмотреть внутрь TCP-сессий с помощью сниффера.
В качестве тестовой станции был взят физический сервер, не являющийся членом домена. На этом сервере установлено ПО мониторинга Dude. Я скачал и установил на него Microsoft Network Monitor 3.4.
В качестве теста я создавал соединения на 25 порт (SMTP-сессию). После этого в MS Network Monitor сравнивал нормальную сессию и зависшую.
Ясности мне это не дало - в зависшей сессии после “TCP-рукопожатия” NLB-сервер отправлял пакет с флагом Reset. Почему/зачем - не ясно.
Посоветовавшись с Diz, установил вместо него Wireshark 1.6.1 и тут такое увидел:
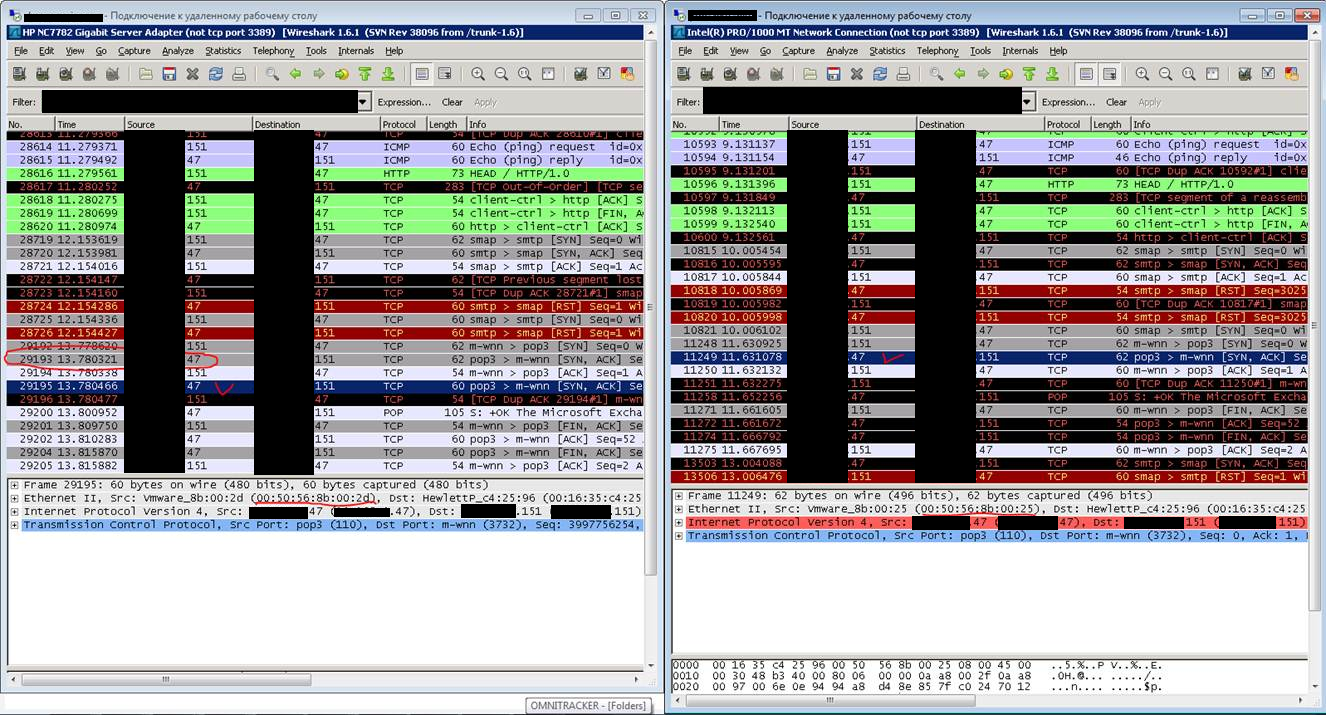
Слева - тестовый сервер, справа - активный узел NLB.
Выделенный курсором пакет идет от NLB-узла (IP=47/MAC=00:50:16:8B:00:25) до тестового сервера (IP=151/MAC=00:16:35:C4:25:96).
А слева мы видим, что сервер получает этот пакет, но MAC-адрес источника какой-то “левый”. Точнее, сервер получает два пакета от узла NLB (№№29193 и 29195). В строке №29193 - нормальный пакет с нормальными MAC’ами. Та же ерунда с пакетами от IP=151 до IP=47. IP=47 - виртуальный адрес NLB.
“Левый” MAC принадлежит TMG-серверу, который не является шлюзом ни для кого.
Для осмысления мы нарисовали картинку:
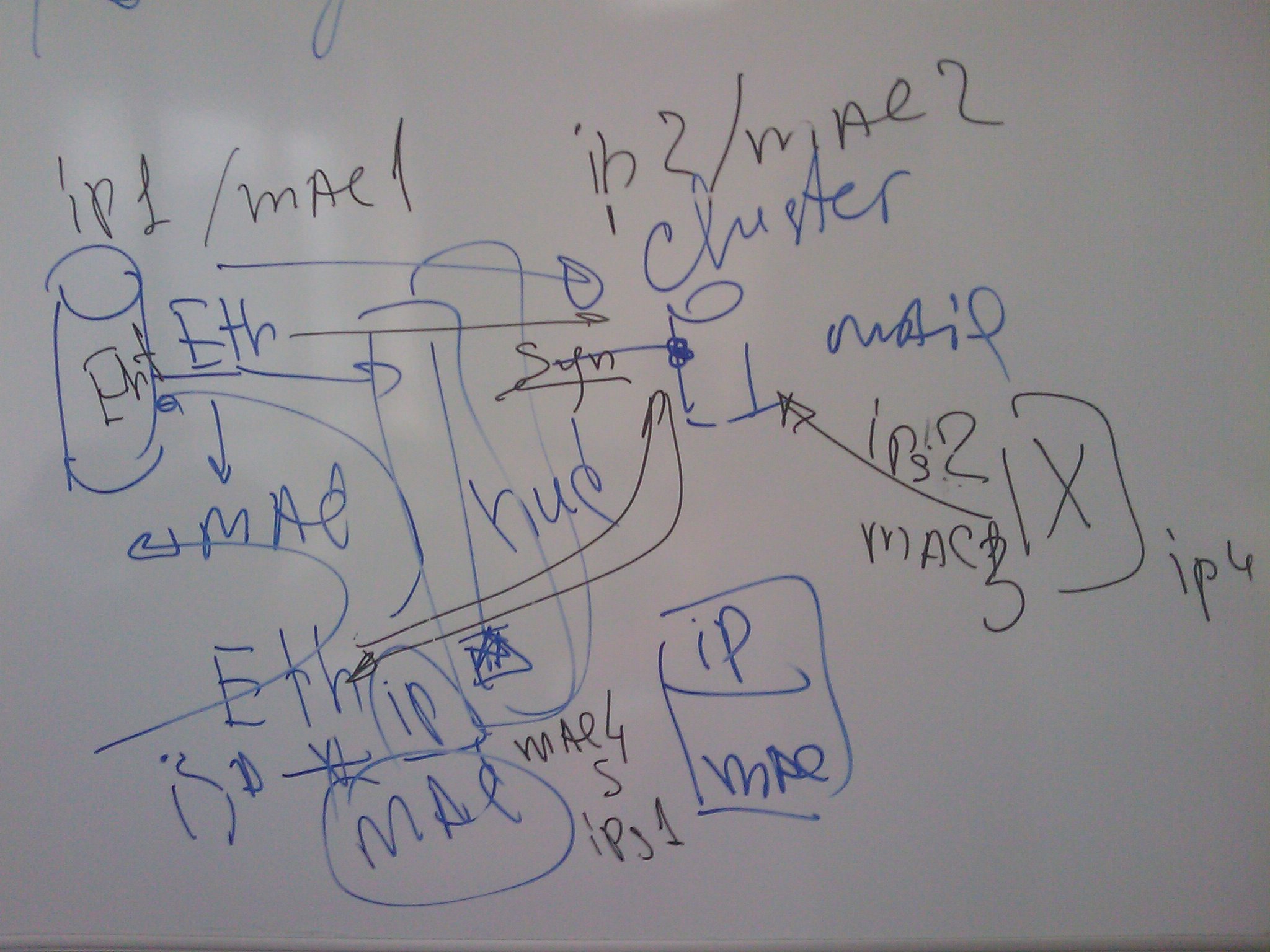
MAC1 - сервер, MAC2 - NLB, MAC3 - узел NLB, MAC4 - TMG-сервер.
В начале августа для работы почтовых клиентов Apple мы сделали на TMG правило Internal<->Internal.
Видимо, с тех пор, трафик до NLB “дублировался” через TMG-сервер, несмотря на то, что:
- TMG не является шлюзом;
- при обмене трафиком между IP=151 и IP=47 (NLB-IP) шлюз вообще не должен использоваться, так как это адреса одного логического сегмента.
А теперь интерес
Первый человек, с линками объяснивший, почему TMG пытался “маршрутизировать” пакеты, находящиеся в рамках одной сети, получит от меня электронную книгу Михаила Михеева про VMware vSphere (отсюда).