Структура ETL-процесса: взгляд разработчика...
Статья Евгения Островского "Порядок разработки ETL-процессов" показалась мне интересной в том плане, что он дает свою интерпретацию того, как правильно строить ETL-процессы при разработке ПО собственными силами. При всем уважении к ведущим производителям ETL-продуктов, потребность в собственных разработках, по моему мнению, в силу разных причинах все же остается. Во всяком случае, для бизнес-аналитика такая потребность всегда будет насущной, хотя бы по причине необходимости подготовки процессов для их автоматизации на базе более серьезного продукта...
Здесь я пытаюсь осмыслить первую часть статьи, посвященную структуре ETL-процесса...
Процесс
В общем случае, программист ETL может представлять себе архитектуру ХД в виде совокупности трёх областей: источник данных (совокупность таблиц оперативной системы и дополнительных справочников (классификаторов, таблиц согласования), позволяющую создать многомерную модель данных с требуемыми измерениями), промежуточная область (совокупность таблиц, использующихся исключительно как промежуточные при загрузке ХД) и приёмник данных. Движение данных от источника к приёмнику называют потоком данных. Необходимые потоки данных формирует и описывает аналитик.
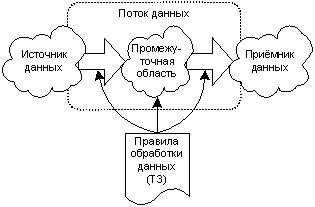
Таблица 1: Основные стадии процесса загрузки данных
Процесс перегрузки данных - это реализация потока данных от единственного набора данных источника до одного или нескольких наборов данных ХД.
Различают следующие классы процессов:
1. По характеру загрузки:
a. Процесс начальной загрузки (Initial load)
b. Процесс обновляющей загрузки (Refreshing load)
/* chevalry: что имеется в виду? Вероятно то, что в промежуточной области могут существовать какие-то готовые шаблоны, конструкции, где могут происходить обновляющие загрузки из источника данных */
2. По виду источника данных:
a. SCF (источник данных - стандартный классификатор Datagy, чаще всего - структурированный текстовый файл)
b. UCF (источник данных - стандартный классификатор оперативной системы, пользовательский классификатор)
c. MLR (источник данных - RDS или таблица фактов оперативной системы)
d. DWH (источник данных - хранилище данных)
/* chevalry: тоже немного темное место. Разные бывают источники данных - начиная от плоской таблицы или текстового файла и кончая сложной, хорошой струкутурированной базой данных. Как это все классифицировать - не совсем понятно */
Процесс перегрузки данных включает в себя одну или несколько фаз, которые выполняются по очереди, в зависимости от типа фазы.
Фаза
Фаза процесса перегрузки данных (подпроцесс, обеспечивающий решение определённой задачи в рамках ETL-процесса) соответствует стадии загрузки источника данных, то есть количество используемых фаз ограничено стадиями, которые должен пройти набор данных источника, чтобы быть загруженным в ХД.
Фаза состоит из шагов и может включать операции управления выполнением перегрузки. Управление выполнением заключается в анализе количества записей в ключевых таблицах и флагов состояния, и реализуется с помощью языка скриптов утилиты SQLExecutor.
/* chevalry: на мой взгляд, фаза - это не только перегрузка данных (то бишь выгрузка и загрузка), но также и промежуточные фазы нормализации, очистки и преобразования данных.
*/
Шаг
Шаги представляют собой отдельные SQL-запросы, которые выполняют единичные действия по перегрузке, преобразованию и выборке данных.
Каждый запрос (равно как и скрипты фаз и процессов) оформляется в отдельном файле в соответствии со «Стандартом на оформление технологических документов».
Группа процессов
Группы процессов введены для организации периодических перегрузок данных и указывают чёткую последовательность выполнения процессов внутри группы.
Стадии загрузки источника данных
В процессе загрузки, данные проходят следующие основные стадии, каждая из которых реализуется в виде отдельной фазы процесса перегрузки данных:
№НазваниеОбозначениеОписаниеПодпроцессы1ИзвлечениеIDCСтадия извлечения данных из источника и загрузки их в промежуточную область.• Download
• Structuring
• Refinement
• Transfer
• Upload2Выявление ошибокLOADSTERДанные проходят проверку на соответствие спецификациям и потенциальную возможность загрузки в ХД.• STER
• STAC3ПреобразованиеMLRCONVДанные группируются и приводятся к виду, конформному модели данных ХД.• STCF4РаспределениеMLRDISTRДанные распределяются на несколько потоков, в зависимости от способа, которым они должны быть загружены в ХД.• STIN
• STUP5ВставкаSQLLOADПодготовленные данные поступают в ХД.• INSERT
• UPDATE
• BACKUP1
• DELETE2
1 Операция резервирования BACKUP в основной массе проектов по созданию двухуровневых ХД не применяется. Требуется дальнейшее рассмотрение целесообразности введения этой операции вообще, так как она может быть заменена применением SCD уровня 2 и выше.
2 Операция удаления записей из ХД в общем случае не реализуется из-за отсутствия потребности в ней. Решение о её создании принимается каждый раз, если того требует техническое задание.
/* chevalry: ну вот по стадиям более-менее все расписано верно. Хотя условные обозначения стадий и подпроцессов - это уникальная "мулька" автора статьи :)
*/
Здесь я пытаюсь осмыслить первую часть статьи, посвященную структуре ETL-процесса...
Процесс
В общем случае, программист ETL может представлять себе архитектуру ХД в виде совокупности трёх областей: источник данных (совокупность таблиц оперативной системы и дополнительных справочников (классификаторов, таблиц согласования), позволяющую создать многомерную модель данных с требуемыми измерениями), промежуточная область (совокупность таблиц, использующихся исключительно как промежуточные при загрузке ХД) и приёмник данных. Движение данных от источника к приёмнику называют потоком данных. Необходимые потоки данных формирует и описывает аналитик.
Таблица 1: Основные стадии процесса загрузки данных
Процесс перегрузки данных - это реализация потока данных от единственного набора данных источника до одного или нескольких наборов данных ХД.
Различают следующие классы процессов:
1. По характеру загрузки:
a. Процесс начальной загрузки (Initial load)
b. Процесс обновляющей загрузки (Refreshing load)
/* chevalry: что имеется в виду? Вероятно то, что в промежуточной области могут существовать какие-то готовые шаблоны, конструкции, где могут происходить обновляющие загрузки из источника данных */
2. По виду источника данных:
a. SCF (источник данных - стандартный классификатор Datagy, чаще всего - структурированный текстовый файл)
b. UCF (источник данных - стандартный классификатор оперативной системы, пользовательский классификатор)
c. MLR (источник данных - RDS или таблица фактов оперативной системы)
d. DWH (источник данных - хранилище данных)
/* chevalry: тоже немного темное место. Разные бывают источники данных - начиная от плоской таблицы или текстового файла и кончая сложной, хорошой струкутурированной базой данных. Как это все классифицировать - не совсем понятно */
Процесс перегрузки данных включает в себя одну или несколько фаз, которые выполняются по очереди, в зависимости от типа фазы.
Фаза
Фаза процесса перегрузки данных (подпроцесс, обеспечивающий решение определённой задачи в рамках ETL-процесса) соответствует стадии загрузки источника данных, то есть количество используемых фаз ограничено стадиями, которые должен пройти набор данных источника, чтобы быть загруженным в ХД.
Фаза состоит из шагов и может включать операции управления выполнением перегрузки. Управление выполнением заключается в анализе количества записей в ключевых таблицах и флагов состояния, и реализуется с помощью языка скриптов утилиты SQLExecutor.
/* chevalry: на мой взгляд, фаза - это не только перегрузка данных (то бишь выгрузка и загрузка), но также и промежуточные фазы нормализации, очистки и преобразования данных.
*/
Шаг
Шаги представляют собой отдельные SQL-запросы, которые выполняют единичные действия по перегрузке, преобразованию и выборке данных.
Каждый запрос (равно как и скрипты фаз и процессов) оформляется в отдельном файле в соответствии со «Стандартом на оформление технологических документов».
Группа процессов
Группы процессов введены для организации периодических перегрузок данных и указывают чёткую последовательность выполнения процессов внутри группы.
Стадии загрузки источника данных
В процессе загрузки, данные проходят следующие основные стадии, каждая из которых реализуется в виде отдельной фазы процесса перегрузки данных:
№НазваниеОбозначениеОписаниеПодпроцессы1ИзвлечениеIDCСтадия извлечения данных из источника и загрузки их в промежуточную область.• Download
• Structuring
• Refinement
• Transfer
• Upload2Выявление ошибокLOADSTERДанные проходят проверку на соответствие спецификациям и потенциальную возможность загрузки в ХД.• STER
• STAC3ПреобразованиеMLRCONVДанные группируются и приводятся к виду, конформному модели данных ХД.• STCF4РаспределениеMLRDISTRДанные распределяются на несколько потоков, в зависимости от способа, которым они должны быть загружены в ХД.• STIN
• STUP5ВставкаSQLLOADПодготовленные данные поступают в ХД.• INSERT
• UPDATE
• BACKUP1
• DELETE2
1 Операция резервирования BACKUP в основной массе проектов по созданию двухуровневых ХД не применяется. Требуется дальнейшее рассмотрение целесообразности введения этой операции вообще, так как она может быть заменена применением SCD уровня 2 и выше.
2 Операция удаления записей из ХД в общем случае не реализуется из-за отсутствия потребности в ней. Решение о её создании принимается каждый раз, если того требует техническое задание.
/* chevalry: ну вот по стадиям более-менее все расписано верно. Хотя условные обозначения стадий и подпроцессов - это уникальная "мулька" автора статьи :)
*/