XML
Последние две недели жизни чего-то как-то оказались неразрывно связаны с разичными вариантами xml разметки. Точнее - с разнообразными проблемами и глюками при использовании XML.
Кто не знает - xml это ткой язык разметки, предназначен для легкого структурирования каких-либо данных. Язык гибкий в том смысле, что нет заранее оговоренных тегов для этих данных, есть только описание структуры и принципов.
Задумка хорошая, но...
Но так как нет жестко заданной структуры этих самых данных, данные записанные в xml одной программой, не сможет читать другая. Потому что только от программиста зависит, какими тегами он оденет эти самые данные.
Простой пример:
Александр Александрович Александров
Александр Александрович Александров
Обе записи легитимны в рамках общей спецификации xml. Но если программа, читающая данные, ожидает тег name для записи в базу имени, встретив тэг imya, она не поймет что там записано, а значит просто проигнорирует эти данные, согласно тем же спекам xml.
То есть - в рамках одной среды ПО теги должны быть заданы жестко. Если прининающая сторона ожидает name, то передающая должна писать name, а не imya, fio или что там другое на душу кодеру ляжет.
И тут начинается простор для пиздеца.
Есть такая штука - ЕГИССО. Не путать с ЕГАИС, что тоже сам по себе тот еще пиздец.
Единая государственная (а как жешь, у нас сейчас любая система едина и государственна) информационная система социального обеспечения.
В данную систему необхъодимо было внести до 1 июля (1 июля вообще какой-то знаковый день в этом году, что только не произошло в этот день) порядка 1200 человек - сведения вида ФИО, документ, которым назначена выплата, саму выплату, включая ее размер и чем она выплачена (натурой, да), документ удостоверяющий личность... Ну и так далее.
Девочки набирают всё это в некоем ПП (продукте, блин) под названием ЕГИССО ассистант.
Набрали, начинаем выгружать. Выгружается некий xml на 800 килобайт. Загружаю его на сайт ЕГИССО - ошибка.
Начинаю ковырять. Обновляю программу до последней версии - ошибка.
Выгружаю xml с самого сайта, сравниваю - и офигеваю. Потому что вроде бы выглядит одинакого - теже данные, та же структура. Но - разные тэги разметки.
Если программа выгружает с разметкой вида
Александр
то с сайта выгружаются теги вида:
Александр
Вопросы "как?" и "нахуя?" остаются чисто риторическими, потому что никто не знает. Поиск гуглем о проблемах загрузки выводит на какой-то партизанский форум (здесь слово партизанский - это от названия города, а не от подпольности форума, хотя судя по тому, что инфы по этому ЕГИССО исчезающе мало, возникает впечатление, что всё намеренно держится в секрете, и только на партизанских форумах тайком энтузиасты что-то расследуют и делятся опытом)
Правда, ни одно из тех решений, что предлагались там не сработало.
Пробую привести выгруженный из программы xml к виду того ,что выгружается с сайта. Полдня ковыряю теги, меняю их на соответствующие сайтовским - не помогает, всё равно ошибка структуры.
В результате этого девочки в 4 головы неделю набирали этих 1200 человек на сайте, выгружали их в файл, который подписывали, и снова загружали на сайт.
Как была написана эта программа - вопрос остается открытым. Но из-за несоответствия этих самых тэгов вся работа в ней оказалась бесполезна. Псу под хвост.
Кстати, подписание файла для загрузки в ЕГИССО - это тоже отдельная тема. Потому что, если файл подписать неверной подписью, то в возникаюшей ошибке нет ни слова о том, что подпись неверна. В ошибке написано "ошибка при передаче архива". И сиди и догадывайся, какого хрена происходит. Как вычислить, что "ошибка при передаче архива" это на самом деле "ошибка - сертификат подписи неверен, потому что не содержит сведений об ИНН, ОКАТО, и ещё каких-то необходимых сведений" - это проблема из области эзотерики, а не сисадминства.
Кто в IT работал, тот в цирке не смеётся.
Есть такой сервис у Росреестра - туда отправляется запрос по земельному участку, оттуда приходит ответ. Для отправки запроса на сайте необходимо заполнить 4 страницы разнообразных сведений об участке, владельце, запрашивающей организации, человеке, который запрашивает сведения от имени этой организации... - короче много разных данных. В том числе к запросу нужно приложить файл с доверенностью от организации, в коротой она доверят конкретному человеку делать такие запросы. Файд доверенности должен быть в формате xml и иметь подпись в формате sig.
Уже страшно.
Страшнее стало, когда меня попросили сделать эти доверенности в формате xml из формата pdf.
Как? Я вообще не представляю, как это можно сделать. Звоню в росреестр на техподдержку, там вежливо отвечают. Говорю - так и так, вы требуете доверенность в xml, не подскажете ли, где вообще такое можно сформировать? Девушка отключается на пару минут, потом "спасибо за ожидание, мы таких справок не даем."
Офигительно. Значит, мы требуем это, но где это взять и как сделать, не скажем.
Поди туда, не знаю куда, принеси то, не знамо что.
Вот как, спрашивается, из файла pdf, в котором вообще графика - скан этой самой доверенности, можно сделать xml?
Элементарно, Ватсон.
Я офигел.
Потому что когда я сказал об этой проблеме тем, кто меня попросил, мне ответили, да что там делать!
Мы бы и сами сделали, но нам некогда. Вы просто наберите в гугле преобразовать в xml, и мы там нашли и все сделали, просто нам сейчас некогда.
Я набрал. Действительно, полно сервисов по онлайн преобразованию pdf в xml.
Взял первый же бесплатный, который нашел, запихал туда pdf, на выходе получил xml. Обалдеть.
Полез в этот самый xml посмотреть, что там за такое, потому что вопрос "как?" душу терзает. Это этим всё равно, преобразовал и преобразовал, хорошо, хоть не додумались тупо сменой расширения у файла сменить его формат, а мне же надо знать - каким, сцуко, макаром, может получиться xml из, сцуко, pdf.
Судя по тегам, которые я там увидел, pdf прогоняется через libre office. C форматом pdf я особо не разбирался, но, судя по всему, структура его очень похожа на структуру xml, потому что в разметке результирующего файла я увидел теги, описывающие шрифты, поля, и так далее. А сам скан доверенности там лежал тупо в виде текстовой кодировки бинарных данных, скорее всего UUENCODE, который используется для передачи файлов в сообщения email.
Вот так вот. Вуаля.
Хрен бы я когда догадался набрать в гугле запрос про преобразование pdf в xml.
Многие знания - многие печали.
А вот хрена там. Я знаю много, а теперь еще чуть больше.
А вообще - знатный замут получился, конечно. Всё равно, как вдруг подошли и сказали - нам надо срочно из брюк рубашку сделать. И чтоб надевалась как брюки - через жопу.
Оно и возможно, вроде как. И в тоже время сюрреализм запроса понимаю только я, а кому-то это не сложнее оказалось, чем конвертнуть mp3 в mkv путём замены расширения у архива, где лежат вообще ogg.
У 1с закончилась поддержка конфигурации зарплата и кадры бюджетного учреждения редакции 1.
Закончилась и закончилась, переехали на редакцию 3.
А в новую редакцию надо загрузить КЛАДР, классификатор адресов.
Раньше кладр выкладывали на сайте налоговой в формате dbf. Старом, добром формате dbf, ведущим начало со времён ДОС, и СУБД Dbase II и III.
Занимало всё это добро по России 40 мегабайт в архиве.
Сейчас выгрузка адресных данных переезжает на формат ФИАС. 1c теперь загружает адресный ксассификатор только в этом формате.
Пока я искал, где взять нужные для загрузки в 1с файлы (как оказалось, они выкладываются на сайте 1с, с разбивкой по регионам, что очень хорошо, особенно в свете последующего текста. КЛАДР по Приморскому краю в формате FI, который использует 1с, занимает всего 2 мегабайта. Полный архив по всем регионам - 275 мегабайт.
Много это или мало?
Полная БД ФИАС, выложенная на сайте nalog.ru в формате xml занимает 7 гигабайт. В архиве.
Внимание, по буквам:
Семь
гигабайт.
В архиве.
Можете сами проверить - http://fias.nalog.ru/Updates.aspx
В самом же архиве лежат xml файлы. Это логично.
Вот они:
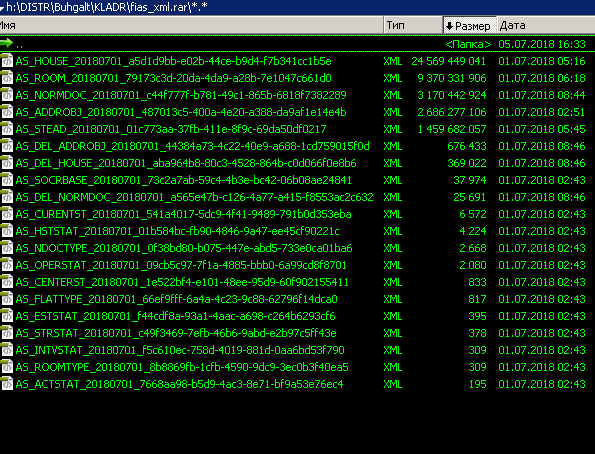
Я отсортировал их по размеру.
И да, глаза вас не обманывают.
Первый файл имеет размер в 24 с лишним гигабайта. Потом в 9 гигабайт, 3 гигабайта... и так далее.
24 гигабайта. Текстовый файл. Это вообще за гранью добра и зла.
Как и нахуя?
Загнлянуть в 24 гигабайтного монстра я не смог - notepad++ сообщил мне, что он не сможет работать с таким объемом.
Я залез в более мелкий файл - AD_SOCRBASE_*.xml, размером 37974. Чисто посмотреть - что там за.
Вот кусок из него:
....
То есть единственная разница между ini файлом и данным xml фактически - это наличие в каждой строке тега AddressObjectTypes
Ну и стандартный xml заголовок, и два тега общедокументых - открывающий тело данных, и закрывающий его.
Вопрос - зачем городить огород, засоряя файл ненужной информацией? Только ради того, чтобы написать гордо - Мы используем xml!!!
Я убрал теги из файла, просто ради проверки, насколько уменьшиться его объем. Файл стал меньше на четверть.
То есть четверть информации просто бесполезна, излишняя нагрузка на сети передачи данных.
Косвенно это потдвержается тем, что рядом для скачивая выложен КЛАДР В формате ФИАС, но не в xml, а в dbf. И архив с этим форматом занимает 5 гигабайт. Его я не скачивал, поэтому не могу сказать, какого там размера дбэфки лежат, немаленькие, само собой, но разница в размере архивов даже наводит на мысли о том, что примерно 30% информации в xml варианте тупо избыточна, а значит не нужна. Это вот эти самые тэги разметки.
В википедии в статье про xml написано следующее:
Другая ситуация, когда форматы XML могут оказаться не лучшим решением - работа с данными с простой структурой и небольшим по объёму содержанием полей данных. В этом случае доля разметки в общем объёме велика, а программная обработка XML может оказаться неоправданно затратной, по сравнению с работой с данными более простой структуры.
Вот это как раз такой случай. Неоправданные затраты на обработку и передачу данных.
Ещё вчера наткнулся на то, что одна из рабочих прог хранит свои настройки в xml файле. Ну всмысле на на сам факт хранения в xml, а на структуру его посмотрел.
Структура оказалась такая:
AppStyling
MSOffice
DataSourceType
MSSQL
DataBase
basename
UserName
user
Server
192.168.0.1
То есть в теге идет название параметра, в следующем таком же теге его значение, название, потом значение...
Весь смысл хмл идет козе в трещину.
Логично было бы сделать так:
MSOffice
MSSQL
И так далее.
И места меньше, и какая-то логика присутствует.
А здесь использование xml ради просто того, чтобы использовать xml.
Индийское программирование, сделано в России.
Вывода не будет. Пиздец, он везде пиздец, в том числе и в бездумном использовании чего просто ради того, чтобы это использовать.
Для этого уже давно есть пословица - Микроскопом гвозди забивать.
Зачем усложнять сущности?
Данный пост использует разметку xml. Чисто ради того, чтобы её использовать, без определенной цели.