Прогноз по ИИ от Дарона Аджемоглу

Дарон Аджемоглу, очень авторитетный профессор экономики, недавно выпустил научную статью «The Simple Macroeconomics of AI».
Статью, вопреки названию, не назовешь совсем доступной - но вот ее выводы можно изложить предельно просто. ИИ, считает Аджемоглу, повлияет на экономику чуть менее, чем никак. Забудьте про всякие там технологические революции. В ближайшие 10 лет вклад ИИ в рост совокупной факторной производительности составит не больше 0,66% - то есть микроскопические 0,064% в год. Скорее всего, эти цифры даже будут ниже.
Выводы весьма обескураживающие. И очень контрастирующие с радужными картинами, которые рисуют ИИ-визионеры, и с планами ведущих исследовательских лабораторий создать общий ИИ к 2027. Кто же прав? Авторитетные скептики или же ИИ-стартапы, прожигающие сейчас кучи денег и отчаянно нуждающиеся в продолжении хайпа в отношении ИИ?

Как обычно, для установления истины нам придётся залезть поглубже в представленный экономический прогноз и выяснить, на чем базируются расчеты его автора. Начнем!
Для того, чтобы посчитать экономический эффект от проникновения ИИ, необходимо оценить, насколько далеко этот самый ИИ может проникнуть. Другими словами, какую долю задач может взять на себя новая технология.
Здесь Дарон Аджемоглу не пытается изобретать велосипед и опирается на работу «GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models», сделанную экономистами из ”OpenAI”. И тут внимательный читатель сразу может увидеть нестыковку: Аджемоглу делает широкие выводы по всем технологиям ИИ, в то время как ”OpenAI” считали только эффект от больших языковых моделей. Очевидно, что такая подтасовка сильно занижает потенциальный эффект.
Дальше - больше. Как ”OpenAI” определяло, влияет большая языковая модель на рынок труда или же нет? Брались отдельные трудовые задачи, и эксперты определяли, может ли «самая мощная языковая модель», которая умеет принимать текстовые инструкции на входе и давать текст на выходе, ускорить выполнение этой задачи на 50% и более.

Профессии с самой высокой замещаемостью языковыми моделями, согласно исследованию "OpenAI". Альфа, бета и гамма соответствуют разным градациям влияния ИИ (см. ниже). "Human" - экспертная оценка, "Model" - оценка силами GPT-4. Согласованность между человеческими и машинными оценками была высокой.
Здесь мы можем указать на несколько моментов, занижающих потенциал внедрения больших языковых моделей. Во-первых, исследование проводилось практически перед самым выходом модели GPT-4. То есть эксперты были еще не слишком хорошо знакомы с моделью, а широкая публика, которая способна гораздо лучше исследовать границы ее способностей, и вовсе не имела к ней доступа.
Во-вторых, исследование предусматривало несколько градаций степени влияния. Для «основной» категории языковая модель должна была быть способна ускорить задачу только на основе короткой, до 2000 слов, текстовой информации. Для «расширенной» категории модели позволялось пользоваться инструментами, которые на момент проведения исследования, в начале 2023, считались передовым краем технологий. Например, это расширение контекста больше 2000 токенов, использование веб-поиска моделью и retrieval-augmented generation. Наконец, в особую категорию попадали задачи, которые можно было решить с помощью еще одной «передовой» технологии - мультимодальности (а именно, использование изображений наряду с текстом).
То, что в начале 2023 считалось «передовыми» инструментами, сейчас считается тривиальным. Но тогда новизна и неопределенность этих методов должна была сильно мешать экспертам справедливо оценивать потенциал моделей.
Дарон Аджемоглу в качестве базовой метрики применимости ИИ выбирает задачи из «основной категории» плюс 50% задач из «расширенной» категории. И если 50%-ный коэффициент в начале 2023 был оправдан в силу неясных перспектив новых методов, то сейчас его обосновать трудно. Это снижает долю задач, затронутых ИИ, с 47% до 31%.
Какие задачи упускает из вида такая классификация? Посмотрим на конкретный пример:
“Задача: Отрегулировать, очистить или отремонтировать изделия или технологическое оборудование для устранения дефектов, обнаруженных во время проверок.
Категория: E0 [не подвержена влиянию ИИ]
Пояснение: Модель не имеет доступа к каким-либо физическим средствам, и более половины описанных задач (настройка, чистка и ремонт оборудования) требуют выполнения вручную или в другом варианте”.
То есть мы видим, что задачи, требующие хотя бы минимального физического действия, сразу исключаются из списка затронутых ИИ. По сути, такая классификация наступает на те же грабли, что и разобранное нами ранее исследование МВФ. Тогда мы говорили о шаткости этого тезиса. Успешные эксперименты, в которых гуманоидные и промышленные роботы сопрягаются с большими языковыми моделями, еще надежнее свидетельствует о практичности применения машин в физических задачах.
Но, пожалуй, самый критический недостаток использования этой классификации заключается в том, что она подразумевает статичные способности языковых моделей. Что GPT-4 - это потолок. Что в ближайшие 10 лет ничего лучшего уже не будет. Это попросту смехотворная предпосылка. За год с небольшим, прошедшие с момента публикации статьи ”OpenAI”, мы уже успели привыкнуть чуть ли не к ежемесячным новым достижениям моделей. Нет никаких причин, по которым этот темп должен серьезно замедлиться - не говоря уже о полной остановке прогресса.

Итак, единолично остановив прогресс в ИИ, Аджемоглу подсчитывает, какую долю в экономике занимают затронутые ИИ-задачи. Причем те задачи, где эффект ИИ влечет рост производительности меньше, чем на 50%, он вовсе выбрасывает из расчетов. В итоге Аджемоглу получает, что ИИ способен повлиять на задачи, составляющие 20% ВВП США.
Оценка довольно скромная. Например, уже упомянутое исследование МВФ получило, что в США ИИ угрожает 60% занятости. Однако не стоит торопиться - Аджемоглу еще не выложил все свои козыри.
Следующим козырем от Аджемоглу становится аргумент, что далеко не всё из того, что может ИИ, будет экономически привлекательным. ИИ нужно не просто уметь выполнять трудовую задачу - но делать это дешевле, чем человек.
Аргумент, безусловно, справедливый. А вот количественные выводы из этого аргумента… Количественные выводы базируются на работе «Beyond AI Exposure: Which Tasks are Cost-Effective to Automate with Computer Vision?». Которую я, по счастливому стечению обстоятельств, уже имел удовольствие разобрать в начале этого года. TL;DR того обзора можно свести к тому, что не всё так однозначно, и что исследованные сценарии позволяют получить широкий спектр оценок экономической привлекательности машинного зрения.
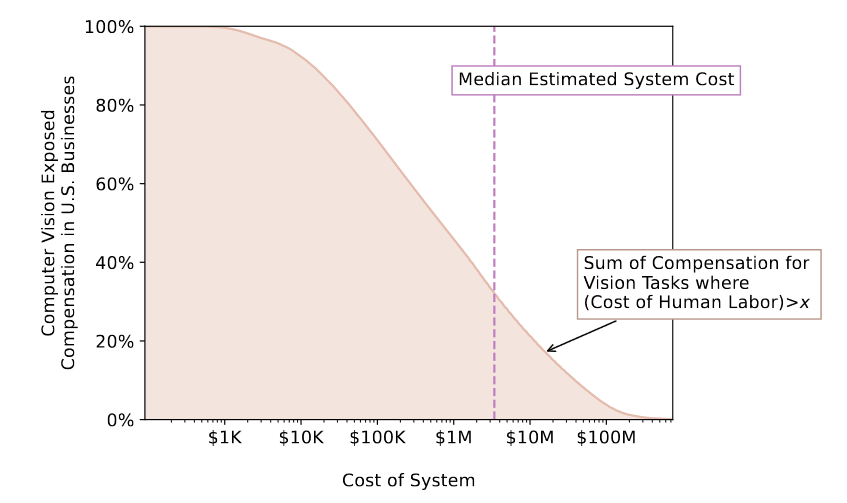
Но козырь Аджемоглу настолько прям, что начинают закрадываться сомнения, что профессор подгоняет задачу под заранее известный (ИИ-скептический) ответ. Он берет из упомянутого исследования оценку по нижнему пределу, 23%, и объявляет, что именно столько задач будет экономически оправдано поручить ИИ.
Его не смущает, что это оценка для задач машинного зрения, в то время как он базировал свои расчеты на задачах для больших языковых моделей. Его не смущает, что перед этим он выкинул из расчетов ровно половину трудовых задач, которые могли требовать визуальный контент. Его не смущает, что более реалистичный сценарий внедрения моделей машинного зрения повышает долю экономически оправданного внедрения сразу до 85%.
Нет, гораздо же проще перемножить 20% выполнимых ИИ задач на 23% экономических рентабельных и получить, что экономический эффект от ИИ бодро идёт в нужную сторону. Вниз.
Но даже эти 4,6% экономики, в которые, по мнению Аджемоглу, будет осуществимо и выгодно внедрить ИИ, выглядят для него слишком большой цифрой. Поэтому надо применить к ней больше поправок. Например, какой именно выигрыш даст там ИИ?
Ну, то есть базовая классификация от ”OpenAI” уже подразумевает, что производительность труда в этих задачах растёт минимум вдвое. Однако для Аджемоглу это чересчур много. Поэтому он ищет экспериментальные свидетельства того, что эта экономия будет ниже.
И находит. Первый экспермент, использование GitHub Copilot программистами, показывает внушительное ускорение: люди выполняют задачу на 55,8% быстрее. Второй эксперимент - использование ChatGPT для написания пресс-релизов и т. п. Здесь получают ускорение на 40%. И вдобавок рост качества написанных текстов.
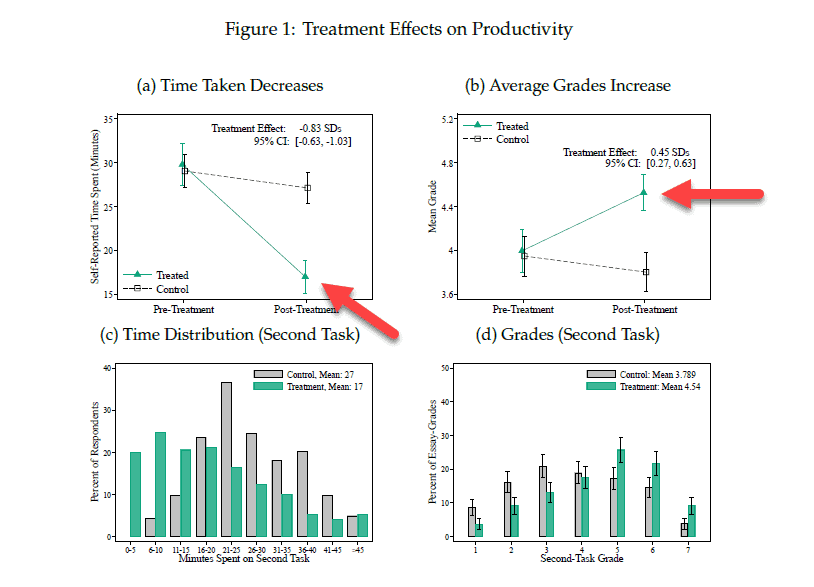
График из экспермента с ChatGPT. Ускорение производительности нагляднее всего видно на панели (с), где показано распределение участников по времени выполнения задачи
Наконец, третий эксперимент - использование некой проприетарной системы для клиентской поддержки. Здесь ускорение работы скромнее - на 14%.
Все три эксперимента объединяет пара особенностей, вновь недооценивающих эффекты от ИИ. Во-первых, во все трёх случаях системы статичны - они не улучшаются ни на основе фидбека от пользователей, ни в результате прогресса в фундаментальных ИИ-моделях. Поэтому было бы странно переносить их количественный эффект на всё предстоящее 10-летие.
Во-вторых, в большинстве случаев пользователи были не знакомы с новой технологией до старта эксперимента. А ее освоение требует определенного времени, обмена опытом с коллегами и т. д.
Наконец, выбор между тем, должны ли мы больше верить: экспертной оценке 19,2 тыс. трудовых задач или же эмпирике по 3 (трем) экспериментам, является далеко не тривиальным.
Ну, нетривиальным он является для тех, кого интересует объективная истина. Для Аджемоглу же выбор тривиален: возьмем то, где эффект будет ниже. Ниже он получается по итогам усреднения двух самых низких значений экспериментов. Почему только двух, а не трех? Потому что программирование - это задача, для которой GitHub Copilot тренировался специально, а значит, это типа не считается. Да, я не шучу. Экономический эффект резко теряет смысл в глазах Аджемоглу, если модель «читерски» специализируется на одной задаче. Интересно, экономический вклад людей, которые тоже, как правило, специалисты, мы тоже должны полностью игнорировать?…
Итак, натянутое среднее равняется 27%. Умножаем его на долю труда в издержках, 53,5%. Умножаем на долю ВВП, затрагиваемого ИИ. И выходим на 0,66%, о которых шла речь в самом начале поста. За десять лет. Впрочем, чего мелочиться - прогресс в ИИ профессор Аджемоглу своими героическими усилиями остановил, поэтому и через 20, и через 30 лет нам ничего большего от искусственного интеллекта не светит.
Опьяненный своей победой над искусственным интеллектом, Аджемоглу не останавливается и продолжает закидывать читателя новыми аргументами о ничтожности влияния ИИ на экономику. Так, он утверждает, что монополия/олигополия крупных корпораций над ИИ-инструментами может снизить инвестиции малых и средних фирм в это направление, что замедлит внедрение ИИ еще больше. (Хорошо, но сильно ли замедлили монополии «Майкрософт» и «Интел» внедрение компьютеров в малом бизнесе?)

Кроме того, Аджемоглу указывает, что эффект цифровых технологий на производительность имеет вид J-кривой. И сейчас, в ближайшие лет 20, мы будем висеть на «нижней» части крючка - то есть рискуем не увидеть даже 0,66%-ного роста.
Наконец, профессор уверен, что многие задачи, которые ”OpenAI” пометила как ускоряемые с помощью языковых моделей, на самом деле будет сложно автоматизировать. А нынешние примеры автоматизации сплошь подпадают под категорию легко автоматизируемых. И поскольку сейчас ставят эксперименты только с «низковисящими плодами» - они совсем не гарантируют, что до «высоковисящих плодов» будет легко дотянуться.
Поэтому, заявляет Аджемоглу, осетра надо урезать дальше. Он классифицирует задачи на «легкие» и «сложные». В последнюю категорию попадают такие действия, как «участвовать», «советовать», «инструктировать», «диагностировать», «обучать», «нанимать», «представлять», «свидетельствовать» и «заботиться». Почему именно эти действия будут сложными - автор работы не объясняет.
К этой классификации добавляется еще два варианта - один такой же произвольный, другой на основе лексического анализа - и из них выводится окончательное деление задач. В «легкую» категорию попадает 72,6% (взвешенных по вкладу в ВВП) задач, остальные относят к разряду «сложных».
Но как посчитать экономический эффект от автоматизации «сложных» задач? Ведь Аджемоглу ввёл их в свою работу только на том основании, что в эти задачи еще никто не начал внедрять ИИ, т. е. эмпирические данные взять неоткуда.
Не проблема, говорит нам Аджемоглу. Мы возьмем самый низкий эффект на производительность из наших трёх экспериментов, клиентскую поддержку с 14%. Это типа «легкая» задача. А сложная… ну пускай будет в 2 раза меньше. 7%. Вот такая у нас научно обоснованная методология.
С такой изящной поправочкой ежегодный эффект ИИ на производительность сползает еще ниже, до 0,053% в год. Куда уж ниже. Методология и так получается шаткой до предела.
Но Аджемоглу не успокаивается и на этом. И достаёт из чулана пугало «негативных эффектов от ИИ». Какие это эффекты? Например, зависимость пользователей от ИИ-продуктов, манипуляции типа фейк-новостей или кибератаки. Эти эффекты негативно влияют на благополучие людей, напоминает нам Аджемоглу. Правда, он не напоминает нам, что никто и никогда не включает эти эффекты в макроэкономические расчёты. Равно как и расчёты выше по производительности не включают никаких внеэкономических эффектов, повышающих благосостояние (а таких тоже можно придумать немало). Но раз перед Дароном Аджемоглу стоит задача опустить значимость ИИ ниже плинтуса - почему бы не использовать такой асимметричный подход?
Поскольку негативные эффекты от ИИ никто не считал, начинается новый эпизод насилования методологии. Аджемоглу находит исследование «денежной ценности» сервисов ”Instagram” и «ТикТок». В нем пользователей спрашивали, сколько они готовы платить за пользование сервисом. В среднем получилось $53 в месяц. Но еще один вопрос касался суммы денег, которую бы они заплатили, чтобы опрашиваемый и всё его социальное окружение вообще отказались от использование соцсети. Грубо говоря, за то, чтобы этой соцсети не существовало. И получили, в среднем, 19 долларов в месяц.

Аджемоглу берет эти цифры, касающиеся только соц. медиа, весьма гипотетические, полученные на узкой группе респондентов (студенты одного из американских колледжей). И экстраполирует их на всю ИИ-экономику целиком. То есть на каждый доллар выгоды от ИИ у него получается 36 центов «негативных эффектов».
Кажется, на этом всё. Взяв за базу для исследования ограниченную область машинного обучения, объявив прогресс в ИИ завершенным, всеми правдами и неправдами занизив потенциальный эффект от ИИ и на ходу изобретя внеэкономические «негативные эффекты», Дарон Аджемоглу в итоге приходит к тому, к чему он так старательно пытался прийти: околонулевому влиянию ИИ на экономику.
Что ж, мы можем похлопать Аджемоглу по плечу. Свою точку зрения он подтвердил. Не сказать, что убедительно, но, по крайней мере, наукообразно. У ИИ-скептиков теперь появился авторитетный источник, которым они могут обосновывать свои прогнозы.
Ради справедливости надо сказать, что у ИИ-визионеров источников такой степени авторитетности нет вовсе. Мэйнстримные экономисты очень консервативны в своих прогнозах по поводу ИИ. Я не думаю, что методология популярных «революционных» прогнозов, например от «МакКинси» или ”PwC”, существенно сильнее, чем у Аджемоглу. Вполне вероятно, что она даже слабее.
Поэтому, друзья, ответ на вопрос, которым мы открыли этот пост - кто прав, скептики или оптимисты - скорее всего состоит в том, что ошибаются и те, и другие. Да и вообще, прогнозирование - неблагодарное занятие. Вдвойне неблагодарное, когда дело касается быстро развивающейся технологии.
Но всё-таки в нашем случае скептики оказываются в более выигрышном положении. Если ИИ «не взлетит» - они могут с важным видом хвастаться: я же говорил! А если нас всё-таки ждёт ИИ-революция, и все, включая профессорский состав, потеряют работу… Что ж, тогда ИИ избавит скептиков от необходимости писать невразумительные научные статьи, полные несоответствий, натяжек и взятых с потолка цифр.
_______________________________________________________________
Друзья, я начал вести канал в Телеграм: Экономика знаний. Подписывайтесь!